Download presentation
Presentation is loading. Please wait.

1
Introductions to Parallel Programming Using OpenMP
April 7, 2005 Zhenying Liu, Dr. Barbara Chapman High Performance Computing and Tools group Computer Science Department University of Houston

2
Content Overview of OpenMP Acknowledgement
OpenMP constructs (5 categories) OpenMP exercises References
 OpenMP exercises. References.")
3
Overview of OpenMP OpenMP is a set of extensions to Fortran/C/C++
OpenMP contains compiler directives, library routines and environment variables. Available on most single address space machines. shared memory systems, including cc-NUMA Chip MultiThreading: Chip MultiProcessing (Sun UltraSPARC IV), Simultaneous Multithreading (Intel Xeon) not on distributed memory systems, classic MPPs, or PC clusters (yet!) Give some examples
, Simultaneous Multithreading (Intel Xeon) not on distributed memory systems, classic MPPs, or PC clusters (yet!) Give some examples.")
4
Shared Memory Architecture
All processors have access to one global memory All processors share the same address space The system runs a single copy of the OS Processors communicate by reading/writing to the global memory Examples: multiprocessor PCs (Intel P4), Sun Fire 15K, NEC SX-7, Fujitsu PrimePower, IBM p690, SGI Origin 3000.
, Sun Fire 15K, NEC SX-7, Fujitsu PrimePower, IBM p690, SGI Origin")
5
Shared Memory Systems (cont)
OpenMP Pthreads

6
Distributed Memory Systems
Processor M Interconnect ••••••••••••• MPI HPF

7
Clustered of SMPs MPI hybrid MPI + OpenMP

8
OpenMP Usage Applications Programmer Accessibility
Applications with intense computational needs From video games to big science & engineering Programmer Accessibility From very early programmers in school to scientists to parallel computing experts Available to millions of programmers In every major (Fortran & C/C++) compiler
 compiler.")
9
OpenMP Syntax Most of the constructs in OpenMP are compiler directives or pragmas. For C and C++, the pragmas take the form: #pragma omp construct [clause [clause]…] For Fortran, the directives take one of the forms: C$OMP construct [clause [clause]…] !$OMP construct [clause [clause]…] *$OMP construct [clause [clause]…] Since the constructs are directives, an OpenMP program can be compiled by compilers that don’t support OpenMP.

10
OpenMP: Programming Model
Fork-Join Parallelism: Master thread spawns a team of threads as needed. Parallelism is added incrementally: i.e. the sequential program evolves into a parallel program.

11
OpenMP: How is OpenMP Typically Used?
OpenMP is usually used to parallelize loops: Find your most time consuming loops. Split them up between threads. Split-up this loop between multiple threads void main() { double Res[1000]; for(int i=0;i<1000;i++) { do_huge_comp(Res[i]); } void main() { double Res[1000]; #pragma omp parallel for for(int i=0;i<1000;i++) { do_huge_comp(Res[i]); } Sequential program Parallel program
 { double Res[1000]; for(int i=0;i<1000;i++) { do_huge_comp(Res[i]); } void main() { double Res[1000]; #pragma omp parallel for. for(int i=0;i<1000;i++) { do_huge_comp(Res[i]); } Sequential program. Parallel program.")
12
OpenMP: How do Threads Interact?
OpenMP is a shared memory model. Threads communicate by sharing variables. Unintended sharing of data can lead to race conditions: race condition: when the program’s outcome changes as the threads are scheduled differently. To control race conditions: Use synchronization to protect data conflicts. Synchronization is expensive so: Change how data is stored to minimize the need for synchronization.

13
OpenMP vs. POSIX Threads
POSIX threads is the other widely used shared programming API. Fairly widely available, usually quite simple to implement on top of OS kernel threads. Lower level of abstraction than OpenMP library routines only, no directives more flexible, but harder to implement and maintain OpenMP can be implemented on top of POSIX threads Not much difference in availability not that many OpenMP C++ implementations no standard Fortran interface for POSIX threads

14
Content Overview of OpenMP Acknowledgement
OpenMP constructs (5 categories) OpenMP exercises References
 OpenMP exercises. References.")
15
Acknowledgement Slides provided by OpenMP program examples
Tim Mattson and Rudolf Eigenmann, SC ’99 Mark Bull from EPCC OpenMP program examples Lawrence Livermore National Lab NAS FT parallelization from PGI tutorial Dr. Garbey provided us serial codes of Naiver-Stokes

16
Content Overview of OpenMP Acknowledgement
OpenMP constructs (5 categories) OpenMP exercises References
 OpenMP exercises. References.")
17
OpenMP Constructs OpenMP’s constructs fall into 5 categories:
Parallel Regions Worksharing Data Environment Synchronization Runtime functions/environment variables OpenMP is basically the same between Fortran and C/C++

