Download presentation
Presentation is loading. Please wait.

1
Building the Trident Scientific Workflow Workbench for Data Management in the Cloud Roger Barga, MSR Yogesh Simmhan, Ed Lazowska, Alex Szalay, and Catharine van Ingen

2
Demonstrate that a commercial workflow management system can be used to implement scientific workflow Offer this system as an open source accelerator Write once, deploy and run anywhere... Abstract parallelism (HPC and many core); Automatic provenance capture, for both workflow and results; Costing model for estimating resource required; Integrated data storage and access, in particular cloud computing; Reproducible research; Develop this in the context of real eScience applications Make sure we solve a real problem for actual project(s). And this is where things started to get interesting...
; Automatic provenance capture, for both workflow and results; Costing model for estimating resource required; Integrated data storage and access, in particular cloud computing; Reproducible research; Develop this in the context of real eScience applications Make sure we solve a real problem for actual project(s). And this is where things started to get interesting....")
3
Role of workflow in data intensive eScience Explore architectural patterns/best practices Scalability Fault Tolerance Provenance Reference architecture, to handle data from creation/capture to curated reference data, and serve as a platform for research

8
Workflow is a bridge between the underwater sensor array (instrument) and the end users Features Allow human interaction with instruments; Create ‘on demand’ visualizations of ocean processes; Store data for long term time-series studies Deployed instruments will change regularly, as will the analysis; Facilitate automated, routine “survey campaigns”; Support automated event detection and reaction; User able to access through web (or custom client software); Best effort for most workflows is acceptable;
 and the end users Features Allow human interaction with instruments; Create ‘on demand’ visualizations of ocean processes; Store data for long term time-series studies Deployed instruments will change regularly, as will the analysis; Facilitate automated, routine survey campaigns ; Support automated event detection and reaction; User able to access through web (or custom client software); Best effort for most workflows is acceptable;")
9
One of the largest visible light telescopes 4 unit telescopes acting as one 1 Gigapixel per telescope Surveys entire visible universe once per week Catalog solar system, moving objects/asteroids ps1sc.org: UHawaii, Johns Hopkins, …

10
30TB of processed data/year ~1PB of raw data 5 billion objects; 100 million detections/week Updated every week SQL Server 2008 for storing detections Distributed over spatially partitioned databases Replicated for fault tolerance Windows 2008 HPC Cluster Schedules workflow, monitor system

11
Slice 1 Slice 1 Slice 2 Slice 2 Slice 3 Slice 3 Slice 4 Slice 4 Slice 5 Slice 5 Slice 6 Slice 6 Slice 7 Slice 7 Slice 8 Slice 8 S1S1 S1S1 S2S2 S2S2 S3S3 S3S3 S4S4 S4S4 S5S5 S5S5 S6S6 S6S6 S7S7 S7S7 S8S8 S8S8 S9S9 S9S9 S 10 S 10 S 11 S 11 S 12 S 12 S 13 S 13 S 14 S 14 S 15 S 15 S 16 S 16 s 16 s 16 s3s3 s3s3 s2s2 s2s2 s5s5 s5s5 s4s4 s4s4 s7s7 s7s7 s6s6 s6s6 s9s9 s9s9 s8s8 s8s8 s 11 s 11 s 10 s 10 s 13 s 13 s 12 s 12 s 15 s 15 s 14 s 14 s1s1 s1s1 Load Merge 1 Load Merge 1 Load Merge 2 Load Merge 2 Load Merge 3 Load Merge 3 Load Merge 4 Load Merge 4 Load Merge 5 Load Merge 5 Load Merge 6 Load Merge 6 S1S1 S1S1 S2S2 S2S2 S3S3 S3S3 S4S4 S4S4 S5S5 S5S5 S6S6 S6S6 S7S7 S7S7 S8S8 S8S8 S9S9 S9S9 S 10 S 10 S 11 S 11 S 12 S 12 S 13 S 13 S 14 S 14 S 15 S 15 S 16 S 16 csv IPP Shared Data Store L1 L2 HOTHOTHOTHOT WARMWARMWARMWARM Main Distributed View

