Download presentation
Presentation is loading. Please wait.

1
The best indicator that a passenger will show up to board the flight is that she called in for a special meal Filtering and Recommender Systems Content-based and Collaborative 4/15

2
Filtering and Recommender Systems Content-based and Collaborative

3
Some of the slides based On Mooney’s Slides

4
Personalization Recommenders are instances of personalization software. Personalization concerns adapting to the individual needs, interests, and preferences of each user. Includes: –Recommending –Filtering –Predicting (e.g. form or calendar appt. completion) From a business perspective, it is viewed as part of Customer Relationship Management (CRM).
 From a business perspective, it is viewed as part of Customer Relationship Management (CRM)..")
5
Feedback & Prediction/Recommendation Traditional IR has a single user—probably working in single-shot modes –Relevance feedback… WEB search engines have: –Working continually User profiling –Profile is a “model” of the user (and also Relevance feedback) –Many users Collaborative filtering –Propagate user preferences to other users… You know this one
 –Many users Collaborative filtering –Propagate user preferences to other users… You know this one")
6
Recommender Systems in Use Systems for recommending items (e.g. books, movies, CD’s, web pages, newsgroup messages) to users based on examples of their preferences. Many on-line stores provide recommendations (e.g. Amazon, CDNow). Recommenders have been shown to substantially increase sales at on-line stores.
 to users based on examples of their preferences. Many on-line stores provide recommendations (e.g. Amazon, CDNow). Recommenders have been shown to substantially increase sales at on-line stores..")
7
Feedback Detection –Click certain pages in certain order while ignore most pages. –Read some clicked pages longer than some other clicked pages. –Save/print certain clicked pages. –Follow some links in clicked pages to reach more pages. –Buy items/Put them in wish-lists/Shopping Carts –Explicitly ask users to rate items/pages Non-Intrusive Intrusive

8
Justifying Recommendation.. Recommendation systems must justify their recommendations –Even if the justification is bogus.. –For search engines, the “justifications” are the page synopses Some recommendation algorithms are better at providing human-understandable justifications than others –Content-based ones can justify in terms of classifier features.. –Collaborative ones are harder-pressed other than saying “people like you seem to like this stuff” –In general, giving good justifications is important..

9
Content-based vs. Collaborative Recommendation Needs description of items… Needs only ratings from other users

10
Content-Based Recommending Recommendations are based on information on the content of items rather than on other users’ opinions. Uses machine learning algorithms to induce a profile of the users preferences from examples based on a featural description of content. Lots of systems

11
Adapting Naïve Bayes idea for Book Recommendation Vector of Bags model –E.g. Books have several different fields that are all text Authors, description, … A word appearing in one field is different from the same word appearing in another –Want to keep each bag different—vector of m Bags; Conditional probabilities for each word w.r.t each class and bag Can give a profile of a user in terms of words that are most predictive of what they like –Strengh of a keyword Log[P(w|rel)/P(w|~rel)] –We can summarize a user’s profile in terms of the words that have strength above some threshold. –Related to mutual information
/P(w|~rel)] –We can summarize a user’s profile in terms of the words that have strength above some threshold. –Related to mutual information.")
12
Collaborative Filtering A 9 B 3 C : Z 5 A B C 9 : Z 10 A 5 B 3 C : Z 7 A B C 8 : Z A 6 B 4 C : Z A 10 B 4 C 8. Z 1 User Database Active User Correlation Match A 9 B 3 C. Z 5 A 9 B 3 C : Z 5 A 10 B 4 C 8. Z 1 Extract Recommendations C Correlation analysis Here is similar to the Association clusters Analysis!

13
Item-User Matrix The input to the collaborative filtering algorithm is an mxn matrix where rows are items and columns are users –Sort of like term-document matrix (items are terms and documents are users) Can think of users as vectors in the space of items (or vice versa) –Can do vector similarity between users –Pearson correlation coefficient is a variation And find who are most similar users.. –Can do scalar clusters over items etc.. And find what are most correlated items Think users docs Items keywords

14
A Collaborative Filtering Method (think kNN) Weight all users with respect to similarity with the active user. –How to measure similarity? Could use cosine similarity; normally pearson coefficient is used Select a subset of the users (neighbors) to use as predictors. Normalize ratings and compute a prediction from a weighted combination of the selected neighbors’ ratings. Present items with highest predicted ratings as recommendations.
 to use as predictors. Normalize ratings and compute a prediction from a weighted combination of the selected neighbors’ ratings. Present items with highest predicted ratings as recommendations..")
15
Finding User Similarity with Person Correlation Coefficient Typically use Pearson correlation coefficient between ratings for active user, a, and another user, u. r a and r u are the ratings vectors for the m items rated by both a and u r i,j is user i’s rating for item j

16
Person Correlation Coefficient is the same as vector similarity over centered ratings vectors It is easy to check for yourself that pearson correlation coefficient is the same as the cosine theta distance between centered ratings vectors –Covariance = dot product –Sqrt (Variance of each vector) = norm of each vector
 = norm of each vector")
17
Neighbor Selection For a given active user, a, select correlated users to serve as source of predictions. Standard approach is to use the most similar k users, u, based on similarity weights, w a,u Alternate approach is to include all users whose similarity weight is above a given threshold.

