Download presentation
Presentation is loading. Please wait.

1
An Array-Based Algorithm for Simultaneous Multidimensional Aggregates By Yihong Zhao, Prasad M. Desphande and Jeffrey F. Naughton Presented by Kia Hall for CIS 661 (taught by Professor Megalooikonomou)
.")
2
Outline of Presentation Purpose of Paper ROLAP vs. MOLAP systems Array Storage Basic Array-Based Algorithm Multi-Way Array Algorithm –Single Pass –Multi-Pass Performance Conclusions

3
Purpose Computing multiple related group-bys and aggregates is one of the core operations of On-Line Analytical Processing (OLAP) applications. The “Cube” operator computes group-by aggregates over all possible subsets of the specified dimensions. The purpose of this paper is to present an efficient algorithm to compute the Cube for Multidimensional OLAP (MOLAP) systems. Although is designed for MOLAP systems it can also be used for Relational OLAP (ROLAP) systems when table data is converted to an array, cubed as if in a MOLAP system, and then converted back to a table.
 systems. Although is designed for MOLAP systems it can also be used for Relational OLAP (ROLAP) systems when table data is converted to an array, cubed as if in a MOLAP system, and then converted back to a table..")
4
“Cube” example Consider an example with dimensions product, store and date, and “measure” (data value) sales. To compute the “Cube” would be to compute sales grouped by all subsets of these dimensions, which include the following: –By product, store and date –By product and store, By product and date, By store and date –By product, By sales, By date –Overall Sales

5
ROLAP vs. MOLAP systems ROLAP systems by definition use relational tables as their data structure A “cell” is represented in the system as a tuple, with some attributes that identify the location of the tuple in the multidimensional space, and other attributes that contain the data value corresponding to that data cell MOLAP systems store their data as sparse arrays, the the data’s position within the sparse array encoding the relevant attribute information Critical to MOLAP efficiency in computing the “Cube” is to simultaneously compute spatially-delimited partial aggregates so that a cell does not have to be revisited for each sub-aggregate.

6
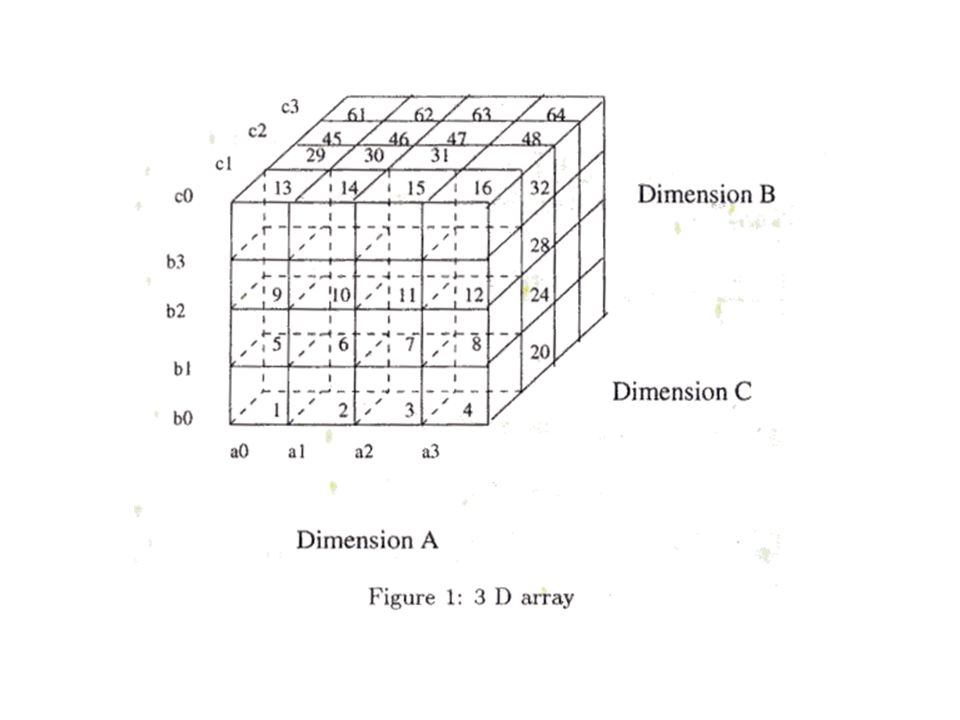
Array Storage There are three major issues relating to the storage of the array that must be resolved –It is likely in a multidimensional application that the array is too large to fit in memory –It is likely that many of the cells in the array are empty, because there is no data for that combination of coordinates –In many cases an array will need to be loaded from data that is not in array format (e.g., from a relational table or from an external load file)
")
7
Resolving Storage Issues A large n-dimensional array that can not fit into memory is divided into small size n-dimensional (corresponding to disk blocking size) chunks and each chunk is stored as one object on disk Sparse chunks (with data density less than 40%) use a “chunk-offset compression” where for each valid array entry a pair, (offsetInChunk, data), is stored To load data from formats other than arrays, a partition- based loading algorithm is used that takes as input the table, each dimension size and a predefined chunk size, and returns a (possibly compressed) chunked array
 chunks and each chunk is stored as one object on disk Sparse chunks (with data density less than 40%) use a chunk-offset compression where for each valid array entry a pair, (offsetInChunk, data), is stored To load data from formats other than arrays, a partition- based loading algorithm is used that takes as input the table, each dimension size and a predefined chunk size, and returns a (possibly compressed) chunked array")
8
Efficient Computation The basic algorithm (which will be improved upon) computes the cube of a chunked array in multiple passes, computing each “group-by” in a separate pass For a three-dimensional array (with dimensions ABC) the aggregates to be computed can be viewed as a lattice with ABC at the root, with AB, BC, and AC as children; with AC having children A and C, and so forth. To compute the cube efficiently a tree is embedded in this lattice and each aggregate is computed from its parent in the tree

