Download presentation
Presentation is loading. Please wait.

1
Untangling Text Data Mining Marti Hearst UC Berkeley SIMS ACL’99 Plenary Talk June 23, 1999

2
Outline l Untangling several different fields –DM, CL, IA, TDM l TDM examples l TDM as Exploratory Data Analysis –New Problems for Computational Linguistics –Our current efforts

3
Classifying Application Types

4
What is Data Mining? (Fayyad & Uthurusamy 96, Fayyad 97) l Fitting models to or determining patterns from very large datasets. l A “regime” which enables people to interact effectively with massive data stores. l Deriving new information from data.
 l Fitting models to or determining patterns from very large datasets. l A regime which enables people to interact effectively with massive data stores. l Deriving new information from data..")
5
Why Data Mining? l Because the data is there. l Because –larger disks –faster cpus –high-powered visualization –networked information are becoming widely available.

6
The Knowledge Discovery from Data Process (KDD) KDD: The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data. (Fayyad, Shapiro, & Smyth, CACM 96) Note: data mining is just one step in the process
 Note: data mining is just one step in the process.")
7
DM Touchstone Applications (CACM 39 (11) Special Issue) l Finding patterns across data sets: –Reports on changes in retail sales »to improve sales –Patterns of sizes of TV audiences »for marketing –Patterns in NBA play »to alter, and so improve, performance –Deviations in standard phone calling behavior »to detect fraud »for marketing
 Special Issue) l Finding patterns across data sets: –Reports on changes in retail sales »to improve sales –Patterns of sizes of TV audiences »for marketing –Patterns in NBA play »to alter, and so improve, performance –Deviations in standard phone calling behavior »to detect fraud »for marketing")
8
What is Data Mining? Potential point of confusion: –The extracting ore from rock metaphor does not really apply to the practice of data mining –If it did, then standard database queries would fit under the rubric of data mining –In practice, DM refers to: »finding patterns across large datasets »discovering heretofore unknown information

9
What is Text Data Mining? l Many peoples’ first thought: –Make it easier to find things on the Web. –But this is information retrieval!

10
Needles in Haystacks The emphasis in IR is in finding documents that already contain answers to questions.

11
Information Retrieval A restricted form of Information Access l The system has available only pre-existing, “canned” text passages. l Its response is limited to selecting from these passages and presenting them to the user. l It must select, say, 10 or 20 passages out of millions.

12
What is Text Data Mining? l The metaphor of extracting ore from rock: – Does make sense for extracting documents of interest from a huge pile. –But does not reflect notions of DM in practice: »finding patterns across large collections »discovering heretofore unknown information

13
Real Text DM What would finding a pattern across a large text collection really look like?

14
From: “The Internet Diary of the man who cracked the Bible Code ” Brendan McKay, Yahoo Internet Life, www.zdnet.com/yil (William Gates, agitator, leader) Bill Gates + MS-DOS in the Bible!
 Bill Gates + MS-DOS in the Bible!")
15
From: “The Internet Diary of the man who cracked the Bible Code” Brendan McKay, Yahoo Internet Life, www.zdnet.com/yil

16
Real Text DM l The point: –Discovering heretofore unknown information is not what we usually do with text. –(If it weren’t known, it could not have been written by someone!) l However: –There is a field whose goal is to learn about patterns in text for their own sake...
 l However: –There is a field whose goal is to learn about patterns in text for their own sake....")
17
Computational Linguistics! l Goal: automated language understanding –this isn’t possible –instead, go for subgoals, e.g., »word sense disambiguation »phrase recognition »semantic associations l Common current approach: –statistical analyses over very large text collections

18
Why CL Isn’t TDM l A linguist finds it interesting that “cloying” co-occurs significantly with “Jar Jar Binks”... l … But this doesn’t really answer a question relevant to the world outside the text itself.

19
Why CL Isn’t TDM l We need to use the text indirectly to answer questions about the world l Direct: –Analyze patent text; determine which word patterns indicate various subject categories. l Indirect: –Analyze patent text; find out whether private or public funding leads to more inventions.

20
Why CL Isn’t TDM l Direct: –Cluster newswire text; determine which terms are predominant l Indirect: –Analyze newswire text; gather evidence about which countries/alliances are dominating which financial sectors

21
Nuggets vs. Patterns l TDM: we want to discover new information … l … As opposed to discovering which statistical patterns characterize occurrence of known information. l Example: WSD –not TDM: computing statistics over a corpus to determine what patterns characterize Sense S. –TDM: discovering the meaning of a new sense of a word.