18
Rating Prediction Predict a rating, p a,i, for each item i, for active user, a, by using the k selected neighbor users, u {1,2,…k}. To account for users different ratings levels, base predictions on differences from a user’s average rating. Weight users’ ratings contribution by their similarity to the active user. ri,j is user i’s rating for item j

19
Similarity Weighting=User Similarity Typically use Pearson correlation coefficient between ratings for active user, a, and another user, u. r a and r u are the ratings vectors for the m items rated by both a and u r i,j is user i’s rating for item j

20
Significance Weighting Important not to trust correlations based on very few co-rated items. Include significance weights, s a,u, based on number of co-rated items, m.

21
Covariance and Standard Deviation Covariance: Standard Deviation:

22
Item-centered Collaborative Filtering Starting with a “centered” user-item matrix, we found k-nearest users to the active user and used them to recommend unrated items We can also use the centered U-I matrix to compute item-item correlations by starting with U-I’xU-I, and doing (a) association clusters and (b) scalar clusters This will give us, for each item, k-nearest items –Now, given a new item I n to be rated for a user U, we first find k items closest to I n and, and take their (weighted) average rating from the user U as predictive of U’s rating of I n –An advantage of this method over the “user-centered” idea is that the justifications for the recommendations can be more meaningful (you can tell the user that we are recommending I n because she rated the items in its association cluster high..)
 association clusters and (b) scalar clusters This will give us, for each item, k-nearest items –Now, given a new item I n to be rated for a user U, we first find k items closest to I n and, and take their (weighted) average rating from the user U as predictive of U’s rating of I n –An advantage of this method over the user-centered idea is that the justifications for the recommendations can be more meaningful (you can tell the user that we are recommending I n because she rated the items in its association cluster high..)")
23
LSI-style techniques for collaborative filtering The NETFLIX prize was won by an approach that did “latent factor analysis” (aka LSI) on the u-i matrix, so that both users and items are seen as vectors in a k-dimensional factor space One technical difficulty in doing LSI on u-i matrix is that it has many “null” values –D-t matrix is sparse and that is good. U-I matrix has null values and that is bad (because null != 0) Two approaches: –“fill in” the missing ratings (“Imputation” method) so we have no more null values –“compute distance between vectors only in terms of their common non-null dimensions Problem: Overfitting. Solution: Regularization—penalize “large factor” values. q i item in factor space p u user in factor space
 Two approaches: – fill in the missing ratings ( Imputation method) so we have no more null values – compute distance between vectors only in terms of their common non-null dimensions Problem: Overfitting. Solution: Regularization—penalize large factor values. q i item in factor space p u user in factor space.")
24
Problems with Collaborative Filtering Cold Start: There needs to be enough other users already in the system to find a match. Sparsity: If there are many items to be recommended, even if there are many users, the user/ratings matrix is sparse, and it is hard to find users that have rated the same items. First Rater: Cannot recommend an item that has not been previously rated. –New items –Esoteric items Popularity Bias: Cannot recommend items to someone with unique tastes. – Tends to recommend popular items. WHAT DO YOU MEAN YOU DON’T CARE FOR BRITNEY SPEARS YOU DUNDERHEAD? #$%$%$&^

25
Advantages of Content-Based Approach No need for data on other users. –No cold-start or sparsity problems. Able to recommend to users with unique tastes. Able to recommend new and unpopular items – No first-rater problem. Can provide explanations of recommended items by listing content-features that caused an item to be recommended. Well-known technology The entire field of Classification Learning is at (y)our disposal!
our disposal!.")
26
Disadvantages of Content-Based Method Requires content that can be encoded as meaningful features. Users’ tastes must be represented as a learnable function of these content features. Unable to exploit quality judgments of other users. –Unless these are somehow included in the content features.

