Download presentation
Presentation is loading. Please wait.

1
Chapter 4 Exploring Numerical Data
Objectives Students will be able to: graph the distribution of a numerical variable 2) calculate summary statistics for a distribution of a numerical variable 3) compare distributions of a numerical variable
 calculate summary statistics for a distribution of a numerical variable. 3) compare distributions of a numerical variable.")
2
NL vs AL In MLB, what is the lineup difference between the NL and the AL? In 1973, the AL enacted the designated hitter (DH). The DH is a player that only bats (does not play defense). In the AL, the DH bats in the place of the pitcher. The DH was designed to increase offense, which would in turn generate more interest in AL games. The assumption was that fans would like to see more offense. Does the DH increase offense in MLB?
. In the AL, the DH bats in the place of the pitcher. The DH was designed to increase offense, which would in turn generate more interest in AL games. The assumption was that fans would like to see more offense. Does the DH increase offense in MLB")
3
Reminder… In Chapters 1-3 we dealt with categorical variables (variables whose outcomes fall into categories). In this chapter we will begin looking at numerical variables. Numerical variables are variables whose possible outcomes take on numerical values that represent different quantities of the variable. Examples: number of runs scored by teams in the AL number of sacks in an NFL season by DeMarcus Ware the amount of time it takes to swim 100 meters

4
Numerical Variables Many of the lessons learned about categorical variables still hold true for numerical variables. As with categorical variables, it is beneficial to begin an analysis of numerical variables with a graph of the data.

5
Here are the run totals for the 30 MLB teams in 2008
Here are the run totals for the 30 MLB teams in Note: the Astros were still in the NL.

6
There are various ways to graph the distribution of numerical variables.
We already know how to make a dotplot. Note: when making dotplots that compare two distributions, it is important to ensure the dotplots are on the same scale. Otherwise, the distributions are difficult to compare.

7
Here are the dotplots comparing the distribution of runs scored for AL and NL teams in 2008 (pg 120). At first glance, the distribution of runs scored seems fairly similar for both leagues. Perhaps AL teams score a little more often than NL teams.

8
Histograms A histogram is a graph that divides the values of a numerical variable into classes and uses bars to represent the number of values in each class. The frequency describes the number of observations in each class. For our histogram, the number of runs will be broken down into classes, and the frequency will be the number of teams in those classes.

9
One easy way to make a histogram is by starting with a dotplot, and building from there.
Let’s make a histogram for the number of runs scored during 2008 for all 30 MLB teams. (pg ) Step 1: Start with a dotplot showing the runs scored for each of the 30 MLB teams.
 Step 1: Start with a dotplot showing the runs scored for each of the 30 MLB teams.")
10
Step 2: Divide the data into 5 to 10 equally wide classes
Step 2: Divide the data into 5 to 10 equally wide classes. For this example, we can use classes that are 50 runs wide. Therefore, our first class will be runs, the next class is runs, etc…

11
Step 3: Count how many observations are in each class
Step 3: Count how many observations are in each class. If an observation falls exactly on a border line, it is considered part of the class above the boundary. For example, the observation on 750 would count as part of the class.

12
Step 4: Draw bars for each class
Step 4: Draw bars for each class. Bars should be equally wide and have no spaces between them. The height for each bar corresponds with the number of observations in that class.

13
It is also possible to make a relative frequency histogram
It is also possible to make a relative frequency histogram. This shows the percentage of observations in each class, rather than the number of observations.

14
When comparing two or more histograms:
Use the same scales! The scales on the horizontal axes should match. The scales on the vertical axes should match. When the number of observations is not the same between distributions, we should make a relative frequency histogram. Let’s look at why….

15
Here are two frequency histograms comparing the number of points scored for players on the LA Lakers and players not on the Lakers in the regular season. Because there are many more players not on the Lakers, it is hard to compare these distributions.

16
Let’s now use a relative frequency histogram:
The comparison is now much easier to make.

17
Describing the Shape of the Distribution
There are several phrases we can use to describe the shape of the distribution of numerical data. Let’s look at this using different data from all 2009 MLB players who had at least 300 plate appearances. A plate appearance occurs each time a player takes their turn at bat.

18
Symmetric A distribution is symmetric if the left side of the graph is roughly a mirror image of the right side.

19
Skewed right A distribution is skewed to the right when the right side of the graph is more spread out than the left side. Think about your right foot. The toes are tall on the left side and get progressively smaller as you move to the right.

20
Skewed left A distribution is skewed to the left when the left side of the graph is more spread out than the right side. Think about your left foot. The toes are tall on the right side and get progressively smaller as you move to the left.

