Download presentation
Presentation is loading. Please wait.

1
Threads Cannot be Implemented As a Library Andrew Hobbs

2
As a library...what does that mean? Language specification doesn't say anything about it The specification defines what compilers should do So the compiler doesn't know about them either

3
How does this affect programming? The compiler transforms your code to hopefully make it as fast as possible It has some restrictions, depending on the language specification But if the compiler doesn't know about concurrency... It can make optimizations that are valid in sequential programs, but can cause bugs in multiprocessor environments

4
An example x = 1; r1 = y; Thread 1: Thread 2: y = 1; r2 = x; What are the possible values of r1 and r2 at the end of both threads executing? Assuming x and y are both set to 0, suppose we have 2 threads:

5
An example r1 = y; x = 1; Thread 1: Thread 2: r2 = x; y = 1; What are the possible values of r1 and r2 at the end of both threads executing? This results could turn out differently...but from the compiler's view, everything is fine, because it doesn't know each thread can interact with others. But what if our compiler changes our code to the following?

6
Why did this happen? The compiler didn't know about concurrency, so it performed optimizations assuming sequential execution Some of these don't work with concurrency! In fact, the hardware itself can also do this in an attempt to speed up execution, by (for example) putting loads before unrelated stores
 putting loads before unrelated stores.")
7
The Pthreads approach No threads shall read or modify memory that another thread is modifying (such an activity is called a race condition) To restrict access, the programmer uses synchronization routines: pthread_mutex.lock() pthread_mutex.unlock() …
 To restrict access, the programmer uses synchronization routines: pthread_mutex.lock() pthread_mutex.unlock() …")
8
The Pthreads approach If the programmer uses the synchronization methods correctly to prevent race conditions, then they should have no issues But this isn't quite true...

9
Concurrent modification if (x == 1) ++y; Thread 1: Thread 2: if (y == 1) ++x; Is there a data race in this program? Suppose we had the following two threads:

10
Concurrent modification ++y; if (x != 1) --y; Thread 1: Thread 2: ++x; if (y != 1) --x; Is there a data race in this program? What if our compiler modified our code a little?

11
Adjacent data { tmp = x; // Read both fields into // 32-bit variable tmp &= ~0x1ffff; // Mask off old a tmp |= 42; x = tmp; // Overwrite all of x } There are probably no machines that have a 17-bit wide store, so if someone were to attempt to execute: x.a = 42; it would probably be done like this: Suppose we had the following structure definition: struct { int a:17; int b:15 } x;

12
Adjacent data x.b = ’b’; x.c = ’c’; x.d = ’d’; x.e = ’e’; x.f = ’f’; x.g = ’g’; x.h = ’h’; x = ’hgfedcb\0’ | x.a; Where a is the only field that needs to be protected by a lock. If that was the case, some programmer might write the following code: Suppose we had the following structure definition: struct { char a; char b; char c; char d; Char e; char f; char g; char h; } x; But a compiler might realize that it could just write all of the data at once as a 64-bit quantity (not exact syntax):
:.")
13
Register Promotion Suppose we had a global shared variable x, protected by a lock...but only conditionally, perhaps only if we had actually created other threads: for (...) {... if (mt) pthread_mutex_lock(...); x =... x... if (mt) pthread_mutex_unlock(...); } r = x; for (...) {... if (mt) { x = r; pthread_mutex_lock(...); r = x; } r =... r... if (mt) { x = r; pthread_mutex_unlock(...); r = x; } x = r; If the conditionals are rarely taken, it might decide to promote x to a register to increase the performance:
 pthread_mutex_lock(...); x =... x... if (mt) pthread_mutex_unlock(...); } r = x; for (...) {... if (mt) { x = r; pthread_mutex_lock(...); r = x; } r =... r... if (mt) { x = r; pthread_mutex_unlock(...); r = x; } x = r; If the conditionals are rarely taken, it might decide to promote x to a register to increase the performance:.")
14
What does this mean? Pthreads says that as long as we prevent race conditions with the synchronization functions, we will be fine But since our compiler doesn't know, it might make optimizations that break it, even though it looks perfectly fine to us We can't use locks at a high level if the presence of race conditions depends on the compiler and the hardware

