Download presentation
Presentation is loading. Please wait.

1
File Consistency in a Parallel Environment Kenin Coloma kcoloma@ece.northwestern.edu

2
Outline Data consistency in parallel file systems –Consistency Semantics –File caching effect –Consistency in MPI-IO 2-phase collective IO in ROMIO (a popular MPI-IO implementation) Intuitive Solutions Persistent File Domains –PFDs - concept –PFDs - statically blocked assignment –PFDs - statically striped assignment –PFDs - dynamic assignment Performance Comparisons Conclusions & Future Work
 Intuitive Solutions Persistent File Domains –PFDs - concept –PFDs - statically blocked assignment –PFDs - statically striped assignment –PFDs - dynamic assignment Performance Comparisons Conclusions & Future Work")
3
Consistency Semantics POSIX and UNIX sequential consistency: –Once a write has returned, the resulting file must be visible to all processors MPI-IO sequential consistency: –Once a write has returned, the resulting file must be visible only to processors in the same Communicator –If the underlying file system does not support POSIX or UNIX consistency semantics, MPI-IO must enforce its sequential consistency semantics itself

4
Caching and Consistency The client-server model for file systems often relies on client-side caching for performance benefits –Client-side caching reduces the amount of data that needs to be transferred from the server NFS is one such file system, and does not enforce POSIX or UNIX consistency semantics

5
Caching and Consistency Open Seek(0 byte_off) Read(16 bytes) Barrier Seek(rank*4 byte_off) Write(4 bytes) Barrier p0: p1: p2: p3: client-side file caches p0: p1: p2: p3: Seek(0 byte_off) Read(16 bytes) Close ≠ user buffers A simple example using MPI and unix io on NFS - 4 procs
 Read(16 bytes) Barrier Seek(rank*4 byte_off) Write(4 bytes) Barrier p0: p1: p2: p3: client-side file caches p0: p1: p2: p3: Seek(0 byte_off) Read(16 bytes) Close ≠ user buffers A simple example using MPI and unix io on NFS - 4 procs")
6
2-phase Collective IO in ROMIO 2-phase I/O, proposed and designed in PASSION (by Prof. Choudhary) is widely used in parallel I/O optimizations. MPI-IO implementation in ROMIO uses 2-phase collective I/O Advantages of collective IO –Awareness of access patterns (often non-contiguous) of all participating processes –Means of coordinating participating processes to optimize overall IO performance
 is widely used in parallel I/O optimizations. MPI-IO implementation in ROMIO uses 2-phase collective I/O Advantages of collective IO –Awareness of access patterns (often non-contiguous) of all participating processes –Means of coordinating participating processes to optimize overall IO performance.")
7
2-phase Collective IO in ROMIO 2-phase IO –Communication –IO Reduce the number of IO calls to IO servers as well as the number of IO requests generated at the server All the IO done is more localized than it would otherwise be User buffers Comm. buffers IO buffers File 2-phase Collective Write File Domain Aggregate Access [Region]

8
2-phase Collective IO in ROMIO A simple example to exhibit the file consistency problems even with collective IO in ROMIO - 4 procs p0: p1: p2: p3: client-side file caches p0: p1: p2: p3: user buffers MPI_File_open MPI_File_read_all() [whole file] MPI_File_read_all() [whole file] MPI_File_write_all() [stripe 1st half] ≠ MPI_File_close
![2-phase Collective IO in ROMIO A simple example to exhibit the file consistency problems even with collective IO in ROMIO - 4 procs p0: p1: p2: p3: client-side file caches p0: p1: p2: p3: user buffers MPI_File_open MPI_File_read_all() [whole file] MPI_File_read_all() [whole file] MPI_File_write_all() [stripe 1st half] ≠ MPI_File_close](http://images.slideplayer.com/11/3292274/slides/slide_8.jpg "2-phase Collective IO in ROMIO A simple example to exhibit the file consistency problems even with collective IO in ROMIO - 4 procs p0: p1: p2: p3: client-side file caches p0: p1: p2: p3: user buffers MPI_File_open MPI_File_read_all() [whole file] MPI_File_read_all() [whole file] MPI_File_write_all() [stripe 1st half] ≠ MPI_File_close")
9
Intuitive Solutions The cause: obsolete data cached in client-side system buffer Simple solutions: –Disabling client-side caching entails changes to system configuration lose performance benefits of caching –Use file locking can serialize I/O not feasible on large scale parallel systems effectively disables client-side caching –Explicitly flushing out the cached data is the simplest solution, such as on Cplant ioctl(fd, BLKBLSBUF) fsync(fd) ensure the write reside on disk also effectively disables client-side caching
 fsync(fd) ensure the write reside on disk also effectively disables client-side caching")
10
File locking File locking can cause IO serialization even if accesses do not logically overlap This is evident in collective IO where file domains never overlap p0: p1:

