Download presentation
Presentation is loading. Please wait.

1
AMMBR from xtreg to xtmixed (+checking for normality, random slopes)
")
2
xtreg (with assumption checking)
")
3
We knew already ... We have the standard regression model (here with only one x): but think that the data are clustered, and that the intercept (c0) might be different for different clusters … where the S-variables are dummies per cluster. Because k can be large, this is not always feasible to estimate. Instead we estimate: … with the delta normally distributed with zero mean and variance to be estimated.
 might be different. for different clusters. … where the S-variables are dummies per cluster. Because k can be large, this is not always feasible to estimate. Instead we estimate: … with the delta normally distributed with zero mean and variance to be estimated.")
4
And this you can do with xtreg
xtset <clustervariable> xtreg y x1 … and by doing this, we are trying to take into account the fact that the errors are otherwise not independent.

5
A note on xtreg: Replacing the dummies by a delta
This is only allowed when the dummies themselves follow a normal distribution TO CHECK THIS: First run your model with all the dummies included (if possible – might not be feasible) Then check whether the coefs of these dummies follow a normal distribution through the following Stata-code:
 Then check whether the coefs of these dummies follow a normal distribution through the following Stata-code:")
6
Run a regression (with numbered dummies) reg y d2. d40 x1 x2
* Run a regression (with numbered dummies) reg y d2 ... d40 x1 x2 * Write the coefficients to a new variable gen coef = . forvalues i=2/40 { replace coef = _b[d`i’] if _n==`i’ } OR: for num 2/40: replace coef = _b[dX] if _n==X swilk coef // test for normality
 reg y d2 ... d40 x1 x2 * Write the coefficients to a new variable gen coef = . forvalues i=2/40 { replace coef = _b[d`i’] if _n==`i’ } OR: for num 2/40: replace coef = _b[dX] if _n==X swilk coef // test for normality")
7
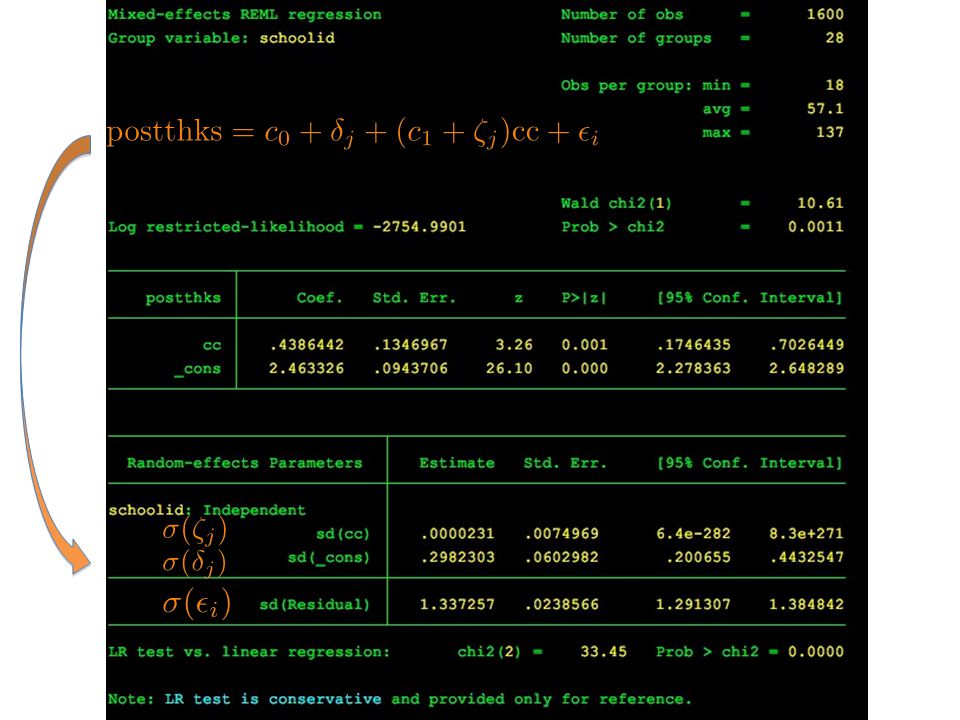
xtmixed

