Download presentation
Presentation is loading. Please wait.

1
Finding Topic-sensitive Influential Twitterers Presenter 吴伟涛 TwitterRank:

2
Outline 1. Introduction 2. Dataset 3. Topic modeling and Homophily in Twitter 4. TwitterRank 5. Experiment and results 6. Conclusions

3
Introduction Motivation The number of followers is the main metric to identify influential twitterers. Twitterer’s influence may vary with different topics. Solution Identify influential twitterers taking both the topical similarity between users and the link structure into account.

4
Introduction Two contributions of this paper: 1. First to report homophily in Twitter 2. Introduce TwitterRank to measure the topic-sensitive influence of the twitterers.

5
Introduction Topic Distillation Topic-specific Relationship Network Construction Topic-sensitive User Influenc Ranking Framework of the Proposed Approach

6
Outline Introduction Dataset Topic modeling and Homophily in Twitter TwitterRank Experiment and results Conclusions

7
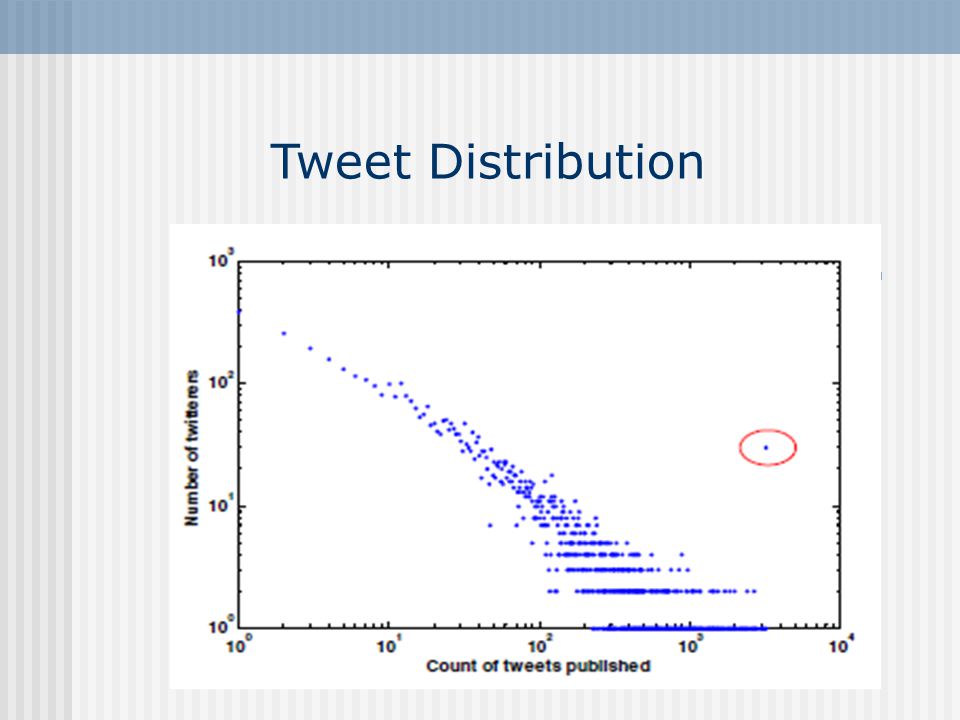
Twitter Dataset 1.Obtain a set of top-1000 Singapore-based twitterers. Denote the set as S, |S|=996. 2.Crawled all the followers and the friends of each s ∈ S and stored them in set S’. 3.Let S’’= S ∪ S’, and S* = {s|s ∈ S’’, and s is from Singapore}.|S*| = 6748. For each s ∈ S*, crawled all the tweets she had published so far. Denote it as T. |T|=1,021,039.