11
fsync and ioctl On Cplant –Flush before every read –Fsync after every write Performance ramifications –Could be invalidating perfectly good data Open Seek(0 byte_off) Read(16 bytes) Barrier Seek(rank*4 byte_off) Write(4 bytes) Barrier Seek(0 byte_off) Read(16 bytes) Close < fsync(fd) < ioctl(fd, BLKFLSBUF)
 Read(16 bytes) Barrier Seek(rank*4 byte_off) Write(4 bytes) Barrier Seek(0 byte_off) Read(16 bytes) Close < fsync(fd) < ioctl(fd, BLKFLSBUF)")
12
Persistent File Domains Similar to the file domains concept in ROMIO’s collective IO routines Enforces MPI-IO consistency semantics while retaining client-side file caching Safe concurrent accesses 3 - assignment strategies –Statically blocked assignment –Statically striped assignment –Dynamic (on-the-fly) assignment
 assignment")
13
Statically blocked assignment Client side caches are coherent before starting File domains are kept the same between collective IO calls Maintain file consistency -- each byte can only be accessed by one processor Avoids excessive fsync and ioctl MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_write_all MPI_File_read_all MPI_File_close File size could be useful in creating file domains Create file domains Delete file domains fsync(fd->fd_sys) ioctl(fd->fd_sys, BLKFLSBUF) fsync(fd->fd_sys) ioctl(fd->fd_sys, BLKFLSBUF) ENFS Servers & File Domains Compute Nodes
 ioctl(fd->fd_sys, BLKFLSBUF) fsync(fd->fd_sys) ioctl(fd->fd_sys, BLKFLSBUF) ENFS Servers & File Domains Compute Nodes")
14
Statically blocked assignment Statically Blocked Assignment Based on ~equal division of whole file Least complexity & least amount of changes to ROMIO ADIOI_Calc_aggregator() - just a calculation, based on –File size –Number of processes
 - just a calculation, based on –File size –Number of processes")
15
Statically blocked assignment A Key Structure - ADIOI_Access struct { ADIO_Offset *offsets int *lens MPI_Aint *mem_ptrs int *file_domains int count } my_reqs[nprocs] others_reqs[nprocs]
![Statically blocked assignment A Key Structure - ADIOI_Access struct { ADIO_Offset *offsets int *lens MPI_Aint *mem_ptrs int *file_domains int count } my_reqs[nprocs] others_reqs[nprocs]](http://images.slideplayer.com/11/3292274/slides/slide_15.jpg "Statically blocked assignment A Key Structure - ADIOI_Access struct { ADIO_Offset *offsets int *lens MPI_Aint *mem_ptrs int *file_domains int count } my_reqs[nprocs] others_reqs[nprocs]")
16
Statically blocked assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

17
Statically blocked assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

18
Statically blocked assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

19
Statically blocked assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

20
Statically blocked assignment Drawback –File inconsistency comes about when there are multiple IO calls often to different regions of the file rather than the whole file –The previous point means that this assignment scheme will not be efficient unless accesses are rather large portions of file (~3/4 of the file size) p0: p1: p2: p3: p0: p1: p2: p3: user buffers client-side file caches
 p0: p1: p2: p3: p0: p1: p2: p3: user buffers client-side file caches")
21
Statically striped assignment Statically Striped Assignment Based on a striping block size parameter passed to ROMIO through file system hints mechanism Somewhat more complex than statically blocked assignments –Processes can “own” multiple file domains –More end cases ADIOI_Calc_Aggregator() - still just a calculation, based on –Striping block size –Number of processes Striping block size
 - still just a calculation, based on –Striping block size –Number of processes Striping block size")
22
Statically striped assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

23
Statically striped assignment One significant change due to processes having multiple file domains and communication Mapping communicated data to or from the user buffer p0p1p0p1 p0p1 buf_idx[0] buf_idx[1] buf_idx[0]buf_idx[1] buf_idx[0]
![Statically striped assignment One significant change due to processes having multiple file domains and communication Mapping communicated data to or from the user buffer p0p1p0p1 p0p1 buf_idx[0] buf_idx[1] buf_idx[0]buf_idx[1] buf_idx[0]](http://images.slideplayer.com/11/3292274/slides/slide_23.jpg "Statically striped assignment One significant change due to processes having multiple file domains and communication Mapping communicated data to or from the user buffer p0p1p0p1 p0p1 buf_idx[0] buf_idx[1] buf_idx[0]buf_idx[1] buf_idx[0]")
24
Statically striped assignment MPI_File_open MPI_File_set_size MPI_File_read_all MPI_File_close