27
Movie Domain EachMovie Dataset [Compaq Research Labs] –Contains user ratings for movies on a 0–5 scale. –72,916 users (avg. 39 ratings each). –1,628 movies. –Sparse user-ratings matrix – (2.6% full). Crawled Internet Movie Database (IMDb) –Extracted content for titles in EachMovie. Basic movie information: –Title, Director, Cast, Genre, etc. Popular opinions: –User comments, Newspaper and Newsgroup reviews, etc.
![Movie Domain EachMovie Dataset [Compaq Research Labs] –Contains user ratings for movies on a 0–5 scale.](http://images.slideplayer.com/11/3277978/slides/slide_27.jpg "–72,916 users (avg. 39 ratings each). –1,628 movies. –Sparse user-ratings matrix – (2.6% full). Crawled Internet Movie Database (IMDb) –Extracted content for titles in EachMovie. Basic movie information: –Title, Director, Cast, Genre, etc. Popular opinions: –User comments, Newspaper and Newsgroup reviews, etc..")
28
Content-Boosted Collaborative Filtering IMDb EachMovie Web Crawler Movie Content Database Full User Ratings Matrix Collaborative Filtering Active User Ratings Matrix (Sparse) Content-based Predictor Recommendations
 Content-based Predictor Recommendations")
29
Content-Boosted CF - I Content-Based Predictor Training Examples Pseudo User-ratings Vector Items with Predicted Ratings User-ratings Vector User-rated Items Unrated Items

30
Content-Boosted CF - II Compute pseudo user ratings matrix –Full matrix – approximates actual full user ratings matrix Perform CF –Using Pearson corr. between pseudo user-rating vectors This works better than either! User Ratings Matrix Pseudo User Ratings Matrix Content-Based Predictor