15
Performance So why are we running multiple threads? To (hopefully) get better performance out of our program But locking is expensive! Atomic updates are hundreds of times slower than normal ones
 get better performance out of our program But locking is expensive. Atomic updates are hundreds of times slower than normal ones.")
16
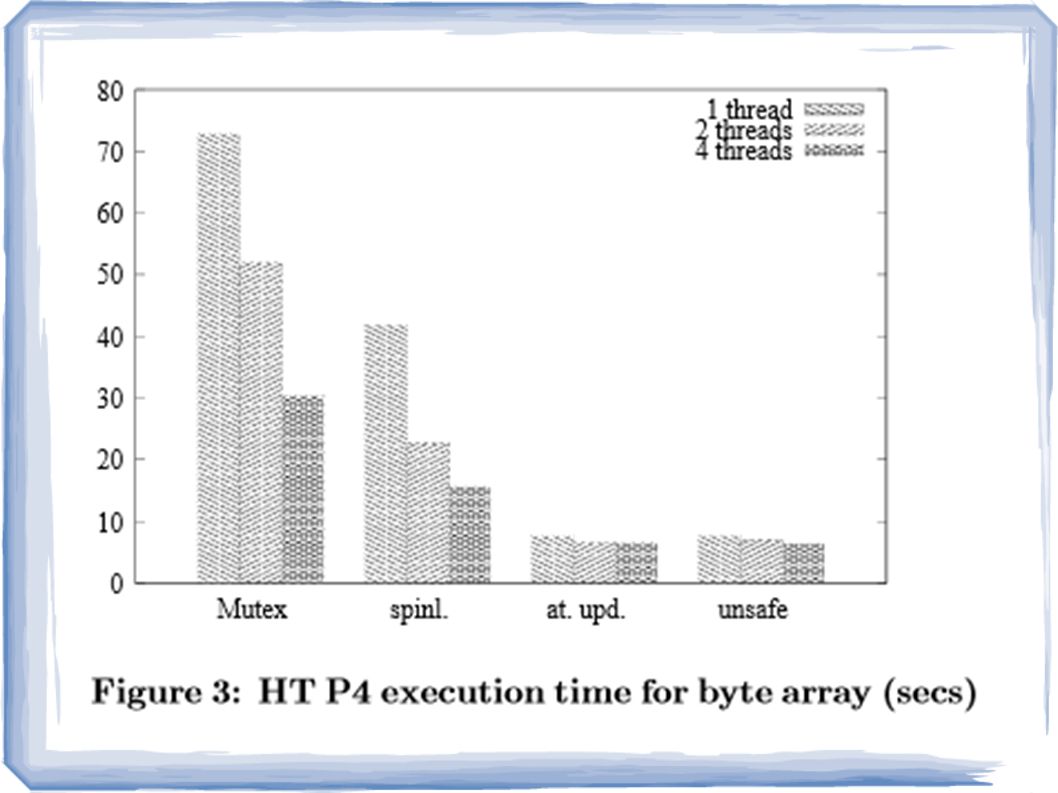
Is synchronization always needed? Consider the following Sieve of Eratosthenes implementation: for (my_prime = start; my_prime < 10000; ++my_prime) if (!get(my_prime)) { for (multiple = my_prime; multiple < 100000000; multiple += my_prime) if (!get(multiple)) set(multiple); } What happens if we run this on multiple threads, with all of them accessing one shared data block?
 if (!get(my_prime)) { for (multiple = my_prime; multiple < ; multiple += my_prime) if (!get(multiple)) set(multiple); } What happens if we run this on multiple threads, with all of them accessing one shared data block .")
21
The conclusions? Sometimes there are times when you can gain large performance benefits without directly using atomic operations But if we use a library that disallows this (like Pthreads), we are throwing away this ability But we are allowed to, then we need the compiler and hardware to somehow know about it and help us
, we are throwing away this ability But we are allowed to, then we need the compiler and hardware to somehow know about it and help us.")
22
The conclusions? So how do we get the compiler and hardware to help us? We need to have the programming language itself define a memory model so that the programmer knows whether there are races Only if we have that can we reason about our programs

Similar presentations




 must be mutually.>")
 Ding Yuan ECE Dept., University of Toronto>")

 2015-04-17. 7.I Background F Producer - Consumer process : Compiler, Assembler, Loader, · · · · · · F Bounded buffer.>")
: Synchronization.>")













, in the same.>")