21
Unimodal A distribution is unimodal when it shows one distinct peak
Unimodal A distribution is unimodal when it shows one distinct peak. Note: the previous three graphs can also be considered unimodal.

22
Bimodal A distribution is bimodal if it has two distinct peaks
Bimodal A distribution is bimodal if it has two distinct peaks. This graph has a peak at 0 and a peak at 0.8.

23
Caution: Unimodal vs Bimodal
A common error is calling a distribution bimodal when it is really unimodal. To call a distribution bimodal, the peaks need to be clearly distinct. Sometimes a peak occurs because of our choice in boundaries. A good rule of thumb is that if moving one or two observations would eliminate a peak, then there is a good chance that the peak is only there because of our choice in boundaries.

24
Caution: Unimodal vs Bimodal
Here are two histograms that use the exact same data, but different class widths. The first looks like it has two peaks, but the second seems clearly unimodal.

25
Uniform A distribution is uniform when the heights of the bars are all about the same.

26
Dotplot vs Histogram General rule of thumb:
When the data sets are small, a dotplot is more useful (allows us to see each individual observation). When the data sets are large, a histogram is more useful. Think about trying to make a dotplot of the heights of all Americans. There would be way too many dots.
. When the data sets are large, a histogram is more useful. Think about trying to make a dotplot of the heights of all Americans. There would be way too many dots.")
27
Time for some Magic! Turn to pages

28
Describing Numerical Data with Summary Statistics
To completely describe the distribution of a numerical variable, we need to describe where the distribution is centered and how spread out it is, in addition to the shape. Measuring Center There are two common ways to measure where a distribution of numerical data is centered: the mean and the median

29
Mean To find the mean (also known as the average), simply add up all observations and divide by the total number of observations.
, simply add up all observations and divide by the total number of observations.")
30
Here are the number of runs scored by the 14 AL teams in 2008
Here are the number of runs scored by the 14 AL teams in Let’s find the mean.

31
Here are both means identified on the dotplot with arrows.
The mean is also called the balancing point of a distribution. Think of the dotplot like a see-saw. The mean is the place you would put the fulcrum (place the see-saw pivots).
.")
32
Median The median of a data set is the middle value when the values are in order from smallest to largest (or vice versa). If there are two middle values, then the median is the average of the two middle values. The median of a set of PERFORMANCES is denoted by a capital M.

33
Again, here are the number of runs scored by the 14 AL teams in 2008
Again, here are the number of runs scored by the 14 AL teams in Let’s find the median.

34
To recap, here’s what we know:
Based on this information, it is clear that the center of the AL distribution is higher than the center of the NL distribution, meaning that AL teams typically score more runs than NL teams.

35
There is a connection between the shape of a distribution and the relationship between the mean and median of the distribution. When a distribution is symmetric, the mean and median will be approximately the same. When a distribution is skewed right, the mean will be greater than the median. When a distribution is skewed left (a rarity in sports), the mean will be smaller than the median.
, the mean will be smaller than the median.")
36
This distribution of stolen bases is skewed right, with a median of 5, as noted on the histogram.
It does not seem plausible that the balancing point (mean) is also 5. Because the distribution is stretched out to the right, the mean must be greater than 5. Think of all the extremely values that will pull the mean up.
 is also 5. Because the distribution is stretched out to the right, the mean must be greater than 5. Think of all the extremely values that will pull the mean up.")
37
Being able to identify the shape and center of a distribution is a great start. However, two distributions can have the same shape and center, but look quite different. Here are the dotplots that show 100 PERFORMANCES by two different bowlers. Both distributions are unimodal and symmetric, with centers around However, it is important to compare the spread (variability) of the distributions.
 of the distributions.")
38
Measuring Variability
In sports, it is important to measure variability because it shows the consistency of an athlete or team. For example, if the distribution of an athlete’s PERFORMANCES has little variability, it means that he or she is very consistent. There are several ways to measure the variability of a distribution. For now, we will focus on the range and the interquartile range.

39
Range The range of a distribution is the distance between the minimum value and the maximum value. Examples: The range of AL runs= = 255 runs The range of NL runs= = 218 runs We have some evidence there is less variability in the NL distribution. Range can be a bit deceptive if there is an unusually high or unusually low value in a distribution. For this reason, we often use a second measure of variability called the…

40
Interquartile Range The interquartile range (IQR) is a single number that measures the range of the middle half of the distribution, ignoring the values in the lowest quarter of the distribution and the values in the highest quarter of the distribution
 is a single number that measures the range of the middle half of the distribution, ignoring the values in the lowest quarter of the distribution and the values in the highest quarter of the distribution.")
41
In order to calculate the IQR, we first have to find the quartiles of the distribution, which are the values that divide the distribution into four groups of roughly the same size. Let’s look at the dotplot for the number of runs scored by NL teams in 2008.

