Download presentation
Presentation is loading. Please wait.

1
Dan Jurafsky Lecture 4: Sarcasm, Alzheimers, +Distributional Semantics Computational Extraction of Social and Interactional Meaning SSLST, Summer 2011

3
Why Sarcasm Detection Sarcasm causes problems in sentiment analysis One task: Summarization of Reviews Identify features (size/weight, zoom, battery life, pic quality…) Identify sentiment and polarity of sentiment for each feature (great battery life, insufficient zoom, distortion close to boundaries) Average the sentiment for each feature “Perfect size, fits great in your pocket” + “got to love this pocket size camera, you just need a porter to carry it for you” = ?! slide adapted from Tsur, Davidov, Rappaport 2010

4
What is sarcasm “Sarcasm is verbal irony that expresses negative and critical attitudes toward persons or events” (Kreuz and Glucksberg, 1989) “a form of irony that attacks a person or belief through harsh and bitter remarks that often mean the opposite of what they say” “The activity of saying or writing the opposite of what you mean in a way intended to make someone else feel stupid or show them that you are angr y.”
 a form of irony that attacks a person or belief through harsh and bitter remarks that often mean the opposite of what they say The activity of saying or writing the opposite of what you mean in a way intended to make someone else feel stupid or show them that you are angr y.")
5
Examples from Tsur et al. “Great for insomniacs.” (book) “Just read the book.” (book/movie review) “thank you Janet Jackson for yet another year of Super Bowl classic rock!” “Great idea, now try again with a real product development team.” (e-reader) “make sure to keep the purchase receipt” (smart phone) slide adapted from Tsur, Davidov, Rappaport 2010
 Just read the book. (book/movie review) thank you Janet Jackson for yet another year of Super Bowl classic rock! Great idea, now try again with a real product development team. (e-reader) make sure to keep the purchase receipt (smart phone) slide adapted from Tsur, Davidov, Rappaport")
6
Examples “Wow GPRS data speeds are blazing fast.” @UserName That must suck. I can't express how much I love shopping on black Friday. @UserName that's what I love about Miami. Attention to detail in preserving historic landmarks of the past. “[I] Love The Cover” (book) Negative positive Overexaggeration “don’t judge a book by its cover”
 Negative positive Overexaggeration don’t judge a book by its cover .")
7
Twitter #sarcasm issues Problems: (Davidov et al 2010) Used infrequently Used in non-sarcastic cases, e.g. to clarify a previous tweet (it was #Sarcasm) Used when sarcasm is otherwise ambiguous (prosody surrogate?) – biased towards the most difficult cases GIMW11 argues that the non-sarcastic cases are easily filtered by only using ones with #sarcasm at the end
 Used when sarcasm is otherwise ambiguous (prosody surrogate ) – biased towards the most difficult cases GIMW11 argues that the non-sarcastic cases are easily filtered by only using ones with #sarcasm at the end.")
8
Davidov, Tsur, Rappaport 2010 Data Twitter: 5.9M tweets, unconstrained context Amazon: 66k reviews, known product context Books (fiction, non fiction, children) Electronics (mp3 players, digital cameras, mobiles phones, GPS devices,…) Mechanical Turk annotation K= 0.34 on Amazon, K = 0.41 on Twitter
 Electronics (mp3 players, digital cameras, mobiles phones, GPS devices,…) Mechanical Turk annotation K= 0.34 on Amazon, K = 0.41 on Twitter")
9
Amazon review of Kindle e-reader a slide adapted from Tsur, Davidov, Rappaport 2010

10
Twitter 140 characters Free text Lacking context Hashtags: #hashtag URL addreses References to other users: @user slide adapted from Tsur, Davidov, Rappaport 2010

11
Star Sentiment Baseline (Amazon) “Saying or writing the opposite of what you mean...” Identify unhappy reviewers (1-2 stars) Identify extremely-positive sentiment words (Best, exciting, top, great, …) Classify these sentences as sarcastic slide adapted from Tsur, Davidov, Rappaport 2010
 Saying or writing the opposite of what you mean... Identify unhappy reviewers (1-2 stars) Identify extremely-positive sentiment words (Best, exciting, top, great, …) Classify these sentences as sarcastic slide adapted from Tsur, Davidov, Rappaport 2010")
12
SASI: Semi-supervised Algorithm for Sarcasm Identification Small seed of sarcastic-tagged sentences. Tags 1,...,5: 1: not sarcastic at all 5: clearly sarcastic slide adapted from Tsur, Davidov, Rappaport 2010