12
Telescope CSV Files CSV Files Image Procesing Pipeline (IPP) CSV Files CSV Files Load Workflow Load DB Cold Slice DB 1 Cold Slice DB 2 Warm Slice DB 1 Warm Slice DB 2 Merge Workflow Hot Slice DB 2 Hot Slice DB 1 Flip Workflow Distrib uted View CASJobs Query Service CASJobs Query Service MyDB The Pan-STARRS Science Cloud ← Behind the Cloud|| User facing services → Validation Exception Notification Data Valet Workflows Data Consumer Queries & Workflows Data flows in one direction→, except for error recovery Slice Fault Recover Workflow Data Creators Astronomers (Data Consumers) Admin & Load-Merge Machines Production Machines
 CSV Files CSV Files Load Workflow Load DB Cold Slice DB 1 Cold Slice DB 2 Warm Slice DB 1 Warm Slice DB 2 Merge Workflow Hot Slice DB 2 Hot Slice DB 1 Flip Workflow Distrib uted View CASJobs Query Service CASJobs Query Service MyDB The Pan-STARRS Science Cloud ← Behind the Cloud|| User facing services → Validation Exception Notification Data Valet Workflows Data Consumer Queries & Workflows Data flows in one direction→, except for error recovery Slice Fault Recover Workflow Data Creators Astronomers (Data Consumers) Admin & Load-Merge Machines Production Machines")
13
Workflow is just a member of the orchestra

14
Workflow carries out the data loading and merging Features Support scheduling of workflows for nightly load and merge; Offer only controlled (protected) access to the workflow system; Workflows are tested, hardened and seldom change; Not a unit of reuse or knowledge sharing; Fault tolerance – ensure recovery and cleanup from faults; Assign clean up workflows to undo state changes; Provenance as a record of state changes (system management); Performance monitoring and logging for diagnostics; Must “play well” in a distributed system; Provide ground truth for the state of the system;
 access to the workflow system; Workflows are tested, hardened and seldom change; Not a unit of reuse or knowledge sharing; Fault tolerance – ensure recovery and cleanup from faults; Assign clean up workflows to undo state changes; Provenance as a record of state changes (system management); Performance monitoring and logging for diagnostics; Must play well in a distributed system; Provide ground truth for the state of the system;")
16
Scientific data from sensors and instruments Time series, spatially distributed Need to be ingested before use Go from Level 1 to Level 2 data Potentially large, continuous stream of data A variety of end users (consumers) of this data Workflows shepherd raw bits from instruments to usable data in databases in the Cloud
 of this data Workflows shepherd raw bits from instruments to usable data in databases in the Cloud")
17
Producer Data Valets Publishers Consumers Data Products Curators Reject/Fix New data upload Data Correction Reject/ Fix New data upload Accepted Data Download Data Correction Query Result Publish New Data

18
Shared Compute Resources Shared Queryable Data Store Configuration Management, Health and Performance Monitoring Operator User Interface User Interface Data Valet User Interface VALET WORKFLOWVALET WORKFLOW USER WORKFLOWUSER WORKFLOW User Storage Data Flow Control Flow Data Valet Queryable Data Store User Queryable Data Store

20
Switch OUT Slice partition to temp For Each Partition in Slice Cold DB UNION ALL over Slice & Load DBs into temp. Filter on partition bound. Start Post Partition Load Validation Switch IN temp to Slice partition End Detect Merge Fault. Launch Recovery Operations. Notify Admin. Slice Column Recalculations & Updates Post Slice Load Validation Determine ‘Merge Worthy’ Load DBs & Slice Cold DBs Sanity Check of Network Files, Manifest, Checksum Validate CSV File & Table Schema Create, Register empty LoadDB from template For Each CSV File in Batch BULK LOAD CSV File into Table Start Perform CSV File/Table Validation Perform LoadDB/Batch Validation End Detect Load Fault. Launch Recovery Operations. Notify Admin. Determine affine Slice Cold DB for CSV Batch

21
Monitor state of the system Data centric and Process centric views What is the Load/Merge state of each database in the system? What are the active workflows in the system? Drill down into actions performed: On a particular database till date By a particular workflow

