Download presentation
Presentation is loading. Please wait.

1
Daniel Cederman and Philippas Tsigas Distributed Computing and Systems Chalmers University of Technology

2
System Model The Algorithm Experiments 5 8 3 23 2235 858

3
System Model The Algorithm Experiments 5 8 3 23 2235 858

4
Normal processorsGraphics processors Multi-core Large cache Few threads Speculative execution Many-core Small cache Wide and fast memory bus Thousands of threads hides memory latency

5
Designed for general purpose computation Extensions to C/C++

6
Global Memory

7
Multiprocessor 0 Multiprocessor 1 SharedMemorySharedMemory

8
Global Memory Multiprocessor 0 Multiprocessor 1 SharedMemorySharedMemory Thread Block 0 Thread Block 1 Thread Block x Thread Block y

9
Minimal, manual cache 32-word SIMD instruction Coalesced memory access No block synchronization Expensive synchronization primitives

10
System Model The Algorithm Experiments 5 8 3 23 2235 858

11
5 8 3 23 2235 858

12
5 8 3 23 2235 858 Data Parallel!

13
5 8 3 23 2235 858 NOT Data Parallel! NOT Data Parallel!

14
5 8 3 23 2235 858 Phase One Sequences divided Block synchronization on the CPU Phase One Sequences divided Block synchronization on the CPU Thread Block 1Thread Block 2

15
5 8 3 23 2235 858 Phase Two Each block is assigned own sequence Run entirely on GPU Phase Two Each block is assigned own sequence Run entirely on GPU Thread Block 1Thread Block 2

16
2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8

17
Assign Thread Blocks 2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8

18
Uses an auxiliary array In-place too expensive 2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8

19
Fetch-And-AddonLeftPointerFetch-And-AddonLeftPointer LeftPointer = 0 Thread Block ONE Thread Block TWO 1 0

20
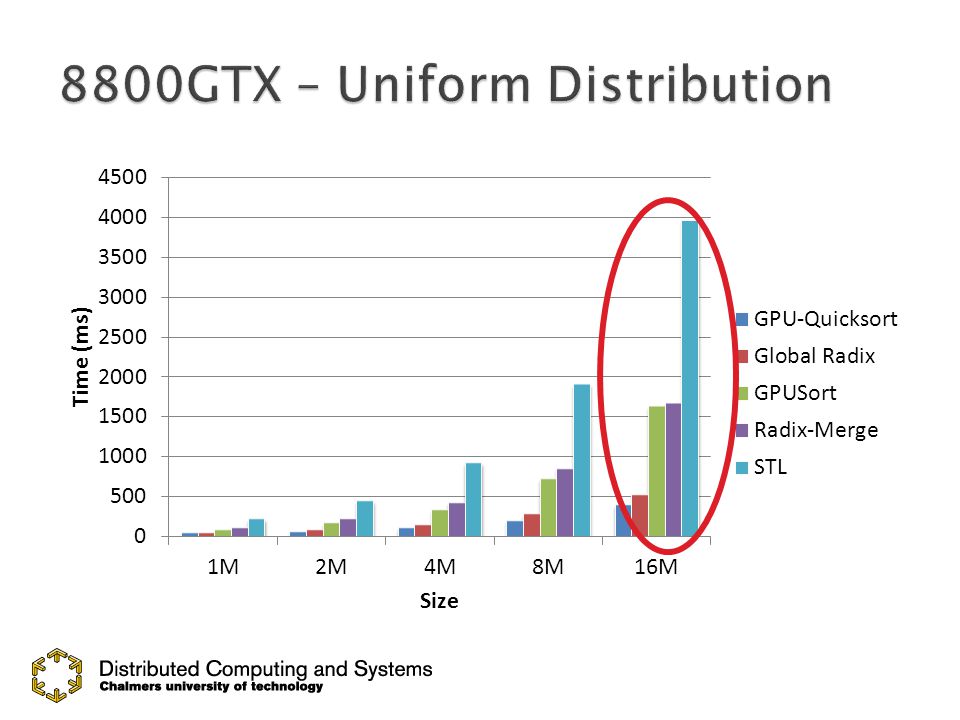
Fetch-And-AddonLeftPointerFetch-And-AddonLeftPointer 2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8 LeftPointer = 2 Thread Block ONE Thread Block TWO 2 3 32