22
Nuggets vs. Patterns l Nugget: a new, heretofore unknown item of information. l Pattern: distributions or rules that characterize the occurrence (or non- occurrence) of a known item of information. l Application of rules can create nuggets in some circumstances.
 of a known item of information. l Application of rules can create nuggets in some circumstances..")
23
Example: Lexicon Augmentation l Application of a lexico-syntactic pattern: NP 0 such as NP 1, {NP 2 …, (and | or) NP i } i >= 1, implies that forall NP i, i>=1, hyponym(NP i, NP 0 ) l Extracts out a new hypernym: –“ Agar is a substance prepared from a mixture of red algae, such as Gelidium, for laboratory or industrial use.” –implies hyponym(“Gelidium”, “red algae”) l However, this fact was already known to the author of the text.
 NP i } i >= 1, implies that forall NP i, i>=1, hyponym(NP i, NP 0 ) l Extracts out a new hypernym: – Agar is a substance prepared from a mixture of red algae, such as Gelidium, for laboratory or industrial use. –implies hyponym( Gelidium , red algae ) l However, this fact was already known to the author of the text.")
24
The Quandry l How do we use text to both –Find new information not known to the author of the text –Find information that is not about the text itself

25
Idea: Exploratory Data Analysis l Use large text collections to gather evidence to support (or refute) hypotheses –Not known to author: links across many texts –Not self-referential: work within the domain of discourse
 hypotheses –Not known to author: links across many texts –Not self-referential: work within the domain of discourse")
26
Example: Etiology l Given –medical titles and abstracts –a problem (incurable rare disease) –some medical expertise l find causal links among titles –symptoms –drugs –results
 –some medical expertise l find causal links among titles –symptoms –drugs –results")
27
Swanson Example (1991) l Problem: Migraine headaches (M) –stress associated with M –stress leads to loss of magnesium –calcium channel blockers prevent some M –magnesium is a natural calcium channel blocker –spreading cortical depression (SCD) implicated in M –high levels of magnesium inhibit SCD –M patients have high platelet aggregability –magnesium can suppress platelet aggregability l All extracted from medical journal titles
 l Problem: Migraine headaches (M) –stress associated with M –stress leads to loss of magnesium –calcium channel blockers prevent some M –magnesium is a natural calcium channel blocker –spreading cortical depression (SCD) implicated in M –high levels of magnesium inhibit SCD –M patients have high platelet aggregability –magnesium can suppress platelet aggregability l All extracted from medical journal titles")
28
Gathering Evidence stress migraine CCB magnesium PA magnesium SCD magnesium

29
Gathering Evidence migraine magnesium stress CCB PA SCD

30
Swanson’s TDM l Two of his hypotheses have received some experimental verification. l His technique –Only partially automated –Required medical expertise l Few people are working on this.

31
How to Automate This? l Idea: mixed-initiative interaction –User applies tools to help explore the hypothesis space –System runs suites of algorithms to help explore the space, suggest directions

32
Our Proposed Approach l Three main parts –UI for building/using strategies –Backend for interfacing with various databases and translating different formats –Content analysis/machine learning for figuring out good hypotheses/throwing out bad ones

33
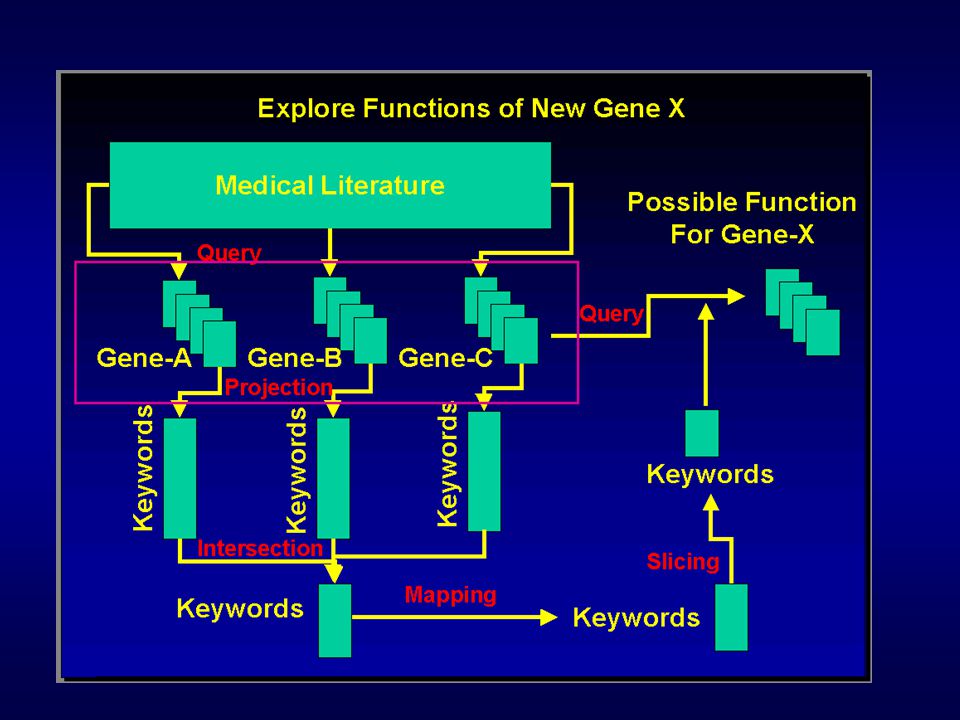
How to find functions of genes? l Important problem in molecular biology –Have the genetic sequence –Don’t know what it does –But … »Know which genes it coexpresses with »Some of these have known function –So … Infer function based on function of co-expressed genes »This is new work by Michael Walker and others at Incyte Pharmaceuticals

