Download presentation
Presentation is loading. Please wait.

3
Web Search Engines –

6
Browsing Services Search Engine Services Web Pages Bag of Words Two semantics extremes Two service extremes ???

7
–

10
Web ……

11
version: 1.0// version number url: http://www.pku.edu.cn/// URL origin: http://www.somewhere.cn/// original URL date: Tue, 15 Apr 2003 08:13:06 GMT // time of harvest ip: 162.105.129.12 // IP address unzip-length: 30233 // If included, the data must be compressed length: 18133// data length // a blank line XXXXXXXX// the followings are data part XXXXXXXX …. XXXXXXXX// data end // insert a new line

12
File Organizations (Indexes) Choices for accessing data during query evaluation Scan the entire collection –Typical in early (batch) retrieval systems –Computational and I/O costs are O(characters in collection) –Practical for only small text collections –Large memory systems make scanning feasible Use indexes for direct access –Evaluation time O(query term occurrences in collection) –Practical for large collections –Many opportunities for optimization Hybrids: Use small index, then scan a subset of the collection
 Choices for accessing data during query evaluation Scan the entire collection –Typical in early (batch) retrieval systems –Computational and I/O costs are O(characters in collection) –Practical for only small text collections –Large memory systems make scanning feasible Use indexes for direct access –Evaluation time O(query term occurrences in collection) –Practical for large collections –Many opportunities for optimization Hybrids: Use small index, then scan a subset of the collection")
13
Indexes What should the index contain? Database systems index primary and secondarykeys –This is the hybrid approach –Index provides fast access to a subset of database records –Scan subset to find solution set IR Problem: Cannot predict keys that people will use in queries –Every word in a document is a potential search term IR Solution: Index by all keys (words) full text indexes
 full text indexes.")
14
Index Contents The contents depend upon the retrieval model Feature presence/absence –Boolean –Statistical (tf, df, ctf, doclen, maxtf) –Often about 10% the size of the raw data, compressed Positional –Feature location within document –Granularities include word, sentence, paragraph, etc –Coarse granularities are less precise, but take less space –Word-level granularity about 20-30% the size of the raw data,compressed
 –Often about 10% the size of the raw data, compressed Positional –Feature location within document –Granularities include word, sentence, paragraph, etc –Coarse granularities are less precise, but take less space –Word-level granularity about 20-30% the size of the raw data,compressed")
15
Indexes: Implementation Common implementations of indexes –Bitmaps –Signature files –Inverted files Common index components –Dictionary (lexicon) –Postings document ids word positions No positional data indexed
 –Postings document ids word positions No positional data indexed")
16
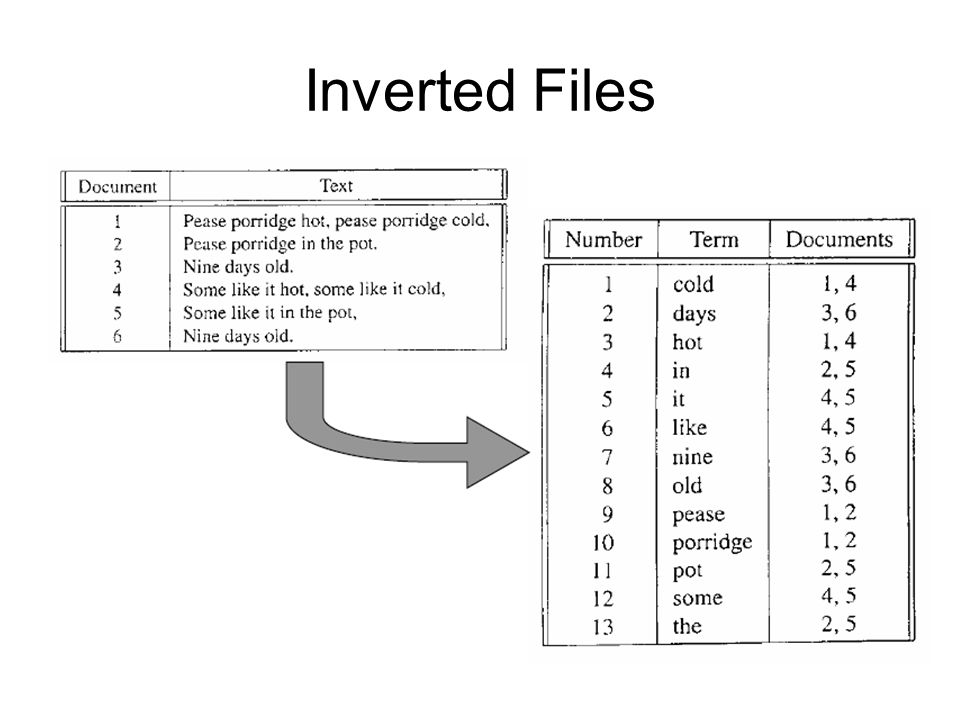
Inverted Files