21
Fetch-And-AddonLeftPointerFetch-And-AddonLeftPointer 2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8 LeftPointer = 4 Thread Block ONE Thread Block TWO 5 4 322 3

22
2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8 LeftPointer = 10 322330239778785769802

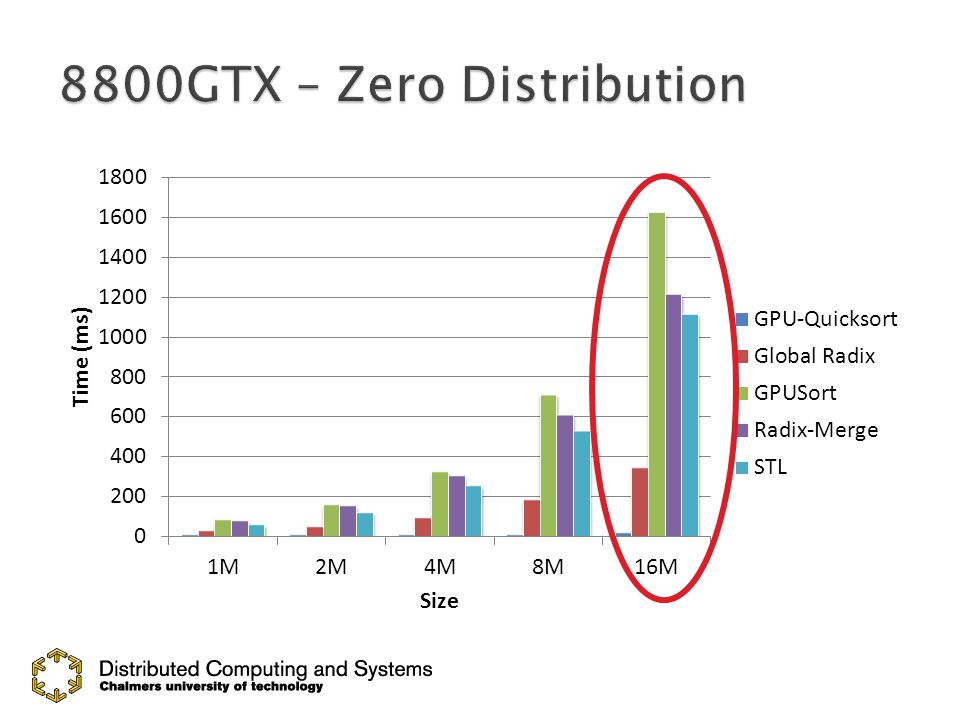
23
2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8 Three way partition 322330239477878576984402

24
2 2 0 7 4 9 3 3 3 7 8 4 8 7 2 5 0 7 6 3 4 2 9 8 < > = > <<< > < > < = < > < >>> < > = < >> ===

25
Recurse on smallest sequence ◦ Max depth log(n) Explicit stack Alternative sorting ◦ Bitonic sort
 Explicit stack Alternative sorting ◦ Bitonic sort")
26
System Model The Algorithm Experiments 5 8 3 23 2235 858