34
Gene Co-expression: Role in the genetic pathway g? PSA Kall. PAP h? PSA Kall. PAP g? Other possibilities as well

35
Make use of the literature l Look up what is known about the other genes. l Different articles in different collections l Look for commonalities –Similar topics indicated by Subject Descriptors –Similar words in titles and abstracts adenocarcinoma, neoplasm, prostate, prostatic neoplasms, tumor markers, antibodies...

36
Developing Strategies l Different strategies seem needed for different situations –First: see what is known about Kallikrein. –7341 documents. Too many –AND the result with “disease” category »If result is non-empty, this might be an interesting gene –Now get 803 documents –AND the result with PSA »Get 11 documents. Better!

37
Developing Strategies l Look for commalities among these documents –Manual scan through ~100 category labels –Would have been better if »Automatically organized »Intersections of “important” categories scanned for first

38
Try a new tack l Researcher uses knowledge of field to realize these are related to prostate cancer and diagnostic tests l New tack: intersect search on all three known genes –Hope they all talk about diagnostics and prostate cancer –Fortunately, 7 documents returned –Bingo! A relation to regulation of this cancer

39
Formulate a Hypothesis l Hypothesis: mystery gene has to do with regulation of expression of genes leading to prostate cancer l New tack: do some lab tests –See if mystery gene is similar in molecular structure to the others –If so, it might do some of the same things they do

40
Strategies again l In hindsight, combining all three genes was a good strategy. –Store this for later l Might not have worked –Need a suite of strategies –Build them up via experience and a good UI

42
The System l Doing the same query with slightly different values each time is time- consuming and tedious l Same goes for cutting and pasting results –IR systems don’t support varying queries like this very well. –Each situation is a bit different l Some automatic processing is needed in the background to eliminate/suggest hypotheses

43
The UI part l Need support for building strategies l Mixed-initiative system –Trade off between user-initiated hypotheses exploration and system-initiated suggestions l Information visualization –Another way to show lots of choices

44
Candidate Associations Current Retrieval Results Suggested Strategies

45
LINDI: Linking Information for Novel Discovery and Insight l Just starting up now (fall 98) l Initial work: Hao Chen, Ketan Mayer- Patel, Shankar Raman
 l Initial work: Hao Chen, Ketan Mayer- Patel, Shankar Raman")
46
Summary l The future: analyzing what the text is about –We don’t know how; text is tough! –Idea: bring the user into the loop. –Build up piecewise evidence to support hypotheses –Make use of partial domain models. l The Truth is Out There!

47
Summary l Text Data Mining: –Extracting heretofore undiscovered information from large text collections l Information Access TDM –IA: locating already known information that is currently of interest l Finding patterns across text is already done in CL –Tells us about the behavior of language –Helps build very useful tools!

48
Text Merging Example: Discovering Hypocritical Congresspersons

49
Discovering Hypocritical Congresspersons l Feb 1, 1996 –US House of Reps votes to pass Telecommunications Reform Act –this contains the CDA (Communications Decency Act) –violaters subject to fines of $250,000 and 5 years in prison –eventually struck down by court
 –violaters subject to fines of $250,000 and 5 years in prison –eventually struck down by court")
50
Discovering Hypocritical Congresspersons l Sept 11, 1998 –US House of Reps votes to place the Starr report online –the content would (most likely) have violated the CDA l 365 people were members for both votes –284 members voted aye both times »185 (94%) Republicants voted aye both times » 96 (57%) Democrats voted aye both times
 have violated the CDA l 365 people were members for both votes –284 members voted aye both times »185 (94%) Republicants voted aye both times » 96 (57%) Democrats voted aye both times")
53
How to find Hypocritical Congresspersons? l This must have taken a lot of work –Hand cutting and pasting –Lots of picky details »Some people voted on one but not the other bill »Some people share the same name l Check for different county/state l Still messed up on “Bono” –Taking stats at the end on various attributes »Which state »Which party l Tools should help streamline, reuse results

54
How to find Hypocritical Congresspersons? l The hard part? –Knowing two compare these two sets of voting records.

Similar presentations




















>")