8
What if c1 varies as well? The same argument applies. We already had:
… and now make the c1 coefficient dependent on the cluster (“random slopes”) This is not feasible to estimate for large k, so instead we want to model: … with zeta a normally distributed variable with zero mean and variance to be estimated
 This is not feasible to estimate for large k, so instead we want to model: … with zeta a normally distributed variable with zero mean and variance to be estimated.")
9
And this you can do with xtmixed
xtmixed y x1 || <clustervar>: is just like the xtreg command, but if you want random slopes for x1, you add x1 after the “:” xtmixed y x1 || <clustervar>: x1 Your output then gives you estimates for the variance (or standard deviation) of delta and zeta.
 of delta and zeta.")
11
xtmixed can deal with nested clusters too
xtmixed can deal with nested clusters too! (here: “classes within schools”) Again the same kind of argument applies. We already had: … and we want separate constant terms per class and per school So we estimate instead: … where delta is again a normally distributed variable at the school level with zero mean and variance to be estimated, and tau is a normally distributed variable at the class level with zero mean and variance to be estimated.
 Again the same kind of argument applies. We already had: … and we want separate constant terms per class and per school. So we estimate instead: … where delta is again a normally distributed variable at the school level with zero mean and variance to be estimated, and tau is a normally distributed variable at the class level with zero mean and variance to be estimated.")
12
And this you can do with xtmixed as well
xtmixed y x1 || school: || class: Remember to put the bigger cluster on the left!

14
[show this in Stata] (compare empty xtmixed with xtreg)
![[show this in Stata] (compare empty xtmixed with xtreg)](http://slideplayer.com/slide/3277410/11/images/14/%5Bshow+this+in+Stata%5D+%28compare+empty+xtmixed+with+xtreg%29.jpg "[show this in Stata] (compare empty xtmixed with xtreg)")
15
Horrors xtmixed finds its estimates using an iterative process.
(first: you now have a wealth of opportunities with clustered data. All effects might depend on any cluster-level.) xtmixed finds its estimates using an iterative process. This can complicate matters: it might not converge it might converge but to the wrong values (and you can’t tell) it might converge to different estimates for different algorithms in the iterative process You have only a couple of weapons against that: run again using a different algorithm (use option “, mle”) Allow estimation of correlations as well (use option “, cov(unstr)”) run the dummy-variant (with lots of dummies) anyway I do not know if any of these horrors will happen in the data you get! This is also something you can pre-check yourselves.
 xtmixed finds its estimates using an iterative process. This can complicate matters: it might not converge. it might converge but to the wrong values (and you can’t tell) it might converge to different estimates for different algorithms in the iterative process. You have only a couple of weapons against that: run again using a different algorithm (use option , mle ) Allow estimation of correlations as well (use option , cov(unstr) ) run the dummy-variant (with lots of dummies) anyway. I do not know if any of these horrors will happen in the data you get! This is also something you can pre-check yourselves.")
16
Splitting up variables (within vs across clusters)
Basically this is completely unrelated to the previous. The important thing is that it can be done in clustered data, and can lead to different interpretations (see before) Do note that if you have three levels (pupils within classes within schools) then you can average out on each level …
 Do note that if you have three levels (pupils within classes within schools) then you can average out on each level …")
17
More to do ... Multilevel data and Y = binary xtlogit
Multilevel data and levels are not nested “cross-classified” multilevel models xtmixed The random utility model clogit

18
Exam approaching ... PRACTICE!

Similar presentations




 (checking for normality, random slopes)>")





 Advanced Panel Data Method>")



: but think that the data are clustered, and that the intercept (c.>")

 Conjoint analysis Coming up: Multi-level.>")

 is weight for.>")
>")