18
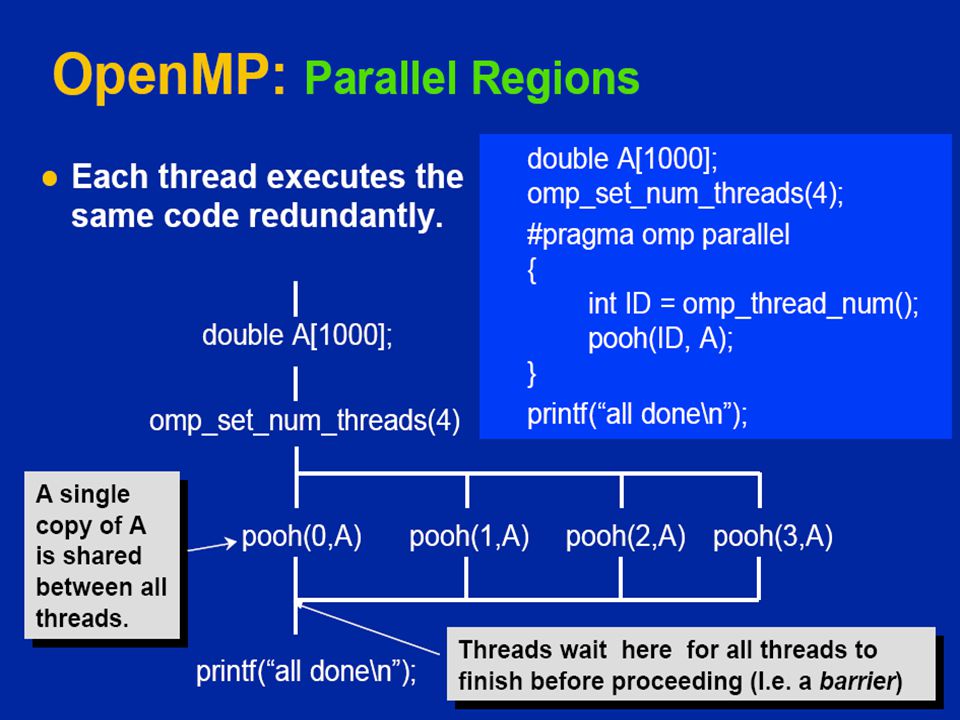
OpenMP: Parallel Regions
You create threads in OpenMP with the “omp parallel” pragma. For example, To create a 4-thread Parallel region: Each thread calls pooh(ID,A) for ID = 0 to 3 double A[1000]; omp_set_num_threads(4); #pragma omp parallel { int ID =omp_get_thread_num(); pooh(ID,A); } Each thread redundantly executes the code within the structured block
 for ID = 0 to 3. double A[1000]; omp_set_num_threads(4); #pragma omp parallel. { int ID =omp_get_thread_num(); pooh(ID,A); } Each thread redundantly executes the code within the structured block.")
20
OpenMP: Work-Sharing Constructs
The “for” Work-Sharing construct splits up loop iterations among the threads in a team #pragma omp parallel #pragma omp for for (I=0;I<N;I++){ NEAT_STUFF(I); } By default, there is a barrier at the end of the “omp for”. Use the “nowait” clause to turn off the barrier.
{ NEAT_STUFF(I); } By default, there is a barrier at the end of. the omp for . Use the nowait clause to. turn off the barrier.")
21
Work Sharing Constructs A motivating example
Sequential code for(i=0;I<N;i++) { a[i] = a[i] + b[i];} #pragma omp parallel { int id, i, Nthrds, istart, iend; id = omp_get_thread_num(); Nthrds = omp_get_num_threads(); istart = id * N / Nthrds; iend = (id+1) * N / Nthrds; for(i=istart;I<iend;i++) {a[i]=a[i]+b[i];} } OpenMP Parallel Region OpenMP Parallel Region and a work-sharing for construct #pragma omp parallel #pragma omp for schedule(static) for(i=0;I<N;i++) { a[i]=a[i]+b[i];} OpenMP parallel region and a work-sharing for construct
 { a[i] = a[i] + b[i];} #pragma omp parallel. { int id, i, Nthrds, istart, iend; id = omp_get_thread_num(); Nthrds = omp_get_num_threads(); istart = id * N / Nthrds; iend = (id+1) * N / Nthrds; for(i=istart;I<iend;i++) {a[i]=a[i]+b[i];} } OpenMP Parallel Region. OpenMP Parallel Region and a work-sharing for construct. #pragma omp parallel. #pragma omp for schedule(static) for(i=0;I<N;i++) { a[i]=a[i]+b[i];} OpenMP parallel region and a work-sharing for construct.")
22
OpenMP For Construct: The Schedule Clause
The schedule clause effects how loop iterations are mapped onto threads uschedule(static [,chunk]) Deal-out blocks of iterations of size “chunk” to each thread. uschedule(dynamic[,chunk]) Each thread grabs “chunk” iterations off a queue until all iterations have been handled. uschedule(guided[,chunk]) Threads dynamically grab blocks of iterations. The size of the block starts large and shrinks down to size “chunk” as the calculation proceeds. uschedule(runtime) Schedule and chunk size taken from the OMP_SCHEDULE environment variable.
 Deal-out blocks of iterations of size chunk to each thread. uschedule(dynamic[,chunk]) Each thread grabs chunk iterations off a queue until all iterations have been handled. uschedule(guided[,chunk]) Threads dynamically grab blocks of iterations. The size of the block starts large and shrinks down to size chunk as the calculation proceeds. uschedule(runtime) Schedule and chunk size taken from the OMP_SCHEDULE environment variable.")
23
OpenMP: Work-Sharing Constructs
The Sections work-sharing construct gives a different structured block to each thread. #pragma omp parallel #pragma omp sections { X_calculation(); #pragma omp section y_calculation(); z_calculation(); } By default, there is a barrier at the end of the “omp sections”. Use the “nowait” clause to turn off the barrier.
; #pragma omp section. y_calculation(); z_calculation(); } By default, there is a barrier at the end of the omp sections . Use the nowait clause to turn off the barrier.")
24
Data Environment: Changing Storage Attributes
One can selectively change storage attributes constructs using the following clauses* SHARED PRIVATE FIRSTPRIVATE THREADPRIVATE The value of a private inside a parallel loop can be transmitted to a global value outside the loop with: LASTPRIVATE The default status can be modified with: DEFAULT (PRIVATE | SHARED | NONE) * All data clauses apply to parallel regions and worksharing constructs except “shared” which only applies to parallel regions.
 * All data clauses apply to parallel regions and worksharing constructs except shared which only applies to parallel regions.")
25
Data Environment: Default Storage Attributes
Shared Memory programming model: Most variables are shared by default Global variables are SHARED among threads Fortran: COMMON blocks, SAVE variables, MODULE variables C: File scope variables, static But not everything is shared... Stack variables in sub-programs called from parallel regions are PRIVATE Automatic variables within a statement block are PRIVATE.