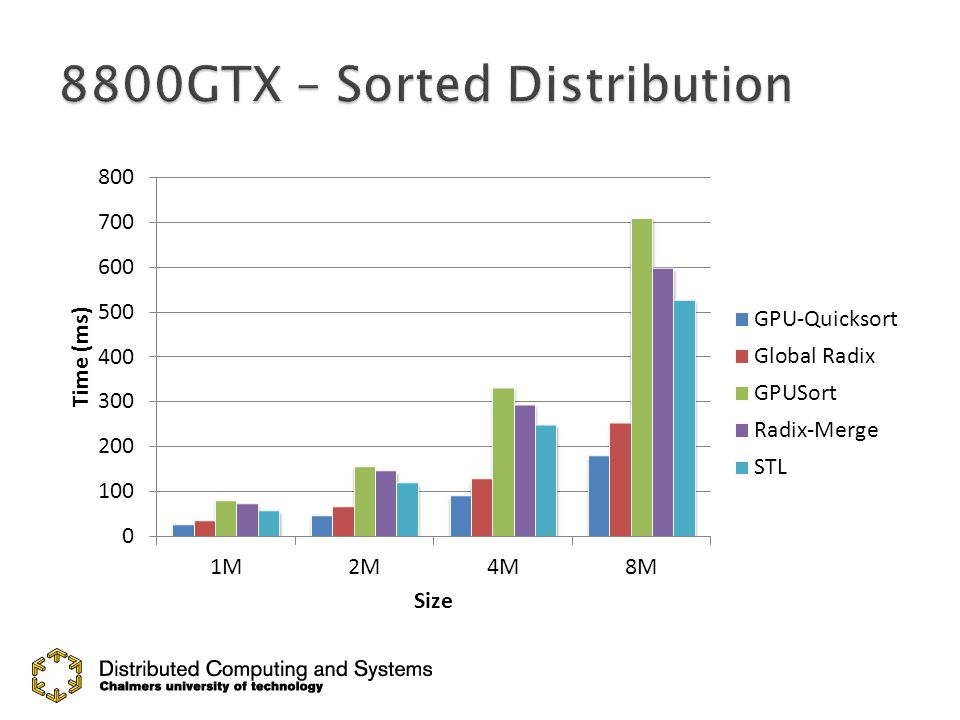
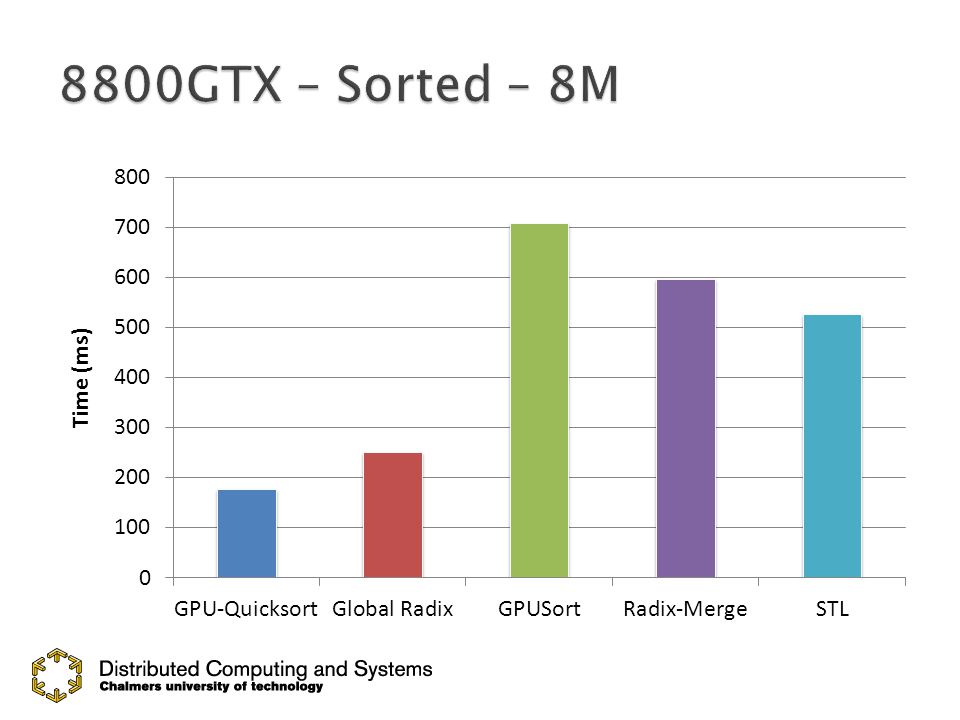
27
GPU-Quicksort GPU-QuicksortCederman and Tsigas, ESA08 GPUSort GPUSortGovindaraju et. al., SIGMOD05 Radix-Merge Radix-MergeHarris et. al., GPU Gems 3 ’07 Global radix Global radixSengupta et. al., GH07 Hybrid HybridSintorn and Assarsson, GPGPU07 Introsort Introsort David Musser, Software: Practice and Experience