31
Why can’t the pseudo ratings be used to help content-based filtering? How about using the pseudo ratings to improve a content-based filter itself? (or how access to unlabelled examples improves accuracy…) –Learn a NBC classifier C 0 using the few items for which we have user ratings –Use C 0 to predict the ratings for the rest of the items –Loop Learn a new classifier C 1 using all the ratings (real and predicted) Use C 1 to (re)-predict the ratings for all the unknown items –Until no change in ratings With a small change, this actually works in finding a better classifier! –Change: Keep the class posterior prediction (rather than just the max class) This means that each (unlabelled) entity could belong to multiple classes—with fractional membership in each We weight the counts by the membership fractions –E.g. P(A=v|c) = Sum of class weights of all examples in c that have A=v divided by Sum of class weights of all examples in c This is called expectation maximization –Very useful on web where you have tons of data, but very little of it is labelled –Reminds you of K-means, doesn’t it? (no coincidence—K-means is “hard-assignment” EM) Unlabeled examples help only when they are drawn from the same distribution as the labeled ones..
 –Learn a NBC classifier C 0 using the few items for which we have user ratings –Use C 0 to predict the ratings for the rest of the items –Loop Learn a new classifier C 1 using all the ratings (real and predicted) Use C 1 to (re)-predict the ratings for all the unknown items –Until no change in ratings With a small change, this actually works in finding a better classifier. –Change: Keep the class posterior prediction (rather than just the max class) This means that each (unlabelled) entity could belong to multiple classes—with fractional membership in each We weight the counts by the membership fractions –E.g. P(A=v|c) = Sum of class weights of all examples in c that have A=v divided by Sum of class weights of all examples in c This is called expectation maximization –Very useful on web where you have tons of data, but very little of it is labelled –Reminds you of K-means, doesn’t it. (no coincidence—K-means is hard-assignment EM) Unlabeled examples help only when they are drawn from the same distribution as the labeled ones...")
33
(boosted) content filtering
 content filtering")
34
Co-Training Motivation Learning methods need labeled data –Lots of pairs –Hard to get… (who wants to label data?) But unlabeled data is usually plentiful… –Could we use this instead??????
 But unlabeled data is usually plentiful… –Could we use this instead")
35
Co-training Suppose each instance has two parts: x = [x1, x2] x1, x2 conditionally independent given f(x) Suppose each half can be used to classify instance f1, f2 such that f1(x1) = f2(x2) = f(x) Suppose f1, f2 are learnable f1 H1, f2 H2, learning algorithms A1, A2 Unlabeled Instances [x1, x2] Labeled Instances A1 f2 Hypothesis ~ A2 Small labeled data needed You train me—I train you…
![Co-training Suppose each instance has two parts: x = [x1, x2] x1, x2 conditionally independent given f(x) Suppose each half can be used to classify instance f1, f2 such that f1(x1) = f2(x2) = f(x) Suppose f1, f2 are learnable f1 H1, f2 H2, learning algorithms A1, A2 Unlabeled Instances [x1, x2] Labeled Instances A1 f2 Hypothesis ~ A2 Small labeled data needed You train me—I train you…](http://images.slideplayer.com/11/3277978/slides/slide_35.jpg "Co-training Suppose each instance has two parts: x = [x1, x2] x1, x2 conditionally independent given f(x) Suppose each half can be used to classify instance f1, f2 such that f1(x1) = f2(x2) = f(x) Suppose f1, f2 are learnable f1 H1, f2 H2, learning algorithms A1, A2 Unlabeled Instances [x1, x2] Labeled Instances A1 f2 Hypothesis ~ A2 Small labeled data needed You train me—I train you…")
36
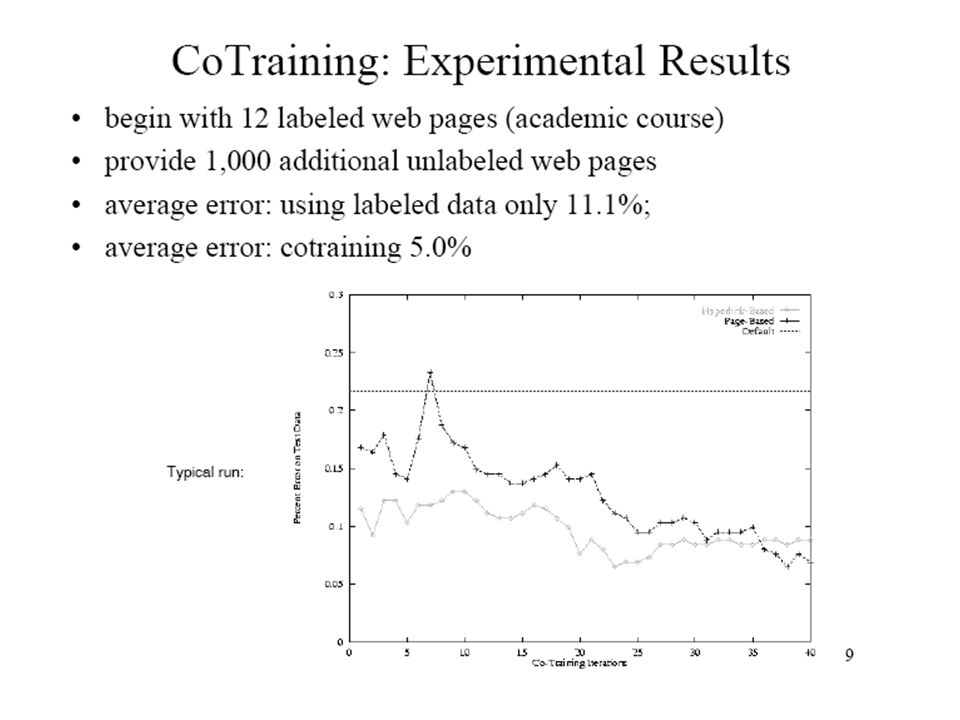
It really works! Learning to classify web pages as course pages –x1 = bag of words on a page –x2 = bag of words from all anchors pointing to a page Naïve Bayes classifiers –12 labeled pages –1039 unlabeled

37
Observations Can apply A1 to generate as much training data as one wants –If x1 is conditionally independent of x2 / f(x), –then the error in the labels produced by A1 – will look like random noise to A2 !!! Thus no limit to quality of the hypothesis A2 can make

39
Focussed Crawling Cho paper –Looks at heuristics for managing URL queue –Aim1: completeness –Aim2: just topic pages Prioritize if word in anchor / URL Heuristics: –Pagerank –#backlinks

40
Modified Algorithm Page is hot if: –Contains keyword in title, or –Contains 10 instances of keyword in body, or –Distance(page, hot-page) < 3
 < 3")
41
Results

42
More Results

43
Conclusions Recommending and personalization are important approaches to combating information over-load. Machine Learning is an important part of systems for these tasks. Collaborative filtering has problems. Content-based methods address these problems (but have problems of their own). Integrating both is best. –Which lead us to discuss some approaches that wind up using unlabelled data along with labelled data to improve performance.
. Integrating both is best. –Which lead us to discuss some approaches that wind up using unlabelled data along with labelled data to improve performance..")
44
Discussion of the Google News Collaborative Filtering Paper

45
Advertising Advertising is a sort of paid recommendation –While

Similar presentations











![Sean Blong Presents: 1. What are they…? “[…] specific type of information filtering (IF) technique that attempts to present information items (movies,](/14/4489892/big_thumb.jpg "Sean Blong Presents: 1. What are they…? “[…] specific type of information filtering (IF) technique that attempts to present information items (movies,>")