26
Private Clause private(var) creates a local copy of var for each thread. – The value is uninitialized – Private copy is not storage associated with the original void wrong(){ int IS = 0; #pragma parallel for private(IS) for(int J=1;J<1000;J++) IS = IS + J; printf(“%i”, IS); }
{ int IS = 0; #pragma parallel for private(IS) for(int J=1;J<1000;J++) IS = IS + J; printf( %i , IS); }")
27
OpenMP: Reduction Another clause that effects the way variables are shared: reduction (op : list) The variables in “list” must be shared in the enclosing parallel region. Inside a parallel or a worksharing construct: A local copy of each list variable is made and initialized depending on the “op” (e.g. 0 for “+”) pair wise “op” is updated on the local value Local copies are reduced into a single global copy at the end of the construct.
 pair wise op is updated on the local value. Local copies are reduced into a single global copy at the end of the construct.")
28
OpenMP: An Reduction Example
#include <omp.h> #define NUM_THREADS 2 void main () { int i; double ZZ, func(), sum=0.0; omp_set_num_threads(NUM_THREADS) #pragma omp parallel for reduction(+:sum) private(ZZ) for (i=0; i< 1000; i++){ ZZ = func(i); sum = sum + ZZ; }
 { int i; double ZZ, func(), sum=0.0; omp_set_num_threads(NUM_THREADS) #pragma omp parallel for reduction(+:sum) private(ZZ) for (i=0; i< 1000; i++){ ZZ = func(i); sum = sum + ZZ; }")
29
OpenMP: Synchronization
OpenMP has the following constructs to support synchronization: barrier critical section atomic flush ordered single master

