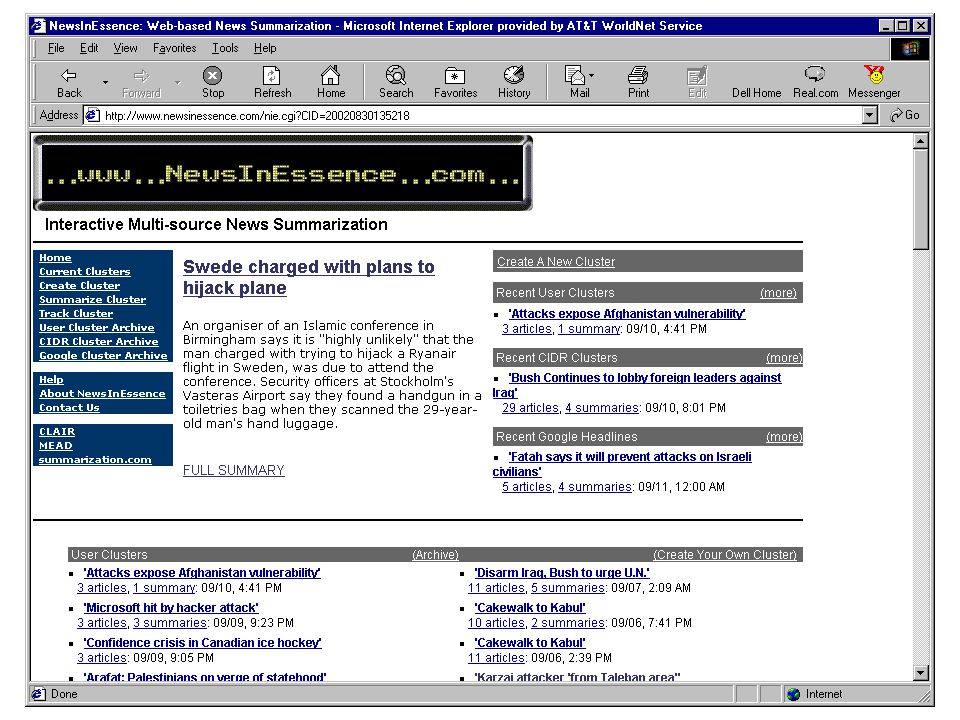
Download presentation
Presentation is loading. Please wait.

1
Automatic summarization Dragomir R. Radev University of Michigan radev@umich.edu

2
Outline What is summarization Genres of summarization (Single-doc, Multi- doc, Query-based, etc.) Extractive vs. non-extractive summarization Evaluation metrics Current systems –Marcu/Knight –MEAD/Lemur –NewsInEssence/NewsBlaster What is possible and what is not

3
Goal of summarization Preserve the “most important information” in a document. Make use of redundancy in text Maximize information density Compression Ratio = |S| |D| Retention Ratio = i (S) i (D) Goal: i (S) i (D) |S| |D| >
 i (D) Goal: i (S) i (D) |S| |D| >.")
4
Sentence-extraction based (SE) summarization Classification problem Approximation
 summarization Classification problem Approximation")
5
Typical approaches to SE summarization Manually-selected features: position, overlap with query, cue words, structure information, overlap with centroid Reranking: maximal marginal relevance [Carbonell/Goldstein98]
![Typical approaches to SE summarization Manually-selected features: position, overlap with query, cue words, structure information, overlap with centroid Reranking: maximal marginal relevance [Carbonell/Goldstein98]](http://images.slideplayer.com/12/3361281/slides/slide_5.jpg "Typical approaches to SE summarization Manually-selected features: position, overlap with query, cue words, structure information, overlap with centroid Reranking: maximal marginal relevance [Carbonell/Goldstein98]")
6
Non-SE summarization Discourse-based [Marcu97] Lexical chains [Barzilay&Elhadad97] Template-based [Radev&McKeown98]
![Non-SE summarization Discourse-based [Marcu97] Lexical chains [Barzilay&Elhadad97] Template-based [Radev&McKeown98]](http://images.slideplayer.com/12/3361281/slides/slide_6.jpg "Non-SE summarization Discourse-based [Marcu97] Lexical chains [Barzilay&Elhadad97] Template-based [Radev&McKeown98]")
7
Evaluation metrics Intrinsic measures –Precision, recall –Kappa –Relative utility [Radev&al.00] –Similarity measures (cosine, overlap, BLEU) Extrinsic measures –Classification accuracy –Informativeness for question answering –Relevance correlation
![Evaluation metrics Intrinsic measures –Precision, recall –Kappa –Relative utility [Radev&al.00] –Similarity measures (cosine, overlap, BLEU) Extrinsic measures –Classification accuracy –Informativeness for question answering –Relevance correlation](http://images.slideplayer.com/12/3361281/slides/slide_7.jpg "Evaluation metrics Intrinsic measures –Precision, recall –Kappa –Relative utility [Radev&al.00] –Similarity measures (cosine, overlap, BLEU) Extrinsic measures –Classification accuracy –Informativeness for question answering –Relevance correlation")
8
Precision and recall Precision(J1)= Recall(J2)= Recall(J1)= Precision(J2)=
= Recall(J2)= Recall(J1)= Precision(J2)=")
9
Kappa N: number of items (index i) n: number of categories (index j) k: number of annotators
 n: number of categories (index j) k: number of annotators")
10
Cosine Overlap Similarity measures