18
Word-Level Inverted File

19
Inverted Search Algorithm 1.Find query elements (terms) in the lexicon 2.Retrieve postings for each lexicon entry 3.Manipulate postings according to the retrieval model
 in the lexicon 2.Retrieve postings for each lexicon entry 3.Manipulate postings according to the retrieval model")
20
Word-Level Inverted File Query: 1.porridge & pot (BOOL) 2.porridge pot (BOOL) 3. porridge pot (VSM)VSM lexicon posting Answer
VSM lexicon posting Answer.")
22
A Brief history of Modern Information Retrieval In 1945, Vannevar Bush published "As We May Think" in the Atlantic monthly. In the 1960s, the SMART system by Gerard Salton and his students Cranfield evaluations done by Cyril Cleverdon The 1970s and 1980s saw many developments built on the advances of the 1960s. In 1992 with the inception of Text Retrieval Conference. The algorithms developed The algorithms developed in IR were employed for searching the Web from 1996.

23
Clustering of SIGIR papers by topic vs. year

24
Question answering

25
Clustering

26
Inverted files & Implementations

27
Message understanding & TDT

28
Filtering

29
Hypertext IR, Multiple evidence

30
Probabilistic & Language models

31
Distributed IR

32
Evaluation

33
Topic distillation & Linkage retrieval

34
Text categorisation

35
Document summarisation

36
Cross lingual

37
CIIR, University of Massachusetts LTI, Carnegie Mellon University The Stanford University DB Group Microsoft Research Asia TREC,,

38
Lemur http://www-2.cs.cmu.edu/~lemur/

39
Lemur Toolkit LM IR research system –ad hoc, distributed retrieval, cross-language IR, summarization, filtering, and classification : – – Simple Language Model – Language Model : –C and C++ –Unix / Windows –Current Version 3.1

40
MRA: Towards Next Generation Web Search From Pages to Blocks –Analyze the Web at finer granularity From Surface Web to Deep Web –Unleash the huge assets of high-value information From Unstructure to Structure –Provide well organized results From relevance to intelligence –Contribute knowledge discovery with search From Desktop Search to Mobile Search –Bridge physical world search to digital world search

41
The Stanford Univ. DB Group WebBase –Crawling, storage, indexing, and querying of large collections of Web pages. Digital Libraries –Infrastructure and services for creating, disseminating, sharing and managing information

42
TREC Conference Established in 1992 to evaluate large-scale IR –Retrieving documents from a gigabyte collection Has run continuously since then –TREC 2004(13 th ) meeting is in November Run by NISTs Information Access Division Probably most well known IR evaluation setting –Started with 25 participating organizations in 1992 evaluation –In 2003, there were 93 groups from 22 different countries Proceedings available on-line (http://trec.nist.gov ) –Overview of TREC 2003 at http://trec.nist.gov/pubs/trec12/papers/OVERVIEW.12.pd f
 meeting is in November Run by NISTs Information Access Division Probably most well known IR evaluation setting –Started with 25 participating organizations in 1992 evaluation –In 2003, there were 93 groups from 22 different countries Proceedings available on-line ( ) –Overview of TREC 2003 at f")
43
TREC consists of IR research tracks –Ad hoc, routing, confusion ( scanned documents, speech recognition ), video, filtering, multilingual ( cross-language, Spanish, Chinese ), question answering, novelty, high precision, interactive, Web, database merging, NLP, … Each track works on roughly the same model –November: track approved by TREC community –Winter: tracks members finalize format for track –Spring: researchers train system based on specification –Summer: researchers carry out format evaluation Usually a blind evaluation: research do not know answer –Fall: NIST carries out evaluation –November: Group meeting (TREC) to find out: How well your site did How others tackled the program –Many tracks are run by volunteers outside of NIST (e.g. Web) Coopetition model of evaluation –Successful approaches generally adopted in next cycle TREC General Format
 Coopetition model of evaluation –Successful approaches generally adopted in next cycle TREC General Format.")
44
TREC Tracks