13
SASI: Extract features from all training sentences. Represent training sentences in a feature vector space. Features: Pattern based features Punctuation based features Given a new sentence: use weighted-kNN to classify it. Majority vote (over k>0) slide adapted from Tsur, Davidov, Rappaport 2010
 slide adapted from Tsur, Davidov, Rappaport")
14
Hashtag classifier #sarcasm hashtag Not very common Use this tag as a label for supervised learning. slide adapted from Tsur, Davidov, Rappaport 2010

15
Preprocessing [author],[title], [product], [company] [url], [usr], [hashtag] “Silly me, the Kindle and the Sony eBook can’t read these protected formats. Great!” “Silly me, the Kindle and the [company] [product] can’t read these protected formats. Great!” slide adapted from Tsur, Davidov, Rappaport 2010
![Preprocessing [author],[title], [product], [company] [url], [usr], [hashtag] Silly me, the Kindle and the Sony eBook can’t read these protected formats.](http://images.slideplayer.com/8/2325552/slides/slide_15.jpg "Great! Silly me, the Kindle and the [company] [product] can’t read these protected formats. Great! slide adapted from Tsur, Davidov, Rappaport")
16
Pattern based features Davidov & Rappoport 2006, 2008 High Frequency Words (>0.0001) Content Words (<0.001) Pattern: ordered sequence of high frequency words and slots for content words Restrictions: 2-6 HFW 1-5 slots for CW Minimal pattern: [HFW] [CW slot] [HFW] slide adapted from Tsur, Davidov, Rappaport 2010
![Pattern based features Davidov & Rappoport 2006, 2008 High Frequency Words (>0.0001) Content Words (<0.001) Pattern: ordered sequence of high frequency words and slots for content words Restrictions: 2-6 HFW 1-5 slots for CW Minimal pattern: [HFW] [CW slot] [HFW] slide adapted from Tsur, Davidov, Rappaport 2010](http://images.slideplayer.com/8/2325552/slides/slide_16.jpg "Pattern based features Davidov & Rappoport 2006, 2008 High Frequency Words (>0.0001) Content Words (<0.001) Pattern: ordered sequence of high frequency words and slots for content words Restrictions: 2-6 HFW 1-5 slots for CW Minimal pattern: [HFW] [CW slot] [HFW] slide adapted from Tsur, Davidov, Rappaport 2010")
17
Pattern extraction from the training (seed) “Garmin apparently does not care much about product quality or customer support” [company] CW does not CW much does not CW much about CW CW or not CW much about CW CW or CW CW. slide adapted from Tsur, Davidov, Rappaport 2010
![Pattern extraction from the training (seed) Garmin apparently does not care much about product quality or customer support [company] CW does not CW much does not CW much about CW CW or not CW much about CW CW or CW CW.](http://images.slideplayer.com/8/2325552/slides/slide_17.jpg "slide adapted from Tsur, Davidov, Rappaport")
18
Weights of pattern based features 1 : exact match. α : sparse match – extra elements are found between components. γ *n/N: incomplete match – only n of N patterns components are found. 0 : no match. slide adapted from Tsur, Davidov, Rappaport 2010

19
Match example “Garmin apparently does not care much about product quality or customer support” [company] CW does not CW much: exact match: 1 [company] CW not: sparse match: 0.1 Insertion of the word does [company] CW CW does not: incomplete match: 0.08 One of five components (the CW) is missing: 0.1*4/5=0.08 slide adapted from Tsur, Davidov, Rappaport 2010
![Match example Garmin apparently does not care much about product quality or customer support [company] CW does not CW much: exact match: 1 [company] CW not: sparse match: 0.1 Insertion of the word does [company] CW CW does not: incomplete match: 0.08 One of five components (the CW) is missing: 0.1*4/5=0.08 slide adapted from Tsur, Davidov, Rappaport 2010](http://images.slideplayer.com/8/2325552/slides/slide_19.jpg "Match example Garmin apparently does not care much about product quality or customer support [company] CW does not CW much: exact match: 1 [company] CW not: sparse match: 0.1 Insertion of the word does [company] CW CW does not: incomplete match: 0.08 One of five components (the CW) is missing: 0.1*4/5=0.08 slide adapted from Tsur, Davidov, Rappaport 2010")
20
Punctuation based features Number of ! Number of ? Number of quotes Number of CAPITALIZED words/letters slide adapted from Tsur, Davidov, Rappaport 2010