8
Tweet Distribution

10
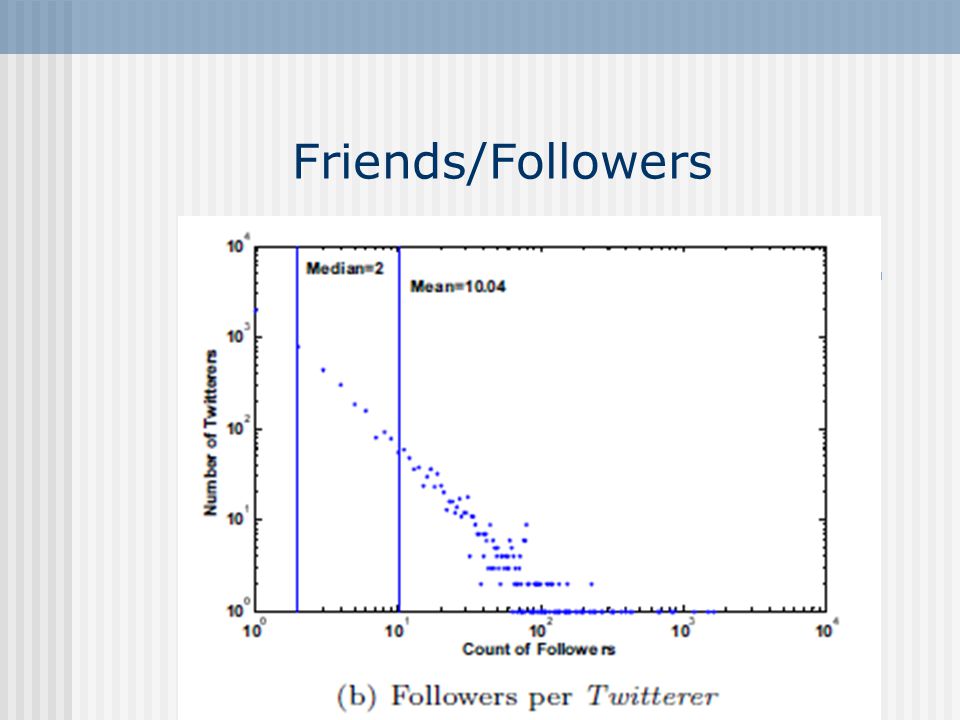
Friends/Followers

12
Reciprocity in Following Relationships

13
72.4% of the twitterers follow more than 80% of their followers 80.5% of the twitterers have 80% of their friends follow them back Casual following or homophily?

14
Outline Introduction Dataset Topic modeling and Homophily in Twitter TwitterRank Experiment and results Conclusions

15
Homophily in Twitter Q1: Are twitterers with “following” relationships more similar than those without according to the topics they are interested in? Q2: Are twitterers with reciprocal “following” relationships more similar than those without according to the topics they are interested in?

16
Topic modeling 定义距离: Dist(i,j) 计算平均距离 验证: ? 验证: ? 计算平均距离 结论: homophily
 计算平均距离 验证: 验证: 计算平均距离 结论: homophily")
17
Topic Modeling Goal: Automatically identify the topics that twitterers are interested in based on the tweets they published. Latent Dirichlet Allocation (LDA) model is applied
 model is applied.")
18
Topic Modeling LDA-based generative process for generating a doc: 1.For each document, pick a topic from its distribution over topic, 2.Sample a word from the distribution over the words associated with the chosen topic. 3.The process is repeated for all the words in the document.

19
Topic Modeling Results 1.DT — D×T matrix D: the number of users T: the number of topics DT ij : the number of times a word in user s i ’s tweets has been assigned to topic t j.

20
Topic Modeling we first row normalize the DT matrix as DT’ such that ||DT’ i · || 1 =1 for each row DT’ i ·. Thus each row of matrix DT’ is basically the probability distribution of twitterer s i ’s interest over the T topics, i.e. each element DT’ i j captures the probability that twitterer s i is interested in topic t j.