11
Relevance correlation (RC)
")
12
Properties of evaluation metrics

13
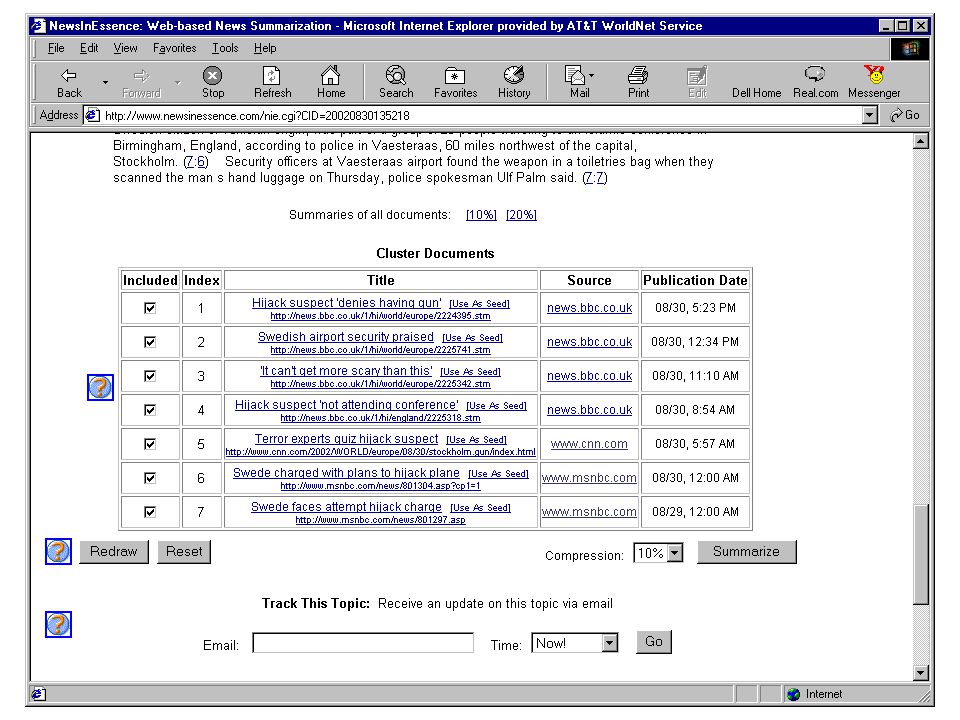
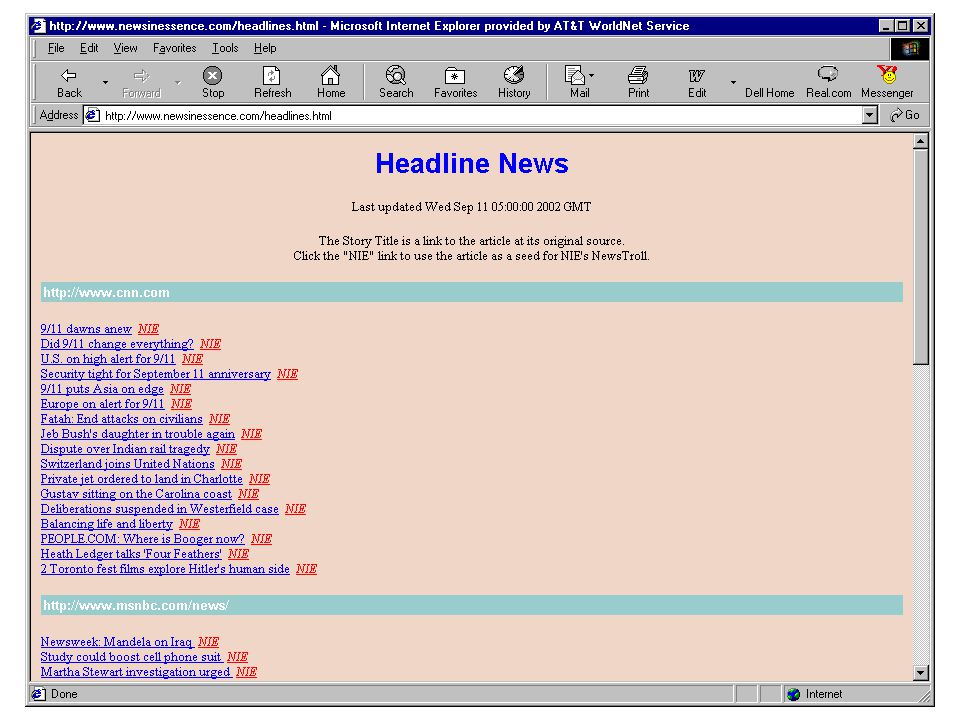
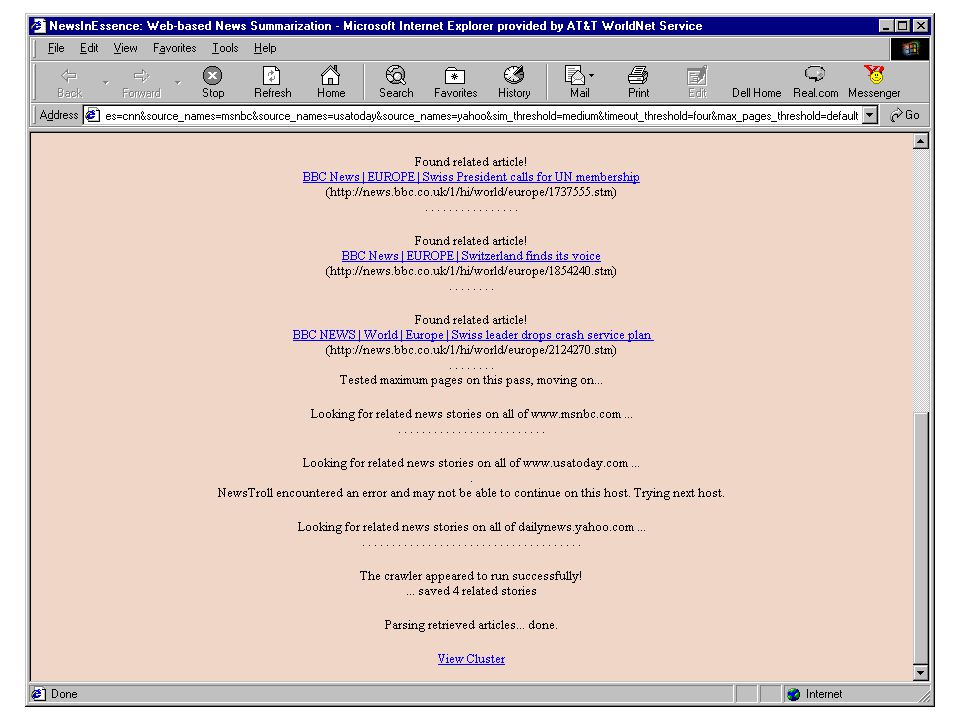
Case study Multi-document News User-centered NewsInEssence [HLT 01] NewsBlaster [HLT02]
![Case study Multi-document News User-centered NewsInEssence [HLT 01] NewsBlaster [HLT02]](http://images.slideplayer.com/12/3361281/slides/slide_13.jpg "Case study Multi-document News User-centered NewsInEssence [HLT 01] NewsBlaster [HLT02]")
24
Web resources http://www.summarization.com http://duc.nist.gov http://www.newsinessence.com http://www.clsp.jhu.edu/ws2001/groups/asmd/ http://www.cs.columbia.edu/~jing/summarization.html http://www.dcs.shef.ac.uk/~gael/alphalist.html http://www.csi.uottawa.ca/tanka/ts.html http://www.ics.mq.edu.au/~swan/summarization/