21
Davidov et al (2010) Results F-score Punctuation0.28 Patterns0.77 Patts + punc0.81 Enriched patts0.40 Enriched punct0.77 All (SASI)0.83 Amazon results for different feature sets on gold standard F-score Amazon - Turk0.79 Twitter - Turk0.83 Twitter – #Gold0.55 Amazon/Twitter SASI results for eval paradigms slide from Mari Ostendorf
 Results F-score Punctuation0.28 Patterns0.77 Patts + punc0.81 Enriched patts0.40 Enriched punct0.77 All (SASI)0.83 Amazon results for different feature sets on gold standard F-score Amazon - Turk0.79 Twitter - Turk0.83 Twitter – #Gold0.55 Amazon/Twitter SASI results for eval paradigms slide from Mari Ostendorf")
22
GMW11 Study Data: 2700 tweets, equal amounts of positive, negative and sarcastic (no neutral) Annotation by hashtags: sarcasm/sarcastic, happy/joy/lucky, sadness/angry/frustrated Features: Unigrams, LIWC classes (grouped), WordNet affect Interjections and punctuation, Emoticons & ToUser Classifier: SVM & logistic regression slide from Mari Ostendorf
 Annotation by hashtags: sarcasm/sarcastic, happy/joy/lucky, sadness/angry/frustrated Features: Unigrams, LIWC classes (grouped), WordNet affect Interjections and punctuation, Emoticons & ToUser Classifier: SVM & logistic regression slide from Mari Ostendorf")
23
Results Automatic system accuracy: 3-way S-P-N: 57%, 2-way S-NS: 65% Equal difficulty in separating sarcastic from positive and negative Human S-P-N labeling: 270 tweet subset, K=0.48 Human “accuracy”: 43% unanimous, 63% avg New humans S-NS labeling, K=.59 Human “accuracy”: 59% unanimous, 67% avg Automatic: 68% Accuracies & agreement go up for subset with emoticons Conclusion: Humans are not so good at this task either… slide from Mari Ostendorf

24
Prosody and sarcasm Bryant and Fox Tree 2005 take utterances from talk shows low-pass out the lexical content, leaving only prosody subjects could tell “dripping” sarcastic from non- sarcastic Rockwell (2000) sarcasm in talk shows correlated with lower pitch slower tempo Cheang and Pell acted speech: sarcasm, humour, sincerity, neutrality lower pitch, decreased pitch variation spectral differences: disgust? (facial sneer) or blank face
 or blank face.")
25
Yeah, right. (Tepperman et al., 2006) 131 instances of “yeah right” in Switchboard & Fisher, 23% annotated as sarcastic Annotation: In isolation: very low agreement between human listeners (k=0.16) “Prosody alone is not sufficient to discern whether a speaker is being sarcastic.” In context, still weak agreement (k=.31) Gold standard based on discussion Observation: laughter is much more frequent around sarcastic versions slide from Mari Ostendorf
 131 instances of yeah right in Switchboard & Fisher, 23% annotated as sarcastic Annotation: In isolation: very low agreement between human listeners (k=0.16) Prosody alone is not sufficient to discern whether a speaker is being sarcastic. In context, still weak agreement (k=.31) Gold standard based on discussion Observation: laughter is much more frequent around sarcastic versions slide from Mari Ostendorf.")
26
Sarcasm Detector Features: Prosody: relative pitch, duration & energy for each word Spectral: class-dependent HMM acoustic model score Context: laughter, gender, pause, Q/A DA, location in utterance Classifier: decision tree (WEKA) Implicit feature selection in tree training slide from Mari Ostendorf
 Implicit feature selection in tree training slide from Mari Ostendorf")
27
Results Laughter is most important contextual feature Energy seems a little more important than pitch slide from Mari Ostendorf

28
Whatever! (Benus, Gravano & Hirschberg, 2007) FILLER: I don’t wanna waste my time buying a prom dress or whatever. NEUTRAL: A: Hey Ritchie, you want these over here? B: Yeah, whatever, just put them down. NEGATIVE EVALUATION: So she ordered all this stuff and two days ago she changed her mind. I was like, whatever.
 FILLER: I don’t wanna waste my time buying a prom dress or whatever. NEUTRAL: A: Hey Ritchie, you want these over here. B: Yeah, whatever, just put them down. NEGATIVE EVALUATION: So she ordered all this stuff and two days ago she changed her mind. I was like, whatever..")
29
Whatever! (Benus, Gravano & Hirschberg, 2007) Acted speech: subjects read transcripts of natural conversation
 Acted speech: subjects read transcripts of natural conversation.")
30
Methodology Record 12 subjects reading 5 conversations Transcribe, hand-align, Label syllable boundaries /t/ closure ToBI pitch accents and boundary tones max, min F0, pitch range

