Download presentation
Presentation is loading. Please wait.

1
Evaluating Coprocessor Effectiveness for the Data Assimilation Research Testbed Ye Feng IMAGe DAReS SIParCS University of Wyoming

2
Introduction Task: evaluating the feasibility and effectiveness of coprocessor on DART. Target: get_close_obs ( profiling result: computationally intensive & executed multiple times during a typical DART run.) Coprocessor: NVDIA GPUs with CUDA Fortran. Result: Parallel version of exhaustive search on GPU is faster.
 Coprocessor: NVDIA GPUs with CUDA Fortran. Result: Parallel version of exhaustive search on GPU is faster..")
3
Problem Base obs Obs(1)Obs(2)Obs(3)Obs(4)Obs(5)Obs(6)Obs(7)Obs(8)Obs(9)Obs(10)Obs(11)Obs(12)Obs(13)Obs(14)Obs(15)Obs(16) Calculate: the horizontal distances between base location and observation locations.
Obs(2)Obs(3)Obs(4)Obs(5)Obs(6)Obs(7)Obs(8)Obs(9)Obs(10)Obs(11)Obs(12)Obs(13)Obs(14)Obs(15)Obs(16) Calculate: the horizontal distances between base location and observation locations.")
4
Base obs Obs(1)Obs(2)Obs(3)Obs(4)Obs(5)Obs(6)Obs(7)Obs(8)Obs(9)Obs(10)Obs(11)Obs(12)Obs(13)Obs(14)Obs(15)Obs(16) maxdist Find: the close observations.
Obs(2)Obs(3)Obs(4)Obs(5)Obs(6)Obs(7)Obs(8)Obs(9)Obs(10)Obs(11)Obs(12)Obs(13)Obs(14)Obs(15)Obs(16) maxdist Find: the close observations.")
5
1 2 5 8 9 11 12 13 cclose_ind cdist EASY! or is it? d1 d2 d5 d8 d9 d11 d12 d13

6
It is easy on CPU But GPU doesn’t work this way! Problems with data dependency usually don’t scale so well on GPU. cnum_close depends on previous cnum_close value. cclose_ind and cdist both depend on cnum_close. Data Dependency

7
d1 d2 d3 d4 d5 d6 d7 d8 - maxdist = 1 1 0 0 1 0 0 1 1 2 2 2 3 3 3 4 Prefix Sum cnum_close diff psum dist GPU Scan: Take the 1 st bit of Most Significant Bit (1 st bit) 1, dist<maxdist (close) 0, dist>maxdist (not close)
 1, dist<maxdist (close) 0, dist>maxdist (not close)")
8
d1 d2 d3 d4 d5 d6 d7 d8 1 1 0 0 1 0 0 1 1 2 2 2 3 3 3 4 diff psum dist GPU Scan: 1 2 0 0 3 0 0 4 d1 d2 0 0 d5 0 0 d8 Diff_sum cdist 1 1 0 0 1 0 0 1 diff

9
1 2 0 0 3 0 0 4 d1 d2 0 0 d5 0 0 d8 1 2 5 8 d1 d2 d5 d8 What we want What we have cclose_ind Diff_sum cdist How can we independently eliminate the zeros and extract the indices 1 2 3 4 5 6 7 8 Thread ID Extract:

10
1 2 0 0 3 0 0 4 1 2 cclose_ind Diff_sum 1 2 3 4 5 6 7 8 Thread ID If diff.not. 0 Then cclose_ind=Thread ID If diff = 0 Then throw it away 1 1 0 0 1 0 0 1 diff 5 8 Solution?

11
1 2 0 0 3 0 0 4 1 2 cclose_ind Diff_sum 1 2 3 4 5 6 7 8 Thread ID If diff.not. 0 Then cclose_ind=Thread ID If diff = 0 Then throw it away 1 1 0 0 1 0 0 1 diff 5 8 NO Branching!

