Download presentation
1
Tuning Oracle SQL The Basics of Efficient SQLThe Basics of Efficient SQL Common Sense Indexing The Optimizer –Making SQL Efficient Finding Problem Queries Oracle Enterprise Manager –Wait Event Interface

2
SELECTSELECT –FOR UPDATE Filtering –WHERE ORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BY The Basics of Efficient SQL * SELECT * FROM division; SELECT division_id, name, city, state, country FROM division; division_id SELECT division_id FROM division; * SELECT * FROM division; SELECT division_id, name, city, state, country FROM division; division_id SELECT division_id FROM division;

3
SELECT –FOR UPDATE Filtering –WHERE ORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BY The Basics of Efficient SQL Avoid unintentional full table scans LIKE '%a%' SELECT * FROM division WHERE country LIKE '%a%'; Match indexes Exact hits (equality) WHERE division_id = 1 SELECT * FROM division WHERE division_id = 1; Range scans / skip scans / full index scans EXISTS (correlate) faster than IN Biggest filters first Full table scans can sometimes be faster Avoid unintentional full table scans LIKE '%a%' SELECT * FROM division WHERE country LIKE '%a%'; Match indexes Exact hits (equality) WHERE division_id = 1 SELECT * FROM division WHERE division_id = 1; Range scans / skip scans / full index scans EXISTS (correlate) faster than IN Biggest filters first Full table scans can sometimes be faster
 WHERE division_id = 1 SELECT * FROM division WHERE division_id = 1; Range scans / skip scans / full index scans EXISTS (correlate) faster than IN Biggest filters first Full table scans can sometimes be faster Avoid unintentional full table scans LIKE %a% SELECT * FROM division WHERE country LIKE %a% ; Match indexes Exact hits (equality) WHERE division_id = 1 SELECT * FROM division WHERE division_id = 1; Range scans / skip scans / full index scans EXISTS (correlate) faster than IN Biggest filters first Full table scans can sometimes be faster")
4
The Basics of Efficient SQL Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT SELECT division_id FROM division ORDER BY division_id; by WHERE SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT SELECT DISTINCT(state) FROM division ORDER BY state; by indexes SELECT division_id FROM division ORDER BY division_id; Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT SELECT division_id FROM division ORDER BY division_id; by WHERE SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT SELECT DISTINCT(state) FROM division ORDER BY state; by indexes SELECT division_id FROM division ORDER BY division_id; SELECT –FOR UPDATE Filtering –WHERE ORDER BYORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BY
 by SELECT SELECT division_id FROM division ORDER BY division_id; by WHERE SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT SELECT DISTINCT(state) FROM division ORDER BY state; by indexes SELECT division_id FROM division ORDER BY division_id; Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT SELECT division_id FROM division ORDER BY division_id; by WHERE SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT SELECT DISTINCT(state) FROM division ORDER BY state; by indexes SELECT division_id FROM division ORDER BY division_id; SELECT –FOR UPDATE Filtering –WHERE ORDER BYORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BY")
5
SELECT –FOR UPDATE Filtering –WHERE ORDER BYORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BY The Basics of Efficient SQL Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT division_id SELECT division_id FROM division ORDER BY division_id; by WHERE division_id < 10 SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY GROUP BY state SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT DISTINCT(state) SELECT DISTINCT(state) FROM division ORDER BY state; by indexes division_id SELECT division_id FROM division ORDER BY division_id; Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT division_id SELECT division_id FROM division ORDER BY division_id; by WHERE division_id < 10 SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY GROUP BY state SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT DISTINCT(state) SELECT DISTINCT(state) FROM division ORDER BY state; by indexes division_id SELECT division_id FROM division ORDER BY division_id;
 by SELECT division_id SELECT division_id FROM division ORDER BY division_id; by WHERE division_id < 10 SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY GROUP BY state SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT DISTINCT(state) SELECT DISTINCT(state) FROM division ORDER BY state; by indexes division_id SELECT division_id FROM division ORDER BY division_id; Resorts on result after WHERE and GROUP BY Dont repeat sorting (ORDER BY often ignored) by SELECT division_id SELECT division_id FROM division ORDER BY division_id; by WHERE division_id < 10 SELECT * FROM division WHERE division_id < 10 ORDER BY division_id; GROUP BY GROUP BY state SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; by DISTINCT DISTINCT(state) SELECT DISTINCT(state) FROM division ORDER BY state; by indexes division_id SELECT division_id FROM division ORDER BY division_id;")
6
The Basics of Efficient SQL GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE SELECT state, COUNT(state) FROM division WHERE state = 'NY' GROUP BY state; not HAVING SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = 'NY'; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE SELECT state, COUNT(state) FROM division WHERE state = 'NY' GROUP BY state; not HAVING SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = 'NY'; SELECT –FOR UPDATE Filtering –WHERE ORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BYGROUP BY –Use WHERE not HAVING
 FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE SELECT state, COUNT(state) FROM division WHERE state = NY GROUP BY state; not HAVING SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = NY ; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE SELECT state, COUNT(state) FROM division WHERE state = NY GROUP BY state; not HAVING SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = NY ; SELECT –FOR UPDATE Filtering –WHERE ORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BYGROUP BY –Use WHERE not HAVING")
7
SELECT –FOR UPDATE Filtering –WHERE ORDER BY –often ignored by the Optimizer –depends on query and index complexity –may need ORDER BY using composite indexes GROUP BYGROUP BY –Use WHERE not HAVING The Basics of Efficient SQL GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) HAVING COUNT(state) > 1 SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE WHERE state = 'NY' SELECT state, COUNT(state) FROM division WHERE state = 'NY' GROUP BY state; not HAVING HAVING state = 'NY' SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = 'NY'; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) HAVING COUNT(state) > 1 SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE WHERE state = 'NY' SELECT state, COUNT(state) FROM division WHERE state = 'NY' GROUP BY state; not HAVING HAVING state = 'NY' SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = 'NY';
 FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) HAVING COUNT(state) > 1 SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE WHERE state = NY SELECT state, COUNT(state) FROM division WHERE state = NY GROUP BY state; not HAVING HAVING state = NY SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = NY ; GROUP BY SELECT state, COUNT(state) FROM division GROUP BY state ORDER BY state; HAVING (filters aggregate) HAVING COUNT(state) > 1 SELECT state, COUNT(state) FROM division GROUP BY state HAVING COUNT(state) > 1; use WHERE WHERE state = NY SELECT state, COUNT(state) FROM division WHERE state = NY GROUP BY state; not HAVING HAVING state = NY SELECT state, COUNT(state) FROM division GROUP BY state HAVING state = NY ;")
8
FunctionsFunctions –conversions –miss indexes –counteract with function based indexing –avoid using –DECODE –CASE expressions –set operators (UNION) Use sequencesUse sequences Use equality (=) or range scans (>)Use equality (=) or range scans (>) –avoid negatives (!=, NOT) –avoid LIKE The Basics of Efficient SQL
 Use sequencesUse sequences Use equality (=) or range scans (>)Use equality (=) or range scans (>) –avoid negatives (!=, NOT) –avoid LIKE The Basics of Efficient SQL")
9
JoinsJoins –avoid Cartesian Products –avoid anti joins –avoid outer joins –perhaps replace –multiple table complex joins –with subquery semi joins and inline views Be careful with viewsBe careful with views