42
As you can see, there are 16 teams
As you can see, there are 16 teams. The quartiles would divide the distribution into 4 groups of 4 teams. We have a procedure to help us calculate the quartile values.

43
Steps to calculate quartiles 1) Put the data in numerical order and find the median (this also happens to be the second quartile) 2) Find the median of the values whose position in the ordered list is to the left of the median. This value is the first quartile. 3) Find the median of the values whose position in the ordered list is to the right of the median. This value is the third quartile. Note: When the number of observations is odd, don’t include the median value in the calculations in steps 2 and 3.
 Find the median of the values whose position in the ordered list is to the right of the median. This value is the third quartile. Note: When the number of observations is odd, don’t include the median value in the calculations in steps 2 and 3.")
44
Let’s practice using the 2008 NL runs scored data.

45
The IQR for the NL distribution is smaller than the IQR for the AL distribution. Therefore, we have evidence that there is less variability in the NL distribution. Let’s practice by looking at Tom Brady’s passer ratings.

46
Unusually large or small values can have a big impact on measures like the mean and range.
Think about if we were going to calculate the mean salary and range of salaries for students in this classroom. Let’s say Adam Sandler finds out he is one class short of graduating high school, and that class happens to be Statistics. He moves to Lyndhurst and transfers into this class. What effect would his salary have on the mean? On the range? What type of effect would it have on the median? On IQR?

47
Outliers Outliers are any value that falls out of the pattern of the rest of the data (unusually high or unusually low values in a distribution). Outliers can have a big effect on summary statistics, such as the mean and range.

48
Here are Tennessee Titan’s running back Chris Johnson’s yards for each rush during a game against the Houston Texans on September 20, Do there appear to be any outliers? The mean is brought up greatly by the two outliers. However, the median is relatively unaffected.

49
A measure of center or spread is resistant if it isn’t influenced by outliers.
Median and interquartile range are resistant to outliers Mean and range are not resistant to outliers

50
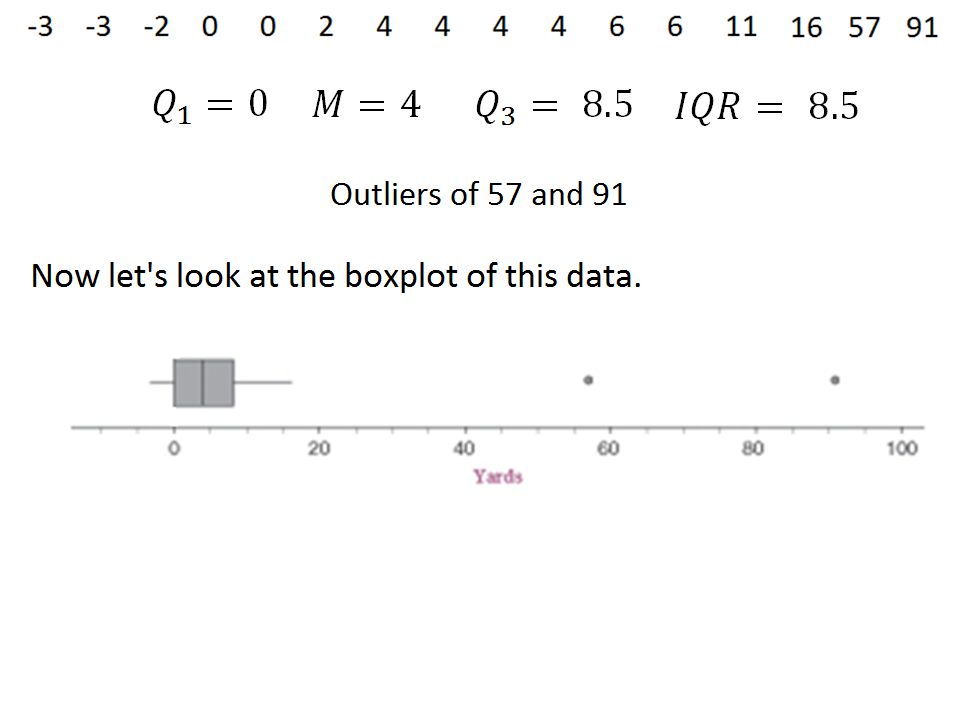
The rule of thumb for an observation being an outlier is if the observation lies more than 1.5 IQR’s below the first quartile or above the third quartile. Let’s practice using Chris Johnson’s 16 rushing attempts from the September 20, 2009 game against the Texans.