22
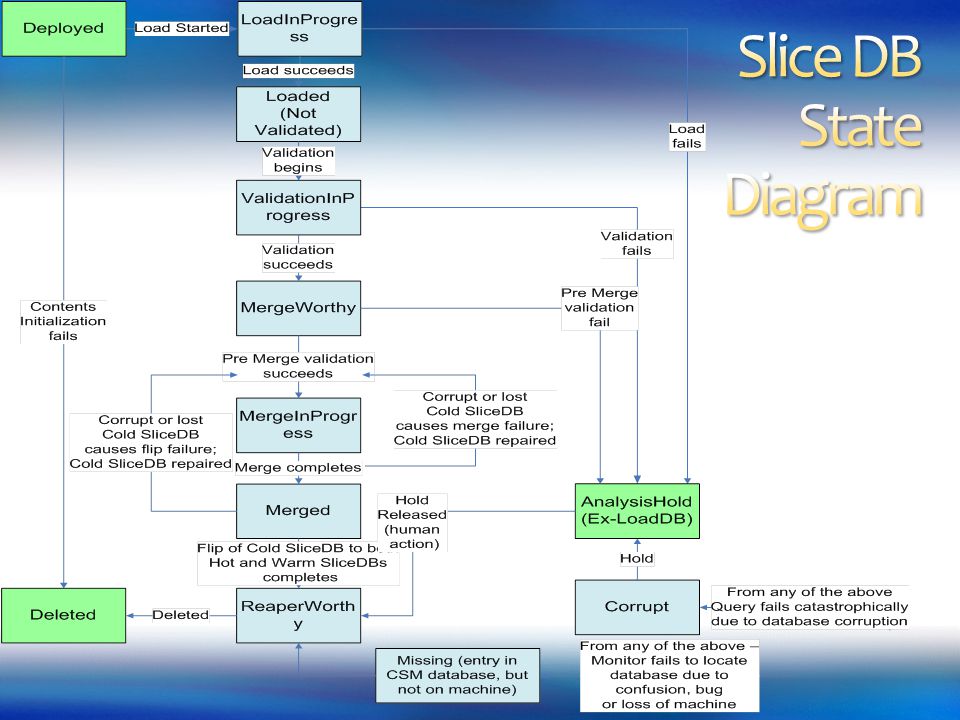
Need a way to monitor state of the system Databases & Workflows Need a way to recover from error states Database states are modeled as a state transition diagram Workflows cause transition from one state to another state Provenance forms an intelligent system log

25
Faults are just another state PS aims to support 2 degrees of failure Upto 2 replicas out of 3 can fail and still be recovered

26
Provenance logs need to identify type and location of failure Verification of fault paths Attribution of failure to human error, infrastructure failure, data error Global view of system state during fault

27
Fine grained workflow activities Activity does one task Eases failure recovery Capture inputs and outputs from workflow/activity Relational/XML model for storing provenance Generic model supports complex.NET types Identify stateful data in parameters Build a relational view on the data states Domain specific view Encodes semantic knowledge in view query

28
Fault recovery depends on provenance Missing provenance can cause unstable system upon faults Provenance collection is synchronous Provenance events published using reliable (durable) messaging Guarantee that the event will be eventually delivered Provenance is reliably persisted
 messaging Guarantee that the event will be eventually delivered Provenance is reliably persisted")
29
Trident Logical Architecture Visualization Design Workflow Packages Windows Workflow Foundation Trident Runtime Services Service & Activity Registry Workbench Scientific Workflows Provenance Fault Tolerance WinHPC Scheduling Monitoring Service Runtime Workflow Monitor Administration Console Workflow Launcher Community Archiving Web Portal Data Access Data Object Model (Database Agnostic Abstraction) SQL Server, SSDS Cloud DB, S3, …
 SQL Server, SSDS Cloud DB, S3, …")
30
Role of workflow in data intensive eScience Data Valet Explore architectural patterns/best practices Scalability, Fault Tolerance and Provenance implemented through workflow patterns Reference architecture, to handle data from creation/capture to curated reference data, and serve as a platform for research GrayWulf reference architecture

31
Data Acquisition Data Assembly Discovery and Browsing Science Exploration Domain Specific Analyses Scientific Output Archive Field sensor deployments and operations; field campaigns measuring site properties. “Raw” data includes sensor output, data downloaded from agency or collaboration web sites, papers (especially for ancillary data. “Raw” data browsing for discovery (do I have enough data in the right places?), cleaning (does the data look obviously wrong?), and light weight science via browsing “Science variables” and data summaries for hypothesis testing and early exploration. Like discovery and browsing, but variables are computed via gap filling, units conversions, or simple equations. “Science variables” combined with models, other specialized code, or statistics for deep science understanding. Scientific results via packages such as MatLab or R2. Special rendering package such as ArcGIS. Data and analysis methodology stored for data reuse, or repeating an analysis.
, cleaning (does the data look obviously wrong ), and light weight science via browsing Science variables and data summaries for hypothesis testing and early exploration. Like discovery and browsing, but variables are computed via gap filling, units conversions, or simple equations. Science variables combined with models, other specialized code, or statistics for deep science understanding. Scientific results via packages such as MatLab or R2. Special rendering package such as ArcGIS. Data and analysis methodology stored for data reuse, or repeating an analysis..")
Similar presentations











 Nelson Araujo, Dean Guo, Jared Jackson, Microsoft Research The creative input of the Trident.>")














 VGL v1.2 NeCTAR Project Close R.Fraser, T.Rankine, J.Vote, L.Wyborn, B.Evans, R.Woodcock, C.Kemp July 2013 CSIRO |>")