31
“Whatever” production results As “whatever” becomes more negative, first syllable is more likely to have pitch accent (sharply rising L+H*) be longer have expanded pitch range Similar results in perception study have pitch accent be longer but have flat pitch (boredom)?
 be longer have expanded pitch range Similar results in perception study have pitch accent be longer but have flat pitch (boredom)")
32
Alzheimers Garrard et al. 2005 Lancashire and Hirst 2009

33
The Nun Study Linguistic Ability in Early Life and the Neuropathology of Alzheimer’s Disease and Cerebrovascular Disease: Findings from the Nun Study D.A. SNOWDON, L.H. GREINER, AND W.R. MARKESBERY The Nun Study: a longitudinal study of aging and Alzheimer’s disease Cognitive and physical function assessed annually All participants agreed to brain donation at death At the first exam given between 1991 and 1993, the 678 participants were 75 to 102 years old. This study: subset of 74 participants for whom we had handwritten autobiographies from early life, all of whom had died.

34
The data In September 1930 leader of the School Sisters of Notre Dame religious congregation requested each sister write “a short sketch of her own life. This account should not contain more than two to three hundred words and should be written on a single sheet of paper... include the place of birth, parentage, interesting and edifying events of one's childhood, schools attended, influences that led to the convent, religious life, and its outstanding events.” Handwritten diaries found in two participating convents, Baltimore and Milwaukee

35
The linguistic analysis Grammatical complexity Developmental Level metric (Cheung/Kemper) sentences classified from 0 (simple one-clause sentences) to 7 (complex sentences with multiple embedding and subordination) Idea density: average number of ideas expressed per 10 words. elementary propositions, typically verb, adjective, adverb, or prepositional phrase. Complex propositions that stated or inferred causal, temporal, or other relationships between ideas also were counted. Prior studies suggest: idea density is associated with educational level, vocabulary, and general knowledge grammatical complexity is associated with working memory, performance on speeded tasks, and writing skill.

36
Idea density “I was born in Eau Claire, Wis., on May 24, 1913 and was baptized in St. James Church.” (1) I was born, (2) born in Eau Claire, Wis., (3) born on May 24, 1913, (4) I was baptized, (5) was baptized in church (6) was baptized in St. James Church, (7) I was born...and was baptized. There are 18 words or utterances in that sentence. The idea density for that sentence was 3.9 (7/18 * 10 = 3.9 ideas per 10 words).
 I was born, (2) born in Eau Claire, Wis., (3) born on May 24, 1913, (4) I was baptized, (5) was baptized in church (6) was baptized in St. James Church, (7) I was born...and was baptized. There are 18 words or utterances in that sentence. The idea density for that sentence was 3.9 (7/18 * 10 = 3.9 ideas per 10 words)..")
37
Results correlation between neuropathologically defined Alzheimers desiease had lower idea density scores than non-Alzheimers Correlations between idea density scores and mean neurofibrillary tangle counts −0.59 for the frontal lobe, −0.48 for the temporal lobe, −0.49 for the parietal lobe

38
Explanations? Early studies found same results with a college- education subset of the population who were teachers, suggesting education was not the key factor They suggest: Low linguistic ability in early life may reflect suboptimal neurological and cognitive development which might increase susceptibility to the development of Alzheimer’s disease pathology in late life