54
Boxplots Another way to graph the distribution of a numerical variable is through a boxplot (aka box-and-whisker plot). A boxplot is a visual representation of the five-number summary of the distribution of a numerical variable. This consists of: The minimum value of the distribution The first quartile The median The third quartile The maximum value of the distribution

55
Steps to Make a Boxplot Draw a central box (rectangle) from the first quartile to the third quartile Draw a vertical line to mark the median Draw horizontal lines (called whiskers) that extend from the box out to the smallest and largest observations that are not outliers If there are any outliers, mark them separately
 that extend from the box out to the smallest and largest observations that are not outliers. If there are any outliers, mark them separately.")
56
Let’s go back to our Chris Johnson example.
Let’s reexamine his rushing attempts, along with other key data.

58
Let’s now go back to our Tom Brady example
Let’s now go back to our Tom Brady example. Here were his passer ratings, along with other key data we calculated.

59
…and the boxplot

60
Comparing Distributions
When asked to compare two distributions, you must address four points: The shape The outliers The center The spread Think of the acronym SOCS to help you remember what to address.

61
The shape of a distribution may be difficult to determine from a boxplot.
Try comparing the distance from the median to the minimum and maximum values to determine if a distribution is skewed or roughly symmetric. You will not be able to tell if a distribution is unimodal from looking at a boxplot.

62
Here are boxplots for the number of runs scored in the AL and in the NL during (Note: the plots are on the same scale for comparison purposes.) Let’s compare using our four points.

63
Shape The AL distribution is skewed slightly left (the left half of the distribution appears more spread out). The NL distribution is approximately symmetric.

64
Outliers Neither distribution contains an outlier.

65
Center Typically, teams score more runs in the AL because the median for the AL distributions is higher than the median for the NL distributions.

66
Spread The AL distribution is slightly more spread out because it has both a larger range and larger IQR. This indicates there is more variability among AL teams and more consistency among NL teams.

67
Using the TI-84 to Make Graphs and Calculate Summary Statistics
As fun as it is to calculate everything by hand, the TI-84 calculator can do many of our calculations for us. The calculator can create boxplots, histograms, and calculate summary statistics.

68
Boxplot Let’s use our 2008 run data. Here are the numbers:
AL runs scored: NL runs scored: Write these numbers down or open to pg 120!

69
The first thing we have to do is store this data as a list.
Press STAT and choose the first option EDIT Enter the 14 AL data values in L1 and the 16 NL values in L2

70
Now we are going to set up the boxplot. Exit back into the home screen
Now we are going to set up the boxplot. Exit back into the home screen. Then press STAT PLOT (2nd and y= ). Choose Plot1. Then, turn Plot1 on. Scroll to Type and choose the boxplot icon (with outliers). It is the first option in the second row. Enter L1 for Xlist. Enter 1 for Freq. Choose a mark for outliers.
. Choose Plot1. Then, turn Plot1 on. Scroll to Type and choose the boxplot icon (with outliers). It is the first option in the second row. Enter L1 for Xlist. Enter 1 for Freq. Choose a mark for outliers.")
71
Now we will display the graph. Press ZOOM
Now we will display the graph. Press ZOOM. Then select option 9: ZOOMSTAT. Press enter. Press TRACE and scroll around to see different statistics for the distribution.

72
To see the boxplot for the NL distribution at the same time:
Go back into STAT PLOT and turn on Plot2. Repeat the steps, but enter L2 for Xlist. To do this, scroll down to Xlist. Then press 2nd-2 (you will see the L2 button on top of the number 2).
.")
73
Histogram Note: We can only view one histogram at a time.
Start by pressing STAT PLOT. We want to turn on Plot 1. Make sure no other plots are turned on. Once in Plot1, change Type to Histogram. Enter L1 for Xlist. Keep Freq at 1.

74
To display the graph, press ZOOM and select the 9th option 9: ZOOMSTAT.
Press TRACE to see the class boundaries and frequencies.

75
To change the boundaries, press WINDOW.
Xmin defines where the first class begins and Xscl defines the class width. Xmax, Ymin, and Ymax define how big the window will be. To have classes of size 50 starting at 600, adjust your setting to match the example below.

76
Calculating Summary Statistics
Make sure your run data is still stored in lists. Press STAT, scroll to the CALC menu, and choose the first option 1:1-Var Stats Next, press 2nd-1 to indicate you want the statistics for L1. Then press enter.

77
Here is the information given. Scroll down for additional information.

78
To get the data for the NL distribution, repeat the process using L2.

79
One iPad app that can calculate summary statistics for us is called Bstatistics Lite.
Download it!!! When entering data, observations have to be separated with commas.

Similar presentations