Download presentation
Presentation is loading. Please wait.

1
How to do Bayes-Optimal Classification with Massive Datasets: Large-scale Quasar Discovery Alexander Gray Georgia Institute of Technology College of Computing Joint work with Gordon Richards (Princeton), Robert Nichol (Portsmouth ICG), Robert Brunner (UIUC/NCSA), Andrew Moore (CMU)
, Robert Nichol (Portsmouth ICG), Robert Brunner (UIUC/NCSA), Andrew Moore (CMU)")
2
What I do Often the most general and powerful statistical (or “machine learning”) methods are computationally infeasible. I design machine learning methods and fast algorithms to make such statistical methods possible on massive datasets (without sacrificing accuracy).
..")
3
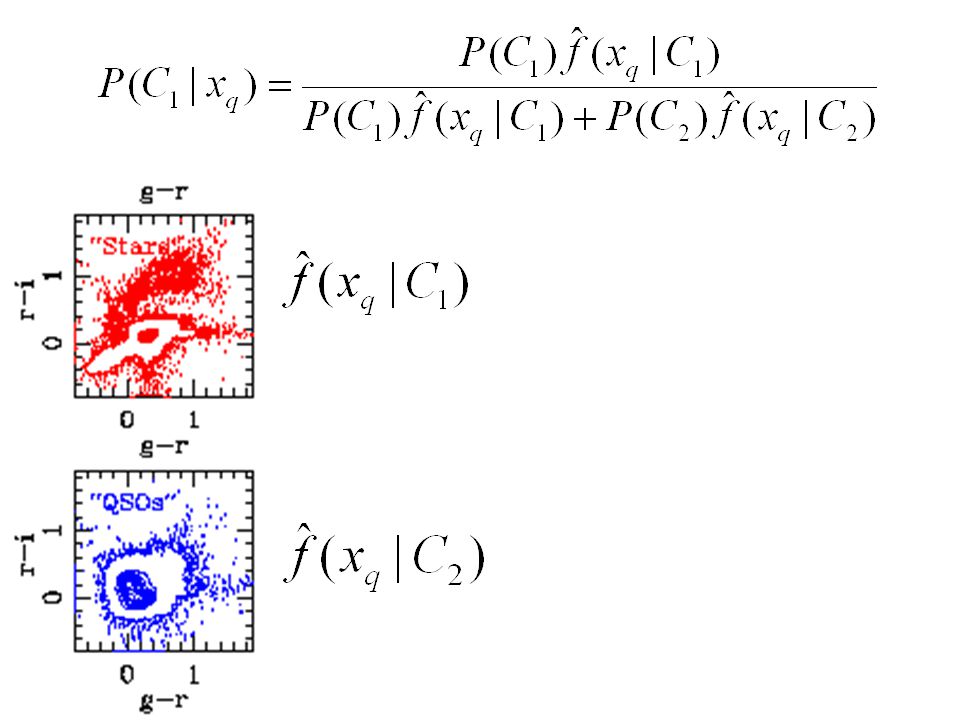
Quasar detection •Science motivation: use quasars to trace the distant/old mass in the universe •Thus we want lots of sky SDSS DR1, 2099 square degrees, to g = 21 •Biggest quasar catalog to date: tens of thousands •Should be ~1.6M z<3 quasars to g=21

4
Classification •Traditional approach: look at 2-d color-color plot (UVX method) –doesn’t use all available information –not particularly accurate (~60% for relatively bright magnitudes) •Statistical approach: Pose as classification. 1.Training: Train a classifier on large set of known stars and quasars (‘training set’) 2.Prediction: The classifier will label an unknown set of objects (‘test set’)
 2.Prediction: The classifier will label an unknown set of objects (‘test set’).")
5
Which classifier? 1.Statistical question: Must handle arbitrary nonlinear decision boundaries, noise/overlap 2.Computational question: We have 16,713 quasars from [Schneider et al. 2003] (.08<z<5.4), 478,144 stars (semi-cleaned sky sample) – way too big for many classifiers 3.Scientific question: We must be able to understand what it’s doing and why, and inject scientific knowledge
, 478,144 stars (semi-cleaned sky sample) – way too big for many classifiers 3.Scientific question: We must be able to understand what it’s doing and why, and inject scientific knowledge.")
6
Which classifier? •Popular answers: –logistic regression: fast but linear only –naïve Bayes classifier: fast but quadratic only –decision tree: fast but not the most accurate –support vector machine: accurate but O(N 3 ) –boosting: accurate but requires thousands of classifiers –neural net: reasonable compromise but awkward/human-intensive to train •The good nonparametric methods are also black boxes – hard/impossible to interpret
 –boosting: accurate but requires thousands of classifiers –neural net: reasonable compromise but awkward/human-intensive to train •The good nonparametric methods are also black boxes – hard/impossible to interpret.")
7
Main points of this talk 1.nonparametric Bayes classifier 2.can be made fast (algorithm design) 3.accurate and tractable science
 3.accurate and tractable science")
8
Main points of this talk 1.nonparametric Bayes classifier 2.can be made fast (algorithm design) 3.accurate and tractable science
 3.accurate and tractable science")
9
Optimal decision theory Optimal decision boundary Star density Quasar density x density f(x)
")
10
Bayes’ rule, for Classification