39
Garrard et al. 2005 British writer Iris Murdoch last novel published 1995, Diagnosed with Alzheimers 1997 Compared three novels Under the Net (first) The Sea (in her prime) Jackson's Dilemma (final novel) All her books written in longhand with little editing
 The Sea (in her prime) Jackson s Dilemma (final novel) All her books written in longhand with little editing.")
40
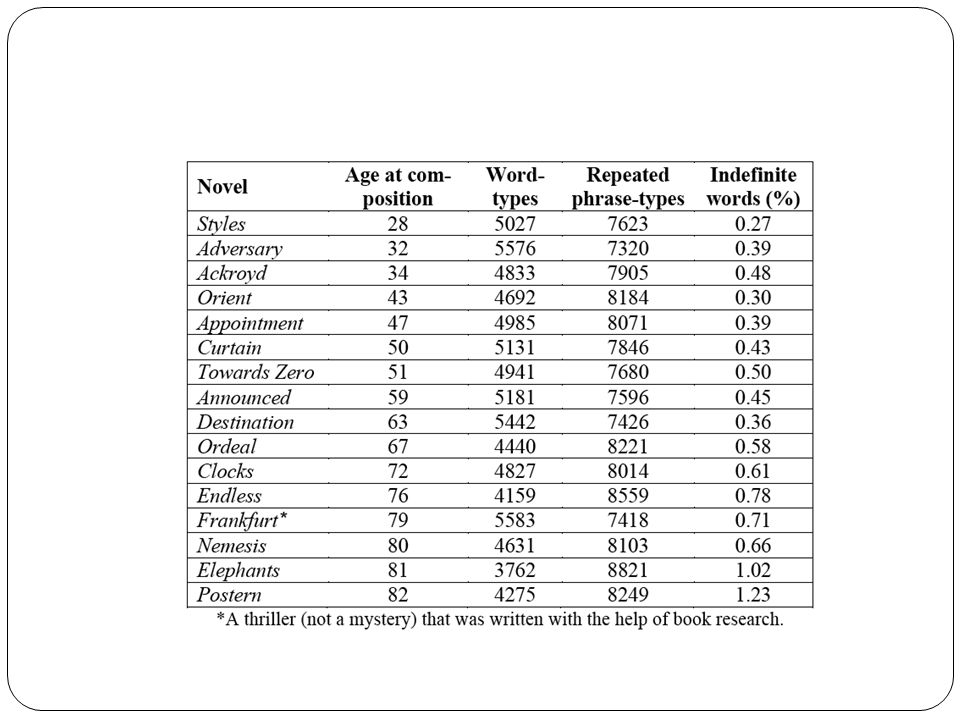
Type to token ratio in the 3 novels

41
Syntactic Complexity

42
Mean proportions of usages of the 10 most frequently occurring words in each book that appear twice within a series of short intervals, ranging from consecutive positions in the text to a separation of three intervening words. Garrard P et al. Brain 2005;128:250-260 Brain Vol. 128 No. 2 © Guarantors of Brain 2004; all rights reserved

43
Parts of speech

44
Comparative distributions of values of: (A) frequency and (B) word length in the three books. Garrard P et al. Brain 2005;128:250-260 Brain Vol. 128 No. 2 © Guarantors of Brain 2004; all rights reserved

45
From Under the Net, 1954 "So you may imagine how unhappy it makes me to have to cool my heels at Newhaven, waiting for the trains to run again, and with the smell of France still fresh in my nostrils. On this occasion, too, the bottles of cognac, which I always smuggle, had been taken from me by the Customs, so that when closing time came I was utterly abandoned to the torments of a morbid self-scrutiny.” From Jackson's Dilemma, 1995 "His beautiful mother had died of cancer when he was 10. He had seen her die. When he heard his father's sobs he knew. When he was 18, his younger brother was drowned. He had no other siblings. He loved his mother and his brother passionately. He had not got on with his father. His father, who was rich and played at being an architect, wanted Edward to be an architect too. Edward did not want to be an architect."

46
Lancashire and Hirst Vocabulary Changes in Agatha Christie’s Mysteries as an Indication of Dementia: A Case Study Ian Lancashire and Graeme Hirst 2009

48
Vocabulary Changes in Agatha Christie’s Mysteries as an Indication of Dementia: A Case Study Ian Lancashire and Graeme Hirst 2009 Examined all of Agatha Christie’s novels Features: Nicholas, M., Obler, L. K., Albert, M. L., Helm-Estabrooks, N. (1985). Empty speech in Alzheimer’s disease and fluent aphasia. Journal of Speech and Hearing Research, 28: 405–10. Number of unique word types Number of different repeated n-grams up to 5 Number of occurences of “thing”, “anything”, and “something”
. Empty speech in Alzheimer’s disease and fluent aphasia. Journal of Speech and Hearing Research, 28: 405–10. Number of unique word types Number of different repeated n-grams up to 5 Number of occurences of thing , anything , and something .")
50
Results

51
Distributional Semantics

52
Distributional methods for word similarity Firth (1957): “You shall know a word by the company it keeps!” Zellig Harris (1954): “If we consider oculist and eye-doctor we find that, as our corpus of utterances grows, these two occur in almost the same environments. In contrast, there are many sentence environments in which oculist occurs but lawyer does not... It is a question of the relative frequency of such environments, and of what we will obtain if we ask an informant to substitute any word he wishes for oculist (not asking what words have the same meaning). These and similar tests all measure the probability of particular environments occurring with particular elements... If A and B have almost identical environments we say that they are synonyms.
. These and similar tests all measure the probability of particular environments occurring with particular elements... If A and B have almost identical environments we say that they are synonyms..")
53
Distributional methods for word similarity Nida example: A bottle of tezgüino is on the table Everybody likes tezgüino Tezgüino makes you drunk We make tezgüino out of corn. Intuition: just from these contexts a human could guess meaning of tezguino So we should look at the surrounding contexts, see what other words have similar context.