31
Critical and Atomic Only one thread at a time can enter a critical section C$OMP PARALLEL DO PRIVATE(B) C$OMP& SHARED(RES) DO 100 I=1,NITERS B = DOIT(I) C$OMP CRITICAL CALL CONSUME (B, RES) C$OMP END CRITICAL 100 CONTINUE Atomic is a special case of a critical section that can be used for certain simple statements: C$OMP PARALLEL PRIVATE(B) B = DOIT(I) C$OMP ATOMIC X = X + B C$OMP END PARALLEL
 DO 100 I=1,NITERS. B = DOIT(I) C$OMP CRITICAL. CALL CONSUME (B, RES) C$OMP END CRITICAL. 100 CONTINUE. Atomic is a special case of a critical section that can be used for certain simple statements: C$OMP PARALLEL PRIVATE(B) B = DOIT(I) C$OMP ATOMIC. X = X + B. C$OMP END PARALLEL.")
32
Master directive The master construct denotes a structured block that is only executed by the master thread. The other threads just skip it (no implied barriers or flushes). #pragma omp parallel private (tmp) { do_many_things(); #pragma omp master { exchange_boundaries(); } #pragma barrier do_many_other_things(); }
. #pragma omp parallel private (tmp) { do_many_things(); #pragma omp master. { exchange_boundaries(); } #pragma barrier. do_many_other_things(); }")
33
Single directive The single construct denotes a block of code that is executed by only one thread. A barrier and a flush are implied at the end of the single block. #pragma omp parallel private (tmp) { do_many_things(); #pragma omp single { exchange_boundaries(); } do_many_other_things(); }
 { do_many_things(); #pragma omp single. { exchange_boundaries(); } do_many_other_things(); }")
34
OpenMP: Library routines
Lock routines omp_init_lock(), omp_set_lock(), omp_unset_lock(), omp_test_lock() Runtime environment routines: Modify/Check the number of threads omp_set_num_threads(), omp_get_num_threads(), omp_get_thread_num(), omp_get_max_threads() Turn on/off nesting and dynamic mode omp_set_nested(), omp_set_dynamic(), omp_get_nested(), omp_get_dynamic() Are we in a parallel region? omp_in_parallel() How many processors in the system? omp_num_procs()
, omp_set_lock(), omp_unset_lock(), omp_test_lock() Runtime environment routines: Modify/Check the number of threads. omp_set_num_threads(), omp_get_num_threads(), omp_get_thread_num(), omp_get_max_threads() Turn on/off nesting and dynamic mode. omp_set_nested(), omp_set_dynamic(), omp_get_nested(), omp_get_dynamic() Are we in a parallel region omp_in_parallel() How many processors in the system omp_num_procs()")
35
OpenMP: Environment Variables
OMP_NUM_THREADS bsh: export OMP_NUM_THREADS=2 csh: setenv OMP_NUM_THREADS 4

36
Content Overview of OpenMP Acknowledgement
OpenMP constructs (5 categories) OpenMP exercises References
 OpenMP exercises. References.")
37
1. Hello World! #include <omp.h> main () { int nthreads, tid;
/* Fork a team of threads giving them their own copies of variables */ #pragma omp parallel private(nthreads, tid) { /* Obtain thread number */ tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); /* Only master thread does this */ if (tid == 0) nthreads = omp_get_num_threads(); printf("Number of threads = %d\n", nthreads); } } /* All threads join master thread and disband */
 { /* Obtain thread number */ tid = omp_get_thread_num(); printf( Hello World from thread = %d\n , tid); /* Only master thread does this */ if (tid == 0) nthreads = omp_get_num_threads(); printf( Number of threads = %d\n , nthreads); } } /* All threads join master thread and disband */")
38
Example Code - Pthread Creation and Termination
#include <pthread.h> #include <stdio.h> #define NUM_THREADS 5 void *PrintHello(void *threadid) { printf("\n%d: Hello World!\n", threadid); pthread_exit(NULL); } int main (int argc, char *argv[]) { pthread_t threads[NUM_THREADS]; int rc, t; for(t=0; t<NUM_THREADS; t++) { printf("Creating thread %d\n", t); rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t); if (rc) { printf("ERROR; return code from pthread_create() is %d\n", rc); exit(-1); } pthread_exit(NULL);
 { printf( \n%d: Hello World!\n , threadid); pthread_exit(NULL); } int main (int argc, char *argv[]) { pthread_t threads[NUM_THREADS]; int rc, t; for(t=0; t<NUM_THREADS; t++) { printf( Creating thread %d\n , t); rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t); if (rc) { printf( ERROR; return code from pthread_create() is %d\n , rc); exit(-1); } pthread_exit(NULL);")
39
2. Parallel Loop Reduction
PROGRAM REDUCTION INTEGER I, N REAL A(100), B(100), SUM ! Some initializations N = 100 DO I = 1, N A(I) = I *1.0 B(I) = A(I) ENDDO SUM = 0.0 !$OMP PARALLEL DO REDUCTION(+:SUM) SUM = SUM + (A(I) * B(I)) PRINT *, ' Sum = ', SUM END
, B(100), SUM. ! Some initializations. N = 100. DO I = 1, N. A(I) = I *1.0. B(I) = A(I) ENDDO. SUM = 0.0. !$OMP PARALLEL DO REDUCTION(+:SUM) SUM = SUM + (A(I) * B(I)) PRINT *, Sum = , SUM. END.")
40
3. Matrix-vector multiply using a parallel loop and critical directive
/*** Spawn a parallel region explicitly scoping all variables ***/ #pragma omp parallel shared(a,b,c,nthreads,chunk) private(tid,i,j,k) { #pragma omp for schedule (static, chunk) for (i=0; i<NRA; i++) printf("thread=%d did row=%d\n",tid,i); for(j=0; j<NCB; j++) for (k=0; k<NCA; k++) c[i][j] += a[i][k] * b[k][j]; }
 private(tid,i,j,k) { #pragma omp for schedule (static, chunk) for (i=0; i<NRA; i++) printf( thread=%d did row=%d\n ,tid,i); for(j=0; j<NCB; j++) for (k=0; k<NCA; k++) c[i][j] += a[i][k] * b[k][j]; }")
41
Steps of Parallelization using OpenMP: An Example from a PGI Tutorial
Compile a code with the option to enable a profiler Run the code and check if the results are correct Find out the most time-consuming part of the code via the profiler information Parallelize the time-consuming part Repeat above steps until you get reasonable speedup