12
So how do you estimate an arbitrary density?

13
Kernel Density Estimation (KDE) for example (Gaussian kernel):
 for example (Gaussian kernel):")
14
Kernel Density Estimation (KDE) • There is a principled way to choose the optimal smoothing parameter h • Guaranteed to converge to the true underlying density (consistency) • Nonparametric – distribution need not be known
 • There is a principled way to choose the optimal smoothing parameter h • Guaranteed to converge to the true underlying density (consistency) • Nonparametric – distribution need not be known")
15
Nonparametric Bayes Classifier (NBC) [1951] • Nonparametric – distribution can be arbitrary • This is Bayes-optimal, given the right densities • Very clear interpretation • Parameter choices are easy to understand, automatable • There’s a way to enter prior information Main obstacle:
![Nonparametric Bayes Classifier (NBC) [1951] • Nonparametric – distribution can be arbitrary • This is Bayes-optimal, given the right densities • Very clear interpretation • Parameter choices are easy to understand, automatable • There’s a way to enter prior information Main obstacle:](http://images.slideplayer.com/7/1878706/slides/slide_15.jpg "Nonparametric Bayes Classifier (NBC) [1951] • Nonparametric – distribution can be arbitrary • This is Bayes-optimal, given the right densities • Very clear interpretation • Parameter choices are easy to understand, automatable • There’s a way to enter prior information Main obstacle:")
16
Main points of this talk 1.nonparametric Bayes classifier 2.can be made fast (algorithm design) 3.accurate and tractable science
 3.accurate and tractable science")
17
kd-trees: most widely-used space- partitioning tree [Bentley 1975], [Friedman, Bentley & Finkel 1977] • Univariate axis-aligned splits • Split on widest dimension • O(N log N) to build, O(N) space
![kd-trees: most widely-used space- partitioning tree [Bentley 1975], [Friedman, Bentley & Finkel 1977] • Univariate axis-aligned splits • Split on widest dimension • O(N log N) to build, O(N) space](http://images.slideplayer.com/7/1878706/slides/slide_17.jpg "kd-trees: most widely-used space- partitioning tree [Bentley 1975], [Friedman, Bentley & Finkel 1977] • Univariate axis-aligned splits • Split on widest dimension • O(N log N) to build, O(N) space")
18
A kd-tree: level 1

19
A kd-tree: level 2

20
A kd-tree: level 3

21
A kd-tree: level 4

22
A kd-tree: level 5

23
A kd-tree: level 6

24
For higher dimensions: ball-trees (computational geometry)
")
25
We have a fast algorithm for Kernel Density Estimation (KDE) •Generalization of N-body algorithms (multipole expansions optional) •Dual kd-tree traversal: O(N) •Works in arbitrary dimension •The fastest method to date [Gray & Moore 2003]
![We have a fast algorithm for Kernel Density Estimation (KDE) •Generalization of N-body algorithms (multipole expansions optional) •Dual kd-tree traversal: O(N) •Works in arbitrary dimension •The fastest method to date [Gray & Moore 2003]](http://images.slideplayer.com/7/1878706/slides/slide_25.jpg "We have a fast algorithm for Kernel Density Estimation (KDE) •Generalization of N-body algorithms (multipole expansions optional) •Dual kd-tree traversal: O(N) •Works in arbitrary dimension •The fastest method to date [Gray & Moore 2003]")
26
We could just use the KDE algorithm for each class. But: •for the Gaussian kernel this is approximate •choosing the smoothing parameter to minimize (cross- validated) classification error is more accurate But we need a fast algorithm for the Nonparametric Bayes Classifier (NBC)
 classification error is more accurate But we need a fast algorithm for the Nonparametric Bayes Classifier (NBC).")
27
Leave-one-out cross-validation Observations: 1.Doing bandwidth selection requires only prediction. 2.To predict class label, we don’t need to compute the full densities. Just which one is higher. We can make a fast exact algorithm for prediction