21
Topic Difference Definition 1: the topical difference between two twitterers s i and s j can be calculated as: D JS (i,j) is the Jensen-Shannon Divergence between the two probability distributions DT’ i · and DT’ j · which is defined as:
 is the Jensen-Shannon Divergence between the two probability distributions DT’ i · and DT’ j · which is defined as:")
22
Topic Difference M is the average of the two probability distibutions, i.e. D KL is the Kullback-Leibler Divergence which defines the divergence from distribution Q to P as:

23
Hypothesis Testing * Note that, this part of work, hypothesis testing, and topic distillation as well, is applied on a set of twitterers who publish more than 10 tweets in total. We denote this set as, and | | = 4050.

24
Hypothesis Testing (I) Formalize Q1 as a two-sample t-tet: : the mean topical difference of the pairs of users with “following” relationship. : the mea topical difference of those without.

25
Hypothesis Testing (I) Result: The null-hypothesis H 0 is rejected at significant level.
 Result: The null-hypothesis H 0 is rejected at significant level.")
26
Hypothesis Testing (II) Formalize Q2 as a two-sample t-tet: : the mean topical difference of the pairs of users with reciprocal following relationship. : the mea topical difference of pairs of users with only one-direction relationship.

27
Hypothesis Testing (II) Result: The null-hypothesis H 0 is rejected at significant level.
 Result: The null-hypothesis H 0 is rejected at significant level.")
28
Implication Homophily phenomenon does exist: -The answer to Q1 is yes. -The answer to Q2 is also yes. -There are twitterers who are serious in following others.

29
Outline Introduction Dataset Topic modeling and Homophily in Twitter TwitterRank Experiment and results Conclusions

30
Topic-specific TwitterRank A topic-specific random walk model is applied to calculate the user’s influential score. The transition matrix for topic t, denoted as P t. The transition probability of surfer from follower s i to friend s j is:

31
Topic-specific TwitterRank Topic-specific teleportation: The influence scores of twitters are calculated iteratively: Aggregation of topic-specific TwitterRank:

32
Outline Introduction Dataset Topic modeling and Homophily in Twitter TwitterRank Experiment and results Conclusions

33
Comparison with other Algorithms Comparison to: In-degree PageRank Topic-sensitive PageRank Comparison in recommendation scenario.

34
Recommendation task

35
StSt s0s0 sfsf L

36
Evaluation Assume A is a ranked list recommended by any of the algorithms. Let A(s i ) to be the rank of si in A. The quality of the recommendation Q(A) is measured as Q(A)=|{s i |s i ∈ S t, and A(s i )<A(s f )}|. The lower the value of Q(A) is, the higher the quality of corresponding algorithm is.
 to be the rank of si in A. The quality of the recommendation Q(A) is measured as Q(A)=|{s i |s i ∈ S t, and A(s i )<A(s f )}|. The lower the value of Q(A) is, the higher the quality of corresponding algorithm is..")
37
Criteria to generate L set The number of followers that s f has. The number of tweets that s f published. Topical difference between s 0 and s f. Whether reciprocal relationship between s 0 and s f.

38
Experiment Results

39
All performs better in L df than in L dh : - There are twitterers who “follow” because of the topical similarity between them and their friends. This support the homophily phenomenon. TR is outperformed in L fh, L tl and L dh: - InD perform the best in L fh. This is because twitterers “following” benaviors have already been biased toward those with more followers.

40
Experiment Results - TR performs the worst in L tl, because LDA-based topic distillation needs more contents to achieve reasonable accuracy. - TR outperforms all the other algorithms except InD in L dh. There still exist some twitters who do not “follow” based on topical similarity, although homophily is observed.

41
Outline Introduction Dataset Topic modeling and Homophily in Twitter TwitterRank Experiment and results Conclusions

42
Conclusion and future work Homophily does exist: - Not all users just randomly “follows”. Future work: - To make the algorithm more robust to manipulation, e.g purposely publish large number of tweets. - To classify different categories of users by studying their following behaviors more closely. - Incremental topic distillation/ event detection.

43
Thank you

Similar presentations














 Presented by Anson Liang.>")