42
How to Use a Profiler PGI compiler Pathscale compiler
pgf90 -fast -Minfo -Mprof=func fftpde.F -o fftpde (function level) -Mprof=lines (line level) -mp for compiling OpenMP codes pgprof pgprof.out (show the profiler result) Pathscale compiler pathf90 -Ofast -pg Fftpde.F -o Fftpde pathprof Fftpde|more
 -Mprof=lines (line level) -mp for compiling OpenMP codes. pgprof pgprof.out (show the profiler result) Pathscale compiler. pathf90 -Ofast -pg Fftpde.F -o Fftpde. pathprof Fftpde|more.")
43
The most time-consuming loop in Fftpde.F:
The OpenMP version of this loop in Fftpde_1.F: !$OMP PARALLEL PRIVATE(Z) !$OMP DO do k=1,n3 do j=1,n2 do i=1,n1 z(i)=cmplx(x1real(i,j,k),x1imag(i,j,k)) end do call fft(z,inverse,w,n1,m1) x1real(i,j,k)=real(z(i)) x1imag(i,j,k)=aimag(z(i)) !$OMP END PARALLEL do k=1,n3 do j=1,n2 do i=1,n1 z(i)=cmplx(x1real(i,j,k),x1imag(i,j,k)) end do call fft(z,inverse,w,n1,m1) x1real(i,j,k)=real(z(i)) x1imag(i,j,k)=aimag(z(i)) NEXT: compare the 1 and 2 processor profiles after adding OpenMP to this loop
 !$OMP DO. do k=1,n3. do j=1,n2. do i=1,n1. z(i)=cmplx(x1real(i,j,k),x1imag(i,j,k)) end do. call fft(z,inverse,w,n1,m1) x1real(i,j,k)=real(z(i)) x1imag(i,j,k)=aimag(z(i)) !$OMP END PARALLEL. do k=1,n3. do j=1,n2. do i=1,n1. z(i)=cmplx(x1real(i,j,k),x1imag(i,j,k)) end do. call fft(z,inverse,w,n1,m1) x1real(i,j,k)=real(z(i)) x1imag(i,j,k)=aimag(z(i)) NEXT: compare the 1 and 2 processor profiles after adding OpenMP to this loop.")
44
Parallelizing the Reminder of Fftpde.F
The DO 130 loop near line 64 (fftpde_2.F) The DO 190 loop near line 115 (fftpde_3.F) 3) The DO 220 loop near line 139 (fftpde_4.F) 4) The DO 250 loop near line 155 (fftpde_5.F)
 The DO 190 loop near line 115 (fftpde_3.F) 3) The DO 220 loop near line 139 (fftpde_4.F) 4) The DO 250 loop near line 155 (fftpde_5.F)")
45
1. Parallelize the DO 130 loop in Fftpde_2.F
!$OMP PARALLEL PRIVATE(KK,KL,T1,T2,IK) !$OMP DO DO 130 K = 1, N3 KK = K - 1 KL = KK T1 = S T2 = AN C C Find starting seed T1 for this KK using the binary rule for exponentiation. DO 110 I = 1, 100 IK = KK / 2 IF (2 * IK .NE. KK) T2 = RANDLC (T1, T2) IF (IK .EQ. 0) GOTO 120 T2 = RANDLC (T2, T2) KK = IK CONTINUE C Compute 2 * NQ pseudorandom numbers. 120 continue CALL VRANLC (N1*N2, T2, aa, x1real(1,1,k)) CALL VRANLC (N1*N2, T2, aa, x1imag(1,1,k)) 130 CONTINUE !$OMP END PARALLEL 1. Parallelize the DO 130 loop in Fftpde_2.F