9
Minimum Spanning Tree From the dimension sizes of the array and the sizes of the chunks used to store the array, the following can be computed –The size of the array corresponding to each node in the lattice –How much storage will be needed to use one of these arrays to compute a child From the above information a minimum spanning tree can be defined For each node n in the lattice, its parent in the minimum spanning tree is the node n’ which has the minimum size and from which n can be computed

10
Basic Array Cubing Algorithm 1.Construct the minimum size spanning tree for the group- bys of the Cube 2.Compute any group-by D i1 D i2... D ik of a Cube from the “parent” D i1 D i2... D ik+1 which has the minimum size 3.Read in each chunk of D i1 D i2... D ik+1 along the dimension D ik+1 and aggregate each chunk to a chunk of D i1 D i2... D ik 4.Once the chunk of D i1 D i2... D ik is complete, we output the chunk to disk and use the memory for for the next chuck of D i1 D i2... D ik, keeping only one chunk in memory at a time

12
Efficiency Improvement To improve on the basic algorithm we want to modify it to compute all the children of a parent in a single pass of the parent A data Cube for an n-dimensional array consists of 2 n group-bys. Ideally, if the memory were large enough hold all group-bys, total overlap could be achieved and the Cube would be finished with one scan of the array The “Multi-Way Array Cubing Algorithm” attempts to minimize the memory needed for each computation, so that maximum overlap can be achieved The single pass version of this algorithm assumes ideal memory; the multi-pass modification, realistically supposes that multiple passes may be necessary