25
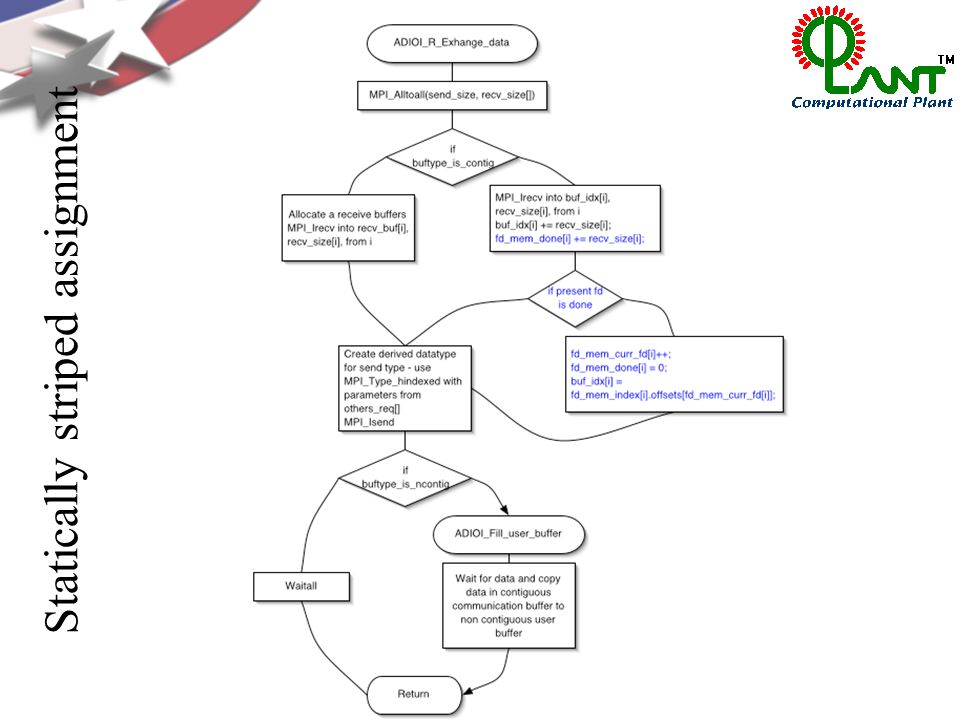
Statically striped assignment

27
Opportunity to match stripe size to access pattern Should work particularly well if the aggregate access regions for each IO call are fairly consistent ~nprocs*stripe size This becomes less significant if the stripe size is greater than the data sieve buffer (dflt: 4MB) p0: p1: p2: p3: p0: p1: p2: p3: user buffers client-side file caches
 p0: p1: p2: p3: p0: p1: p2: p3: user buffers client-side file caches")
28
Dynamically assigned Static approaches cannot autonomously adapt to actual file access patterns 2 approaches –Incremental book keeping approach –reassignment Most complex of the three –Multiple file domains –With respect to the file layout, file domains are irregular –Assignment a definitive assignment policy must be established p0p1p2p3 p0p1 p2p3 write_all 1 write_all 2

29
Dynamically assigned ADIOI_Calc_aggregator will become a search function Augment ADIOI_Access Struct { ADIO_Offset *offsets int *lens int count Data structure pointers (e.g. b tree) }
 }.")
30
Performance Comparisons MPI_File_Open MPI_File_set_size() Loop (iter) MPI_File_Read_all MPI_File_Write_all MPI_File_close Factors: Collective Buffer Size (4MB) Stripe Size in Application Available cache Aggregate Access File size (Static Block) No. procs

31
Conclusions & Future Work File consistency can be realized without locking or any changes to system configuration Except for the statically block assigned method, all the methods tested resulted in similar results The exact conditions under which each solution will perform best still need to be determined through further experimentation The Dynamic approach to persistent file domains is still unimplemented and is still under design considerations –Reassignment vs. book keeping –Specifics of each policy also need to be worked out

32
Data sieving in ROMIO Quick overview of data sieving Data sieving is best suited for small densely distributed non-contiguous accesses Read case User buffer Data sieve buffer File

Similar presentations
>")






. One of the functions.>")