 !$OMP DO. DO 130 K = 1, N3. KK = K - 1. KL = KK. T1 = S. T2 = AN. C. C Find starting seed T1 for this KK using the binary rule for exponentiation. DO 110 I = 1, 100. IK = KK / 2. IF (2 * IK .NE. KK) T2 = RANDLC (T1, T2) IF (IK .EQ. 0) GOTO 120. T2 = RANDLC (T2, T2) KK = IK. 110 CONTINUE. C Compute 2 * NQ pseudorandom numbers. 120 continue. CALL VRANLC (N1*N2, T2, aa, x1real(1,1,k)) CALL VRANLC (N1*N2, T2, aa, x1imag(1,1,k)) 130 CONTINUE. !$OMP END PARALLEL. 1. Parallelize the DO 130 loop in Fftpde_2.F.")
46
!$OMP PARALLEL PRIVATE(K1,J1,JK,I1)
!$OMP DO DO 190 K = 1, N3 K1 = K - 1 IF (K .GT. N32) K1 = K1 - N3 C DO 180 J = 1, N2 J1 = J - 1 IF (J .GT. N22) J1 = J1 - N2 JK = J1 ** 2 + K1 ** 2 DO 170 I = 1, N1 I1 = I - 1 IF (I .GT. N12) I1 = I1 - N1 X3(I,J,K) = EXP (AP * (I1 ** 2 + JK)) CONTINUE CONTINUE 190 CONTINUE !$OMP END PARALLEL 2. Parallelize the DO 190 loop in Fftpde_3.F
 K1 = K1 - N3. C. DO 180 J = 1, N2. J1 = J - 1. IF (J .GT. N22) J1 = J1 - N2. JK = J1 ** 2 + K1 ** 2. DO 170 I = 1, N1. I1 = I - 1. IF (I .GT. N12) I1 = I1 - N1. X3(I,J,K) = EXP (AP * (I1 ** 2 + JK)) 170 CONTINUE. 180 CONTINUE. 190 CONTINUE. !$OMP END PARALLEL. 2. Parallelize the DO 190 loop in Fftpde_3.F.")
47
3. Parallelize the DO 220 loop in Fftpde_4.F
!$OMP PARALLEL PRIVATE(T1) !$OMP DO DO 220 K = 1, N3 DO 210 J = 1, N2 DO 200 I = 1, N1 T1 = X3(I,J,K) ** KT X2real(I,J,K) = T1 * X1real(I,J,K) X2imag(I,J,K) = T1 * X1imag(I,J,K) CONTINUE CONTINUE CONTINUE !$OMP END PARALLEL
 !$OMP DO. DO 220 K = 1, N3. DO 210 J = 1, N2. DO 200 I = 1, N1. T1 = X3(I,J,K) ** KT. X2real(I,J,K) = T1 * X1real(I,J,K) X2imag(I,J,K) = T1 * X1imag(I,J,K) 200 CONTINUE. 210 CONTINUE. 220 CONTINUE. !$OMP END PARALLEL.")
48
4. Parallelize the DO 250 loop in Fftpde_5.F
!$OMP PARALLEL !$OMP DO DO 250 K = 1, N3 DO 240 J = 1, N2 DO 230 I = 1, N1 X2real(I,J,K) = RN * X2real(I,J,K) X2imag(I,J,K) = RN * X2imag(I,J,K) CONTINUE CONTINUE CONTINUE !$OMP END PARALLEL
 = RN * X2real(I,J,K) X2imag(I,J,K) = RN * X2imag(I,J,K) 230 CONTINUE. 240 CONTINUE. 250 CONTINUE. !$OMP END PARALLEL.")
49
Conclusion OpenMP is successful in small-to-medium SMP systems
Multiple cores/CPUs dominate the future computer architectures; OpenMP would be the major parallel programming language in these architectures. Simple: everybody can learn it in 2 weeks Not so simple: Don’t stop learning! keep learning it for better performance