10
Common Sense Indexing Dont always need indexesDont always need indexes –table with few columns –static data –small tables –appended tables (SQL*Loader) How to indexHow to index –single column surrogate sequences –dont override PK and FKs –avoid nullable columns
 How to indexHow to index –single column surrogate sequences –dont override PK and FKs –avoid nullable columns")
11
Common Sense Indexing Read write indexingRead write indexing –BTree Often read onlyOften read only –Bitmaps –IOTs –Clusters

12
Common Sense Indexing Read write indexing –BTree –function based –can help a lot –get out of control –everybody wants one –reverse key –surrogate keys –High insertion rates –not DW –Oracle RAC

13
Common Sense Indexing Often read onlyOften read only –Bitmaps –can be much faster than BTrees –can deteriorate drastically over time –twice as fast in my book –at a previous client –1 year of DML activity –100s of times slower –problem was nobody knew why –and nobody wanted to change anything

14
Common Sense Indexing Often read onlyOften read only –IOTs –small number of columns –small tables –heard good things in Oracle RAC –even highly active DML environments

15
Is intelligent –better with simple queries Is usually correct Nothing is set in stone Verify SQL code efficiency EXPLAIN PLAN –use EXPLAIN PLAN –SET AUTOTRACE ON EXPLAIN –$ORACLE_HOME/rdbms/admin/utlxplan.sql The Optimizer

16
Everything cost based –rule based is redundant statisticsMaintain statistics Dynamic samplingDynamic sampling –OPTIMIZER_DYNAMIC_SAMPLING Set TIMED_STATISTICS HistogramsHistograms –maintain as for statistics –use for unevenly distributed indexes The Optimizer