12
1 2 0 0 3 0 0 4 1 2 05 08 0 0 cclose_ind 1 2 3 4 5 6 7 8 Thread ID d1 d2 0d5 0d8 0 0 cdist d1 d2 0 0 d5 0 0 d8 cnum_close cdistDiff_sum 1 2 3 4 5 6 7 8 Solution!

13
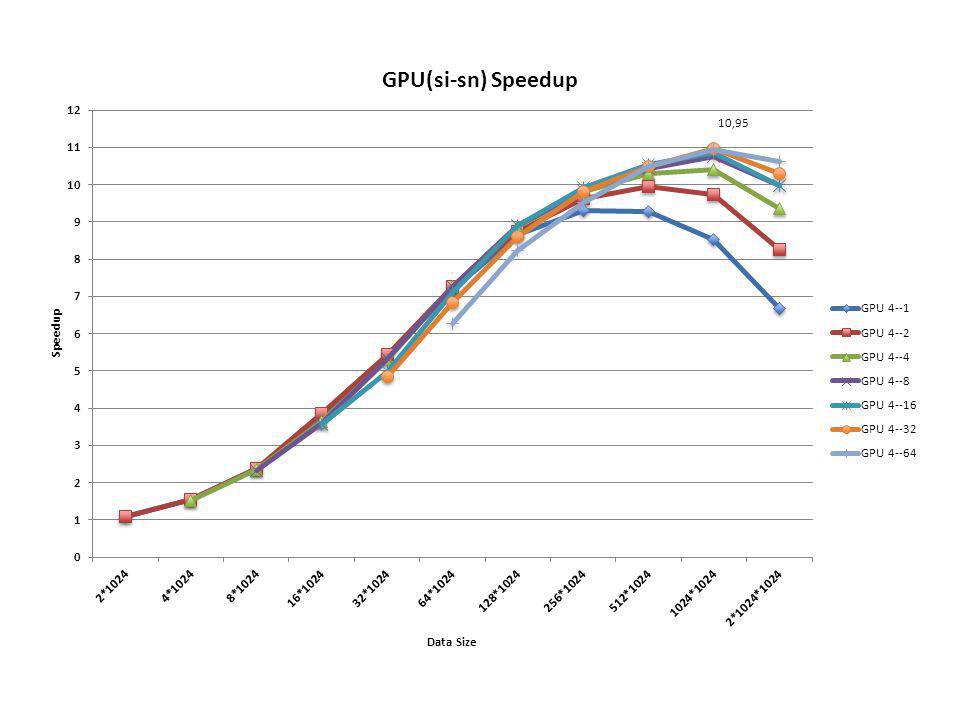
Device Functions: gpu_dist gpu_scan si: number of iterations performed in this kernel. extract sn: number of gpu_scan blocks that each extract block in this kernel handles. Block 1Block 2 si=2 8 threads/block 16 element/block sn=4 dist array: Result from gpu_scan:

19
Conclusion CUDA Fortran on GPU gave significant speedup vs CPU (10x + ). Step outside the box (redesign the algorithm). In order to get good performance, si and sn need to be tuned. Be careful with using device memory. There’s still room to improve the performance of this project.
. In order to get good performance, si and sn need to be tuned. Be careful with using device memory. There’s still room to improve the performance of this project..")
20
Acknowledgements UCARNCARUniversity of Wyoming DAReS/IMAGe Helen Kershaw (Mentor) Nancy Collins (Mentor) Jeff Anderson Tim Hoar Kevin Raeder Kristin Mooney Silvia Gentile Carolyn Mueller Richard Loft Raghu Raj Prasanna Kumar
 Nancy Collins (Mentor) Jeff Anderson Tim Hoar Kevin Raeder Kristin Mooney Silvia Gentile Carolyn Mueller Richard Loft Raghu Raj Prasanna Kumar")
Similar presentations




 Half-adder adds rightmost (least significant) bit Full-adder.>")


