50
Some Buggy Codes #pragma omp parallel for shared(a,b,c,chunk) private(i,tid) schedule(static,chunk) { tid = omp_get_thread_num(); for (i=0; i < N; i++) c[i] = a[i] + b[i]; printf("tid= %d i= %d c[i]= %f\n", tid, i, c[i]); } } /* end of parallel for construct */
; for (i=0; i < N; i++) c[i] = a[i] + b[i]; printf( tid= %d i= %d c[i]= %f\n , tid, i, c[i]); } } /* end of parallel for construct */")
51
Content Overview of OpenMP Acknowledgement
OpenMP constructs (5 categories) OpenMP exercises References
 OpenMP exercises. References.")
52
References OpenMP Official Website: OpenMP 2.5 Specifications
OpenMP 2.5 Specifications An OpenMP book Rohit Chandra, “Parallel Programming in OpenMP”. Morgan Kaufmann Publishers. Compunity The community of OpenMP researchers and developers in academia and industry Conference papers: WOMPAT, EWOMP, WOMPEI, IWOMP

53
Exercises cp /tmp/omp_examples.tar.gz ~/ tar –xzvf omp_examples.tar.gz
(marvin:) use pathscale; (medusa:) use pgi pathf90; pathcc mp -Ofast pgf90; pgcc mp -fast Compile(make) and run the codes in LLNL_C, LLNL_F, and FFT There is a README in each subdirectory Set the number of threads before running Echo $SHELL export OMP_NUM_THREADS=2 (for bsh) setenv OMP_NUM_THREADS=2 (for csh)
 use pathscale; (medusa:) use pgi. pathf90; pathcc -mp -Ofast. pgf90; pgcc -mp -fast. Compile(make) and run the codes in. LLNL_C, LLNL_F, and FFT. There is a README in each subdirectory. Set the number of threads before running. Echo $SHELL. export OMP_NUM_THREADS=2 (for bsh) setenv OMP_NUM_THREADS=2 (for csh)")
54
OpenMP Compilers and Platforms
Fujitsu/Lahey Fortran, C and C++ Intel Linux Systems Fujitsu Solaris Systems HP HP-UX PA-RISC/Itanium , HP Tru64 Unix Fortran/C/C++ IBM XL Fortran and C from IBM IBM AIX Systems Intel C++ and Fortran Compilers from Intel Intel IA32 Linux/Windows Systems Intel Itanium-based Linux/Windows Systems Guide Fortran and C/C++ from Intel's KAI Software Lab Intel Linux/Windows Systems PGF77 and PGF90 Compilers from The Portland Group, Inc. (PGI) Intel Linux/Solaris/Windows/NT Systems
 Intel Linux/Solaris/Windows/NT Systems.")
55
Compilers and Platforms
SGI MIPSpro 7.4 Compilers SGI IRIX Systems Sun Microsystems Sun ONE Studio, Compiler Collection, Fortran 95, C, and C++ Sun Solaris Platforms VAST from Veridian Pacific-Sierra Research IBM AIX Systems Intel IA32 Linux/Windows/NT Systems Sun Solaris Systems PATHSCALE EKOPATH™ COMPILER SUITE FOR AMD64 and EM64T, Fortran, C, C++ 64-bit Linux Microsoft Visual Studio 2005 (Visual C++) Windows
 Windows.")
56
Parallelize: Win32 API, PI
#include <windows.h> #define NUM_THREADS 2 HANDLE thread_handles[NUM_THREADS]; CRITICAL_SECTION hUpdateMutex; static long num_steps = ; double step; double global_sum = 0.0; void Pi (void *arg) { int i, start; double x, sum = 0.0; start = *(int *) arg; step = 1.0/(double) num_steps; for (i=start;i<= num_steps; i=i+NUM_THREADS){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } EnterCriticalSection(&hUpdateMutex); global_sum += sum; LeaveCriticalSection(&hUpdateMutex); void main () { double pi; int i; DWORD threadID; int threadArg[NUM_THREADS]; for(i=0; i<NUM_THREADS; i++) threadArg[i] = i+1; InitializeCriticalSection(&hUpdateMutex); for (i=0; i<NUM_THREADS; i++){ thread_handles[i] = CreateThread(0, 0, (LPTHREAD_START_ROUTINE) Pi, &threadArg[i], 0, &threadID); } WaitForMultipleObjects(NUM_THREADS, thread_handles, TRUE,INFINITE); pi = global_sum * step; printf(" pi is %f \n",pi); Doubles code size!
 { int i, start; double x, sum = 0.0; start = *(int *) arg; step = 1.0/(double) num_steps; for (i=start;i<= num_steps; i=i+NUM_THREADS){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } EnterCriticalSection(&hUpdateMutex); global_sum += sum; LeaveCriticalSection(&hUpdateMutex); void main () { double pi; int i; DWORD threadID; int threadArg[NUM_THREADS]; for(i=0; i<NUM_THREADS; i++) threadArg[i] = i+1; InitializeCriticalSection(&hUpdateMutex); for (i=0; i<NUM_THREADS; i++){ thread_handles[i] = CreateThread(0, 0, (LPTHREAD_START_ROUTINE) Pi, &threadArg[i], 0, &threadID); } WaitForMultipleObjects(NUM_THREADS, thread_handles, TRUE,INFINITE); pi = global_sum * step; printf( pi is %f \n ,pi); Doubles code size!")
57
Solution: Keep it simple
Threads libraries: Pro: Programmer has control over everything Con: Programmer must control everything Full control Increased complexity Programmers scared away Sometimes a simple evolutionary approach is better