28
Uniform Gaussian Bucket Sorted Zero Stanford Models

29
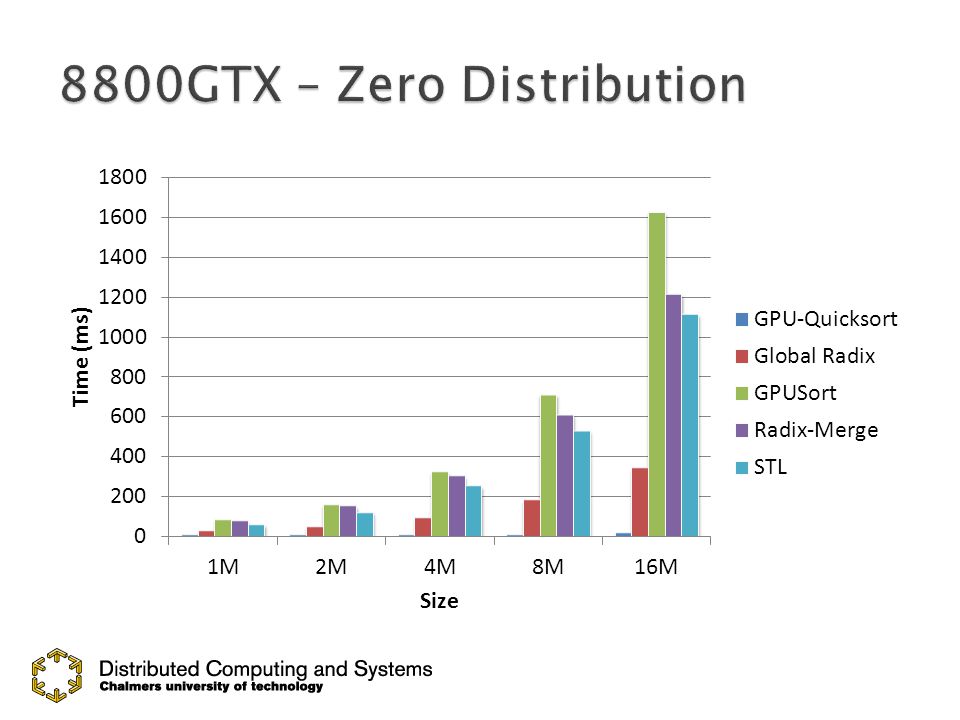
Uniform Gaussian Bucket Sorted Zero Stanford Models

30
Uniform Gaussian Bucket Sorted Zero Stanford Models

31
Uniform Gaussian Bucket Sorted Zero Stanford Models

32
Uniform Gaussian Bucket Sorted Zero Stanford Models

33
Uniform Gaussian Bucket Sorted Zero Stanford Models P x1x1x1x1 x2x2x2x2 x3x3x3x3 x4x4x4x4

34
First Phase ◦ Average of maximum and minimum element Second Phase ◦ Median of first, middle and last element

35
8800GTX ◦ 16 multiprocessors (128 cores) ◦ 86.4 GB/s bandwidth 8600GTS ◦ 4 multiprocessors (32 cores) ◦ 32 GB/s bandwidth CPU-Reference ◦ AMD Dual-Core Opteron 265 / 1.8 GHz
 ◦ 86.4 GB/s bandwidth 8600GTS ◦ 4 multiprocessors (32 cores) ◦ 32 GB/s bandwidth CPU-Reference ◦ AMD Dual-Core Opteron 265 / 1.8 GHz")
39
CPU-Reference ~4s CPU-Reference ~4s