13
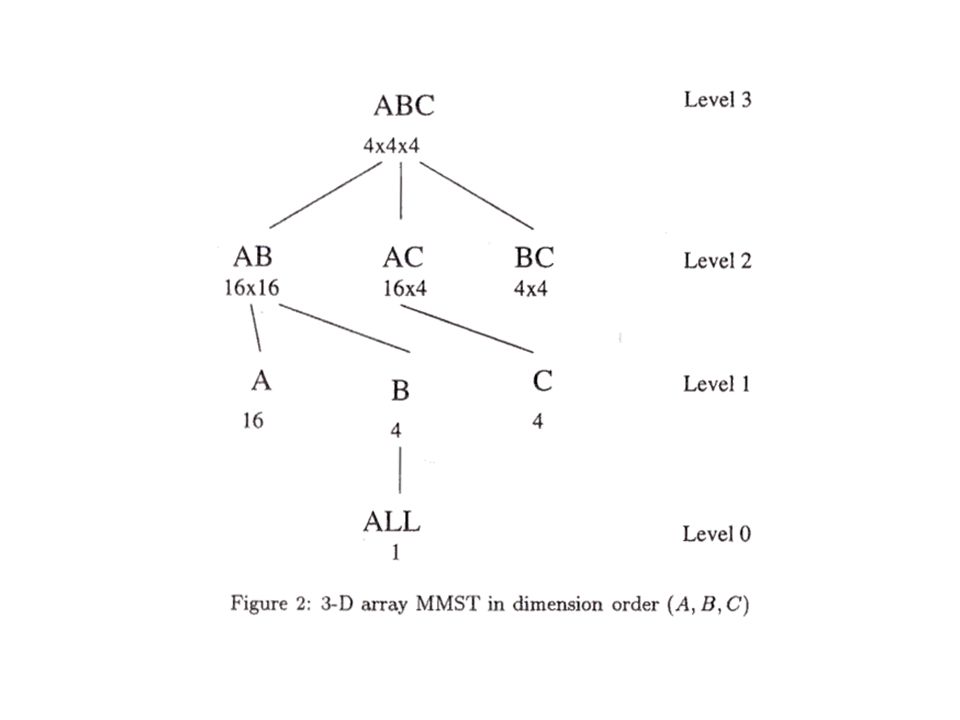
Dimension Order and Memory The logical order used in reading in an array of chunks is the “dimension order”; this order is independent of the actual physical order Dimension order should be exploited to reduce the memory required by each group-by Once the dimension order is determined, a general rule can be formulated to determine what chunks of each group-by need to stay in memory to avoid rescanning By theorem, optimal dimension order for an array A, with dimensions D 1 D 2... D k is O = D 1, D 2,..., D k.

15
Memory Allocation Rule Memory Allocation Rule 1: For a group-by (D j1... D jn-1 ) of the array (D 1,..., D n ) read in the dimension order O = D 1, D 2,..., D k, if (D j1... D jn-1 ) contains a prefix of (D 1,..., D n ) with length p, 0 p n-1, we allocate p i=1 | D i | x n-1 i=p+1 | C i | units of array element to (D j1... D jn-1 ) group-by, where | D i | is the size of dimension i and | C i | is the chunk size of dimension I This memory allocation rule is used to build a Minimum Memory Spanning Tree (MMST)
 of the array (D 1,..., D n ) read in the dimension order O = D 1, D 2,..., D k, if (D j1... D jn-1 ) contains a prefix of (D 1,..., D n ) with length p, 0 p n-1, we allocate p i=1 | D i | x n-1 i=p+1 | C i | units of array element to (D j1... D jn-1 ) group-by, where | D i | is the size of dimension i and | C i | is the chunk size of dimension I This memory allocation rule is used to build a Minimum Memory Spanning Tree (MMST).")
16
Minimum Memory Spanning Trees A MMST for a Cube (D 1,..., D n ) in a dimension order O=(D j1,..., D jn ) has n+1 levels with the root (D j1,..., D jn ) at level n Using the first rule, the memory required at each level of a Minimum Memory Spanning Tree (MMST) can be calculated using the following memory rule: Memory Allocation Rule 2: The total memory requirement for level j of the MMST for a dimension order O=(D 1,..., D n ) is given by: – n-j i=1 | D i | + C(j, 1)( n-j-1 i=1 | D i |)c + C(j+1, 2)( n-j-2 i=1 | D i |)c 2 +... + C(n-1, n-j)c n-j
c n-j.")
18
Single Pass Multi-Way Cubing Algorithm The single pass algorithm assumes there is sufficient memory required by the MMST In this case, all group-bys can be computed recursively in a single scan of the input array By theorem, the required memory is computed as follows: –Theorem: For a chunked multidimensional array A with the size n i=1 |D i | where |D i | =d for all i, and each array chunk has the size n i=1 |C i | where |C i | =c for all i, the total amount of memory to compute the Cube of the array in one scan of A is less than c n +(d+1+c) n-1.
 n-1.")
19
Multi-Pass Multi-Way Cubing Algorithm Let T be the MMST for the optimal dimension ordering O and M T be the memory required for T, calculated using Memory Allocation Rule 2 If M M T, we cannot allocate the required memory for some of the subtrees of the MMST, called “incomplete trees.” Extra steps are required to compute the group-bys included in incomplete trees