58
PI Program: an example static long num_steps = 100000; double step;
void main () { int i; double x, pi, sum = 0.0; step = 1.0/(double) num_steps; for (i=1;i<= num_steps; i++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = step * sum;
 { int i; double x, pi, sum = 0.0; step = 1.0/(double) num_steps; for (i=1;i<= num_steps; i++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = step * sum;")
59
OpenMP PI Program: Parallel Region example (SPMD Program)
#include <omp.h> static long num_steps = ; double step; #define NUM_THREADS 2 void main () { int i; double x, pi, sum[NUM_THREADS]; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel { double x; int id; id = omp_get_thread_num(); for (i=id, sum[id]=0.0;i< num_steps; i=i+NUM_THREADS){ x = (i+0.5)*step; sum[id] += 4.0/(1.0+x*x); } for(i=0, pi=0.0;i<NUM_THREADS;i++) pi += sum[i] * step; SPMD Programs: Each thread runs the same code with the thread ID selecting any thread specific behavior.
 { int i; double x, pi, sum[NUM_THREADS]; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel. { double x; int id; id = omp_get_thread_num(); for (i=id, sum[id]=0.0;i< num_steps; i=i+NUM_THREADS){ x = (i+0.5)*step; sum[id] += 4.0/(1.0+x*x); } for(i=0, pi=0.0;i<NUM_THREADS;i++) pi += sum[i] * step; SPMD Programs: Each thread runs the same code with the thread ID. selecting any thread specific behavior.")
60
OpenMP PI Program: Work Sharing Construct
#include <omp.h> static long num_steps = ; double step; #define NUM_THREADS 2 void main () { int i; double x, pi, sum[NUM_THREADS]; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS) #pragma omp parallel { double x; int id; id = omp_get_thread_num(); sum[id] = 0; #pragma omp for for (i=id;i< num_steps; i++){ x = (i+0.5)*step; sum[id] += 4.0/(1.0+x*x); } } for(i=0, pi=0.0;i<NUM_THREADS;i++)pi += sum[i] * step; }
 { int i; double x, pi, sum[NUM_THREADS]; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS) #pragma omp parallel { double x; int id; id = omp_get_thread_num(); sum[id] = 0; #pragma omp for for (i=id;i< num_steps; i++){ x = (i+0.5)*step; sum[id] += 4.0/(1.0+x*x); } } for(i=0, pi=0.0;i<NUM_THREADS;i++)pi += sum[i] * step; }")
61
OpenMP PI Program: Private Clause and a Critical Section
#include <omp.h> static long num_steps = ; double step; #define NUM_THREADS 2 void main () { int i, id; double x, sum, pi=0.0; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel private (x, sum) { id = omp_get_thread_num(); for (i=id,sum=0.0;i< num_steps;i=i+NUM_THREADS){ x = (i+0.5)*step; sum += 4.0/(1.0+x*x); } #pragma omp critical pi += sum } } Note: We didn’t need to create an array to hold local sums or clutter the code with explicit declarations of “x” and “sum”.
 { int i, id; double x, sum, pi=0.0; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel private (x, sum) { id = omp_get_thread_num(); for (i=id,sum=0.0;i< num_steps;i=i+NUM_THREADS){ x = (i+0.5)*step; sum += 4.0/(1.0+x*x); } #pragma omp critical pi += sum } } Note: We didn’t need to create an array to hold local sums or clutter the code with explicit declarations of x and sum .")
62
OpenMP PI Program: Parallel For with a Reduction
#include <omp.h> static long num_steps = ; double step; #define NUM_THREADS 2 void main () { int i; double x, pi, sum = 0.0; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel for reduction(+:sum) private(x) for (i=1;i<= num_steps; i++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = step * sum; } OpenMP adds 2 to 4 lines of code
 { int i; double x, pi, sum = 0.0; step = 1.0/(double) num_steps; omp_set_num_threads(NUM_THREADS); #pragma omp parallel for reduction(+:sum) private(x) for (i=1;i<= num_steps; i++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = step * sum; } OpenMP adds 2 to 4. lines of code.")
Similar presentations















 1997-98, John Thornley1 CS 284a Lecture Tuesday, 7 October 1997.>")