45
Summary of VLC/Web Track evaluation 1996 - 2003

46
Tianwang Group @PKU

47
http://www.infomall.cn/

50
CWT100g !

52
2004-12-20 2.5/8.8 = 28.4%

53
TEAMNAME TD- RUNS NPHP- RUNS APEX 55 ANS32 TRS 52 MUMIAN131 MUMIAN221 SCUTDB55 WLL 1 pooling google,yisou,baidu,sogou,zhongsou SE

54
TIANWANG_RUN

55
( :www.codepub.com www.codepub.com

57
Vector Space Model d q m TFIDF : ( tf,idf ) BACK
 BACK")
58
Query Answer 1.porridge & pot (BOOL) –d2 2.porridge pot (BOOL) –null 3. porridge pot (VSM) –d2 > d1>d5 –Next page BACK
 –d2 > d1>d5 –Next page BACK.")
59
CIIR- Center for Intelligent Information Retrieval @UMASS One of the leading research groups in IR –improving the probabilistic models, –first description of a retrieval system based on statistical language models. –introduced and improved a number of techniques for text and query representation –automatically representing databases and combining local searches for DIR –first high capacity probabilistic filtering architecture –define and evaluate the first versions of event detection and tracking software –earliest research on ranking and representation techniques for Asian languages –first approaches to information extraction that emphasized learning –novel techniques for indexing images and video

60
CIIR cont. Research –more than 500 journal and refereed conference papers over the past 12 years (52 submissions in 2003). industrial and government collaboration –INQUERY –licensed our software to nearly 300 sites Education –20 Ph.D.s, 29 M.S. –123/145, 34/4 graduate/undergraduate
. industrial and government collaboration –INQUERY –licensed our software to nearly 300 sites Education –20 Ph.D.s, 29 M.S. –123/145, 34/4 graduate/undergraduate.")
61
CIIR cont. Personnel –Faculty4(W. BRUCE CROFT) –Technical personel10 –Graduate student34/10 Groups –IESL:Information Extraction and Synthesis Laboratory –IR :Information Retrieval Laboratory –MIR :Multimedia Indexing and Retrieval Laboratory The CIIR is currently concentrating on the unsolved long- term research problems that underlie effective information retrieval –text representation, –query acquisition, –retrieval models
 –Technical personel10 –Graduate student34/10 Groups –IESL:Information Extraction and Synthesis Laboratory –IR :Information Retrieval Laboratory –MIR :Multimedia Indexing and Retrieval Laboratory The CIIR is currently concentrating on the unsolved long- term research problems that underlie effective information retrieval –text representation, –query acquisition, –retrieval models.")
62
LTI : Language Technologies Institue @CMU Machine Translation, Natural Language Processing, Speech, and Information Retrieval IR Projects (Jamie Callan and Yiming Yang ) –Adaptive Information Filtering –Distributed Information Retrieval / Federated Search –Email Classification and Prioritization –Minerva: Web Mining for Question Answering –MuchMore: Translingual Information Retrieval –JAVELIN: Open-Domain Question Answering BACK
 –Adaptive Information Filtering –Distributed Information Retrieval / Federated Search – Classification and Prioritization –Minerva: Web Mining for Question Answering –MuchMore: Translingual Information Retrieval –JAVELIN: Open-Domain Question Answering BACK")
Similar presentations













 Association of Information and Dissemination Centers.>")
