20
Multi-Pass Multi-Way Algorithm (cont) 1.Create the MMST for a dimension order O 2.Add T to the ToBeComputed List 3.For each tree T’ in the ToBeComputed List 4.{Create the working subtree W and incomplete subtrees Is 5.Allocate memory to the subtrees 6.Scan the array chunk of the root of T’ in the order O 7.{Aggregate each chunk to the group-bys in W 8.Generate intermediate results for Is 9.Write complete chunks of W to disk 10.Write intermediate results to the partitions of Is } 11.For each I 12.{Generate the chunks from the partitions of I 13.Write the completed chunks of I 14.Add I to ToBeComputed }
 1.Create the MMST for a dimension order O 2.Add T to the ToBeComputed List 3.For each tree T’ in the ToBeComputed List 4.{Create the working subtree W and incomplete subtrees Is 5.Allocate memory to the subtrees 6.Scan the array chunk of the root of T’ in the order O 7.{Aggregate each chunk to the group-bys in W 8.Generate intermediate results for Is 9.Write complete chunks of W to disk 10.Write intermediate results to the partitions of Is } 11.For each I 12.{Generate the chunks from the partitions of I 13.Write the completed chunks of I 14.Add I to ToBeComputed }")
21
Testing Conditions Testing was done using three data sets in which one of the following attributes varied, while the other two remained constant: –Number of valid data entries –Dimension size –Number of dimensions A popular ROLAP (table) cubing algorithm was compared with the MOLAP (array) Multi-Way Algorithm The MOLAP Algorithm consistently had better performance time
 cubing algorithm was compared with the MOLAP (array) Multi-Way Algorithm The MOLAP Algorithm consistently had better performance time")
22
ROLAP vs. MOLAP Performance The data table sizes are significantly larger than the compressed arrays (and compressed chunks) of MOLAP A significant percentage of time (55-60%) is spent sorting intermediate results Tuple comparisons are expensive because there are multiple fields to be compared About 10-12% is spent copying data, done while generating result tuples Since is MOLAP is position-based cells of the array are aggregated based on their position without multiple sorts The MOLAP Algorithm is relatively CPU intensive (80%) as compared with the ROLAP Algorithm (70%)
 of MOLAP A significant percentage of time (55-60%) is spent sorting intermediate results Tuple comparisons are expensive because there are multiple fields to be compared About 10-12% is spent copying data, done while generating result tuples Since is MOLAP is position-based cells of the array are aggregated based on their position without multiple sorts The MOLAP Algorithm is relatively CPU intensive (80%) as compared with the ROLAP Algorithm (70%).")
24
Conclusion Multi-Way Array Algorithm overlaps the computation of different group-bys, while using minimal memory for each group-by. Performance results show that the Algorithm performs much better than previously published ROLAP algorithms The performance benefits are so substantial that in the testing done for this paper it was faster to load an array from a table, cube the array, then dump the cubed array into tables than to cube the table directly. Thus, the Algorithm is valuable in both ROLAP and MOLAP systems

Similar presentations









 Yonsei University 2 nd Semester, 2013 Sanghyun Park.>")
 Andrew Rau-Chaplin Faculty of Computer Science Dalhousie University Joint Work with F. Dehne T. Eavis S. Hambrusch.>")









 and a real system. –Optimize for CPU, space, and logging. But things have changed drastically! Hardware trend:>")