25
Generative probabilistic models for summarization Wessel Kraaij TNO TPD

26
Summarization architecture What do human summarizers do? –A: Start from scratch: analyze, transform, synthesize (top down) –B: Select material and revise: “cut and paste summarization” (Jing & McKeown-1999) Automatic systems: –Extraction: selection of material –Revision: reduction, combination, syntactic transformation, paraphrasing, generalization, sentence reordering complexity Extracts Abstracts
 –B: Select material and revise: cut and paste summarization (Jing & McKeown-1999) Automatic systems: –Extraction: selection of material –Revision: reduction, combination, syntactic transformation, paraphrasing, generalization, sentence reordering complexity Extracts Abstracts.")
27
Required knowledge

28
Examples of generative models in summarization systems Sentence selection Sentence / document reduction Headline generation

29
Ex. 1: Sentence selection Conroy et al (DUC 2001): HMM on sentence level, each state has an associated feature vector (pos,len, #content terms) Compute probability of being a summary sentence Kraaij et al (DUC 2001) Rank sentences according to posterior probability given a mixture model +Grammaticality is OK –Lacks aggregation, generalization, MDS
: HMM on sentence level, each state has an associated feature vector (pos,len, #content terms) Compute probability of being a summary sentence Kraaij et al (DUC 2001) Rank sentences according to posterior probability given a mixture model +Grammaticality is OK –Lacks aggregation, generalization, MDS.")
30
Ex. 2: Sentence reduction

31
Knight & Marcu (AAAI2000) Compression: delete substrings in an informed way (based on parse tree) –Required: PCFG parser, tree aligned training corpus –Channel model: probabilistic model for expansion of a parse tree –Results: much better than NP baseline +Tight control on grammaticality +Mimics revision operations by humans
 Compression: delete substrings in an informed way (based on parse tree) –Required: PCFG parser, tree aligned training corpus –Channel model: probabilistic model for expansion of a parse tree –Results: much better than NP baseline +Tight control on grammaticality +Mimics revision operations by humans")
32
Daumé & Marcu (ACL2002) Document compression, noisy channel –Based on syntactic structure and discourse structure (extension of Knight & Marcu model) –Required: Discourse & syntactic parsers –Training corpus where EDU’s in summaries are aligned with the documents –Cannot handle interesting document lengths (due to complexity)
 Document compression, noisy channel –Based on syntactic structure and discourse structure (extension of Knight & Marcu model) –Required: Discourse & syntactic parsers –Training corpus where EDU’s in summaries are aligned with the documents –Cannot handle interesting document lengths (due to complexity)")
33
Ex. 3: Headline generation

34
Berger & Mittal (sigir2000) Input: web pages (often not running text) –Trigram language model –IBM model 1 like channel model: Choose length, draw word from source model and replace with similar word, independence assumption – Trained on Open Directory +Non-extractive –Grammaticality and coherence are disappointing: indicative
 Input: web pages (often not running text) –Trigram language model –IBM model 1 like channel model: Choose length, draw word from source model and replace with similar word, independence assumption – Trained on Open Directory +Non-extractive –Grammaticality and coherence are disappointing: indicative")
35
Zajic, Dorr & Schwartz (duc2002) Headline generation from a full story: P(S|H)P(H) Channel model based on HMM consisting of a bigram model of headline words and a unigram model of story words, bigram language model Decoding parameters are crucial to produce good results (length, position, strings) +Good results in fluency and accuracy
 Headline generation from a full story: P(S|H)P(H) Channel model based on HMM consisting of a bigram model of headline words and a unigram model of story words, bigram language model Decoding parameters are crucial to produce good results (length, position, strings) +Good results in fluency and accuracy")
36
Conclusions Fluent headlines within reach of simple generative models High quality summaries (coverage, grammaticality, coherence) require higher level symbolic representations Cut & paste metaphor divides the work into manageable sub-problems Noisy channel method effective, but not always efficient
 require higher level symbolic representations Cut & paste metaphor divides the work into manageable sub-problems Noisy channel method effective, but not always efficient")
37
Open issues Audience (user model) Types of source documents Dealing with redundancy Information ordering (e.g., temporal) Coherent text Cross-lingual summarization (Norbert Fuhr) Use summaries to improve IR (or CLIR) - relevance correlation LM for text generation Possibly not well-defined problem (low interjudge agreement) Develop models with more linguistic structure Develop integrated models, e.g. by using priors (Rosenfeld) Build efficient implementations Evaluation: Define a manageable task
 Build efficient implementations Evaluation: Define a manageable task.")
Similar presentations














. Programming Language Lexical and Syntactic features of a programming Language are specified by its grammar Language:->")







 Slides prepared by Jon Elsas for the.>")