54
Context vector Consider a target word w Suppose we had one binary feature f i for each of the N words in the lexicon v i Which means “word v i occurs in the neighborhood of w” w=(f1,f2,f3,…,fN) If w=tezguino, v1 = bottle, v2 = drunk, v3 = matrix: w = (1,1,0,…)
 If w=tezguino, v1 = bottle, v2 = drunk, v3 = matrix: w = (1,1,0,…)")
55
Intuition Define two words by these sparse features vectors Apply a vector distance metric Say that two words are similar if two vectors are similar

56
Distributional similarity So we just need to specify 3 things 1. How the co-occurrence terms are defined 2. How terms are weighted (frequency? Logs? Mutual information?) 3. What vector distance metric should we use? Cosine? Euclidean distance?
 3. What vector distance metric should we use. Cosine. Euclidean distance .")
57
Defining co-occurrence vectors We could have windows Bag-of-words We generally remove stopwords But the vectors are still very sparse So instead of using ALL the words in the neighborhood How about just the words occurring in particular relations

58
Defining co-occurrence vectors Zellig Harris (1968) The meaning of entities, and the meaning of grammatical relations among them, is related to the restriction of combinations of these entities relative to other entities Idea: two words are similar if they have similar parse contexts. Consider duty and responsibility: They share a similar set of parse contexts: Slide adapted from Chris Calllison-Burch

59
Co-occurrence vectors based on dependencies For the word “cell”: vector of NxR features R is the number of dependency relations

60
2. Weighting the counts (“Measures of association with context”) We have been using the frequency of some feature as its weight or value. But we could use any function of this frequency One possibility: tf-idf Another one: conditional probability f=(r,w’) = (obj-of,attack) P(f|w)=count(f,w)/count(w); Assoc prob (w,f)=p(f|w)
 We have been using the frequency of some feature as its weight or value. But we could use any function of this frequency One possibility: tf-idf Another one: conditional probability f=(r,w’) = (obj-of,attack) P(f|w)=count(f,w)/count(w); Assoc prob (w,f)=p(f|w).")
61
Intuition: why not frequency “drink it” is more common than “drink wine” But “wine” is a better “drinkable” thing than “it” Idea: We need to control for change (expected frequency) We do this by normalizing by the expected frequency we would get assuming independence
 We do this by normalizing by the expected frequency we would get assuming independence")
62
Weighting: Mutual Information Mutual information: between 2 random variables X and Y Pointwise mutual information: measure of how often two events x and y occur, compared with what we would expect if they were independent:

63
Weighting: Mutual Information Pointwise mutual information: measure of how often two events x and y occur, compared with what we would expect if they were independent: PMI between a target word w and a feature f :

64
Mutual information intuition Objects of the verb drink

65
3. Defining similarity between vectors

66
Summary of similarity measures

67
Evaluating similarity Intrinsic Evaluation: Correlation coefficient Between algorithm scores And word similarity ratings from humans Extrinsic (task-based, end-to-end) Evaluation: Malapropism (spelling error) detection WSD Essay grading Taking TOEFL multiple-choice vocabulary tests
 Evaluation: Malapropism (spelling error) detection WSD Essay grading Taking TOEFL multiple-choice vocabulary tests")
68
An example of detected plagiarism

69
Resources Peter Turney and Patrick Pantel. 2010. From Frequency to Meaning: Vector Space Models of Semantics. Journal of Artificial Intelligence Research 37: 141-188. Distributional Semantics and Compositionality (DiSCo’2011) Workshop at ACL HLT 2011
 Workshop at ACL HLT")
Similar presentations



 Ari Rappoport The Hebrew University.>")

 CIS, LMU München Winter Semester 2014-2015 Dr. Alexander Fraser, CIS.>")










 Matheus Araújo (UFMG, Brazil) Fabrício Benevenuto (UFMG, Brazil) Meeyoung Cha (KAIST, Korea) Comparing and Combining.>")