28
Fast NBC prediction algorithm 1. Build a tree for each class

29
Fast NBC prediction algorithm 2. Obtain bounds on P(C)f(x q |C) for each class P(C 1 )f(x q |C 1 )P(C 2 )f(x q |C 2 ) xqxq
f(x q |C) for each class P(C 1 )f(x q |C 1 )P(C 2 )f(x q |C 2 ) xqxq.")
30
Fast NBC prediction algorithm 3. Choose the next node-pair with priority = bound difference P(C 1 )f(x q |C 1 )P(C 2 )f(x q |C 2 ) xqxq
f(x q |C 1 )P(C 2 )f(x q |C 2 ) xqxq.")
31
Fast NBC prediction algorithm 3. Choose the next node-pair with priority = bound difference P(C 1 )f(x q |C 1 )P(C 2 )f(x q |C 2 ) 50-100x speedup exact
f(x q |C 1 )P(C 2 )f(x q |C 2 ) x speedup exact.")
32
Main points of this talk 1.nonparametric Bayes classifier 2.can be made fast (algorithm design) 3.accurate and tractable science
 3.accurate and tractable science")
33
Resulting quasar catalog •100,563 UVX quasar candidates •Of 22,737 objects w/ spectra, 97.6% are quasars. We estimate 95.0% efficiency overall. (aka “purity”: good/all) •94.7% completeness w.r.t. g<19.5 UVX quasars from DR1 (good/all true) •Largest mag. range ever: 14.2<g<21.0 •[Richards et al. 2004, ApJ] •More recently, 195k quasars
 •94.7% completeness w.r.t. g<19.5 UVX quasars from DR1 (good/all true) •Largest mag. range ever: 14.2<g<21.0 •[Richards et al. 2004, ApJ] •More recently, 195k quasars.")
34
Cosmic magnification [Scranton et al. 2005] 13.5M galaxies, 195,000 quasars Most accurate measurement of cosmic magnification to date [Nature, April 2005] more flux more area

35
Next steps (in progress) •better accuracy via coordinate-dependent priors •5 magnitudes •use simulated quasars to push to higher redshift •use DR4 higher-quality data •faster bandwidth search •500k quasars easily, then 1M
 •better accuracy via coordinate-dependent priors •5 magnitudes •use simulated quasars to push to higher redshift •use DR4 higher-quality data •faster bandwidth search •500k quasars easily, then 1M")
36
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, more…
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_36.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, more….")
37
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest algs
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_37.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest algs.")
38
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_38.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg.")
39
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_39.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg.")
40
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_40.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, more… fastest alg.")
41
Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al. 2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al. 2005 in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al. 2005 PhyStat] •nonparametric regression •clustering: k-means and mixture models, others •support vector machines, maybe fastest alg we’ll see…
![Bigger picture •nearest neighbor (1-,k-,all-,approx,clsf) [Gray & Moore 2000], [Miller et al.](http://images.slideplayer.com/7/1878706/slides/slide_41.jpg "2003], etc. •n-point correlation functions [Gray & Moore 2000], [Moore et al. 2000], [Scranton et al. 2003], [Gray & Moore 2004], [Nichol et al in prep.] •density estimation (nonparametric) [Gray & Moore 2000], [Gray & Moore 2003], [Balogh et al. 2003] •Bayes classification (nonparametric) [Richards et al. 2004], [Gray et al PhyStat] •nonparametric regression •clustering: k-means and mixture models, others •support vector machines, maybe fastest alg we’ll see….")
42
Take-home messages •Estimating a density? Use kernel density estimation (KDE). •Classification problem? Consider the nonparametric Bayes classifier (NBC). •Want to do these on huge datasets? Talk to us, use our software. •Different computational/statistical problem? Grab me after the talk! agray@cc.gatech.edu
. •Want to do these on huge datasets. Talk to us, use our software. •Different computational/statistical problem. Grab me after the talk.")
Similar presentations





 María Nieto-Santisteban 1 Tobias Scholl 2 Alexander Szalay 1 Alfons Kemper 2 1. The Johns Hopkins University,>")






 Ed Lazowska Bill & Melinda Gates Chair in Computer Science & Engineering University of Washington August 2011.>")