40
GPUSort and Radix-Merge ~1.5s GPUSort and Radix-Merge ~1.5s

41
GPU-Quicksort ~380ms Global Radix ~510ms GPU-Quicksort ~380ms Global Radix ~510ms

45
Reference is faster than GPUSort and Radix-Merge

46
GPU-Quicksort takes less than 200ms GPU-Quicksort takes less than 200ms

50
Bitonic is unaffected by distribution

51
Three-way partition

55
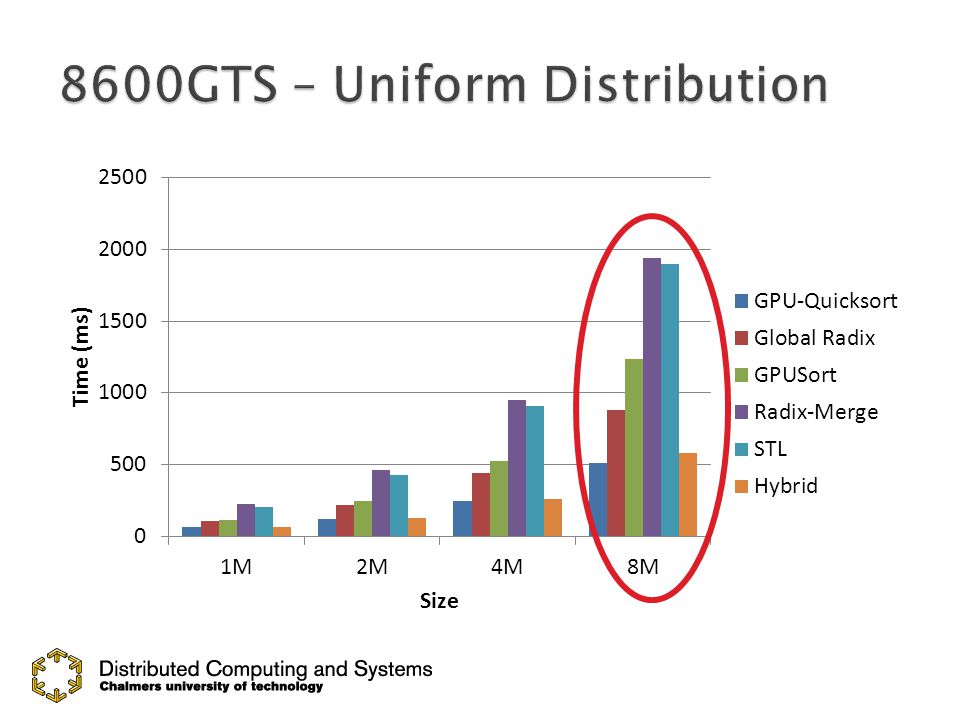
Reference equal to Radix-Merge

56
Quicksort and hybrid ~4 times faster

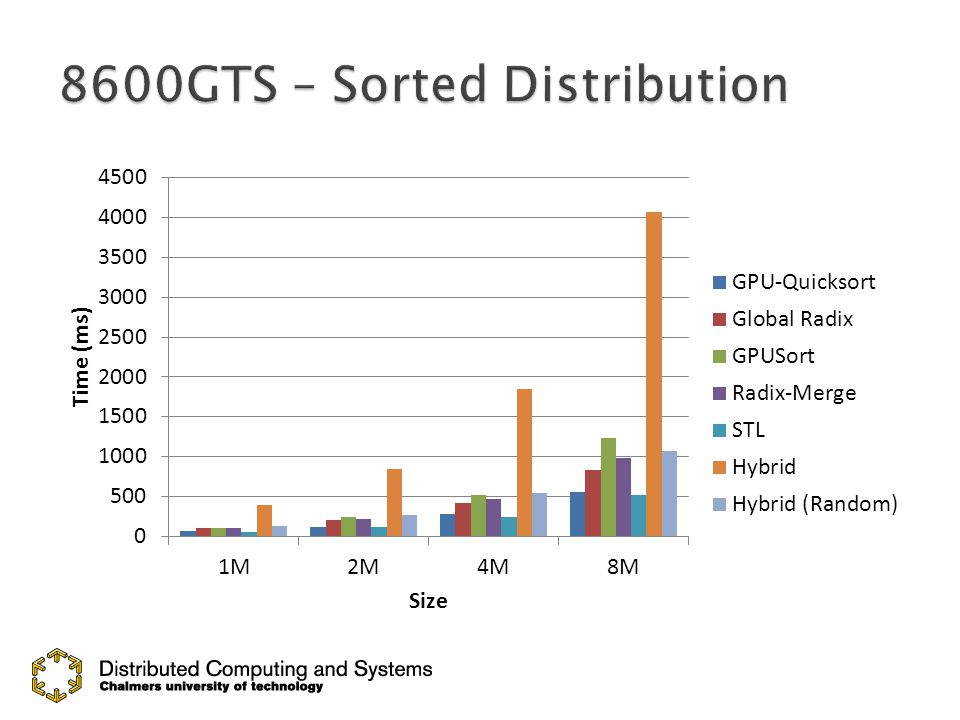
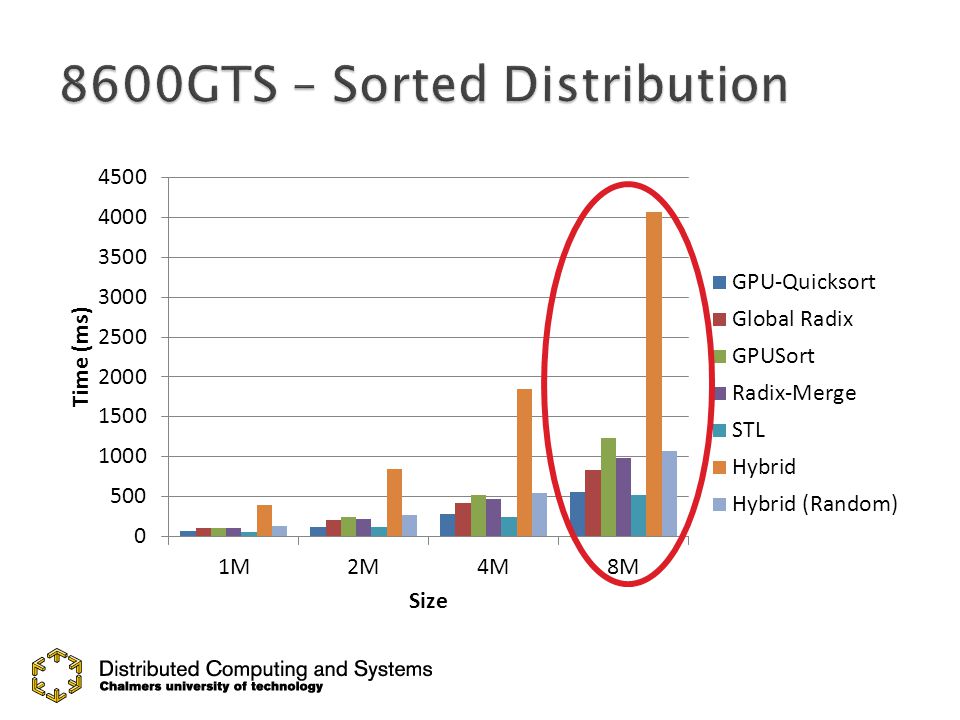
60
Hybrid needs randomization

61
Reference better

63
Similar to uniform distribution

64
Sequence needs to be a power of two in length

65
Minimal, manual cache ◦ Used only for prefix sum and bitonic 32-word SIMD instruction ◦ Main part executes same instructions Coalesced memory access ◦ All reads coalesced No block synchronization ◦ Only required in first phase Expensive synchronization primitives ◦ Two passes amortizes cost

66
Quicksort is a viable sorting method for graphics processors and can be implemented in a data parallel way It is competitive

Similar presentations










 Parallel: perform more than one operation at a time. PRAM model: Parallel Random Access Model. p0p0 p1p1.>")



: 10-12 * Feb 16th.>")






 Ding Yuan ECE Dept., University of Toronto>")




 Selection SortO(n^2)>")
 of elements ≤ x Insert x at output.>")