17
TablesTables –full Table scans –small static tables –reading most of the rows –over 10% for the Optimizer –reading deleted rows –parallel table scans –sample table scans –retrieve only portion of table by blocks or % –SELECT * FROM generalledger SAMPLE(0.001); –ROWID scans The Optimizer
; –ROWID scans The Optimizer")
18
IndexesIndexes –index unique scan –index range scan –reverse order index range scan –index skip scan –index full scan –fast full index scan –others (very specific) The Optimizer
 The Optimizer")
19
JoinsJoins –nested loop join –most efficient –row sets both small –one large and one small row set –one sorted –hash join –both large with little difference –temporary hash table generated The Optimizer

20
More on joinsMore on joins –sort merge join –inefficient –both rows sets sorted then merge sorted –other join types –semi joins –bitmap joins –star queries –Cartesian joins –outer joins (nested, hash or sort merge) The Optimizer
 The Optimizer")
21
Hints can change thingsHints can change things –influence the optimizer CURSOR_SHARING configuration parameter FORCE (OLTP) EXACT (DW) FIRST or ALL_ROWS DYNAMIC_SAMPLING –change table scans FULL The Optimizer
 EXACT (DW) FIRST or ALL_ROWS DYNAMIC_SAMPLING –change table scans FULL The Optimizer")
22
More on hintsMore on hints –change index scans INDEX_ASC, INDEX_DESC INDEX_FFS INDEX_JOIN (join indexes) INDEX_SS_ASC or INDEX_SS_DESC NO_INDEX, NO_INDEX_FFS or NO_INDEX_SS –change joins can change join type and influence with parameters –parallel SQL
 INDEX_SS_ASC or INDEX_SS_DESC NO_INDEX, NO_INDEX_FFS or NO_INDEX_SS –change joins can change join type and influence with parameters –parallel SQL")
23
Finding Problem Queries EXPLAIN PLANEXPLAIN PLAN –SET AUTOTRACE ON EXPLAIN –$ORACLE_HOME/rdbms/admin/utlxplan.sql SQL Trace and TKPROF

24
Wait Event Interface Finding Problem Queries Performance views V$SQLAREA executions parsing sorting disk and buffer reads fetching V$SQL optimizer cost CPU time elapsed time Performance views V$SQLAREA executions parsing sorting disk and buffer reads fetching V$SQL optimizer cost CPU time elapsed time

25
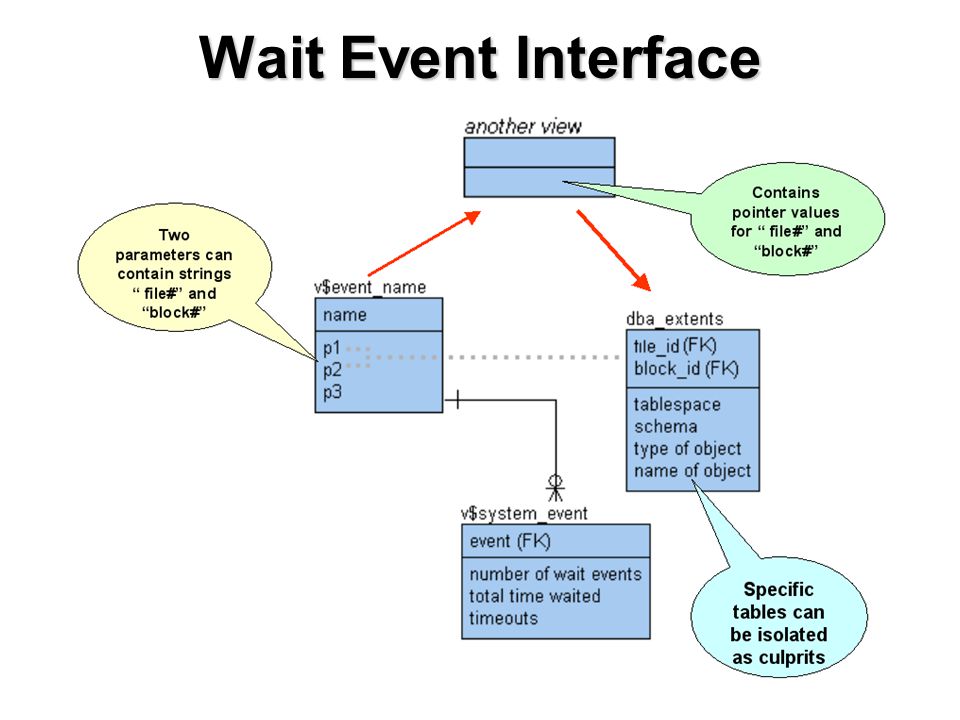
Wait Event Interface

32
Performance overview

33
Database health overview

34
Drilldown

35
More drilldown

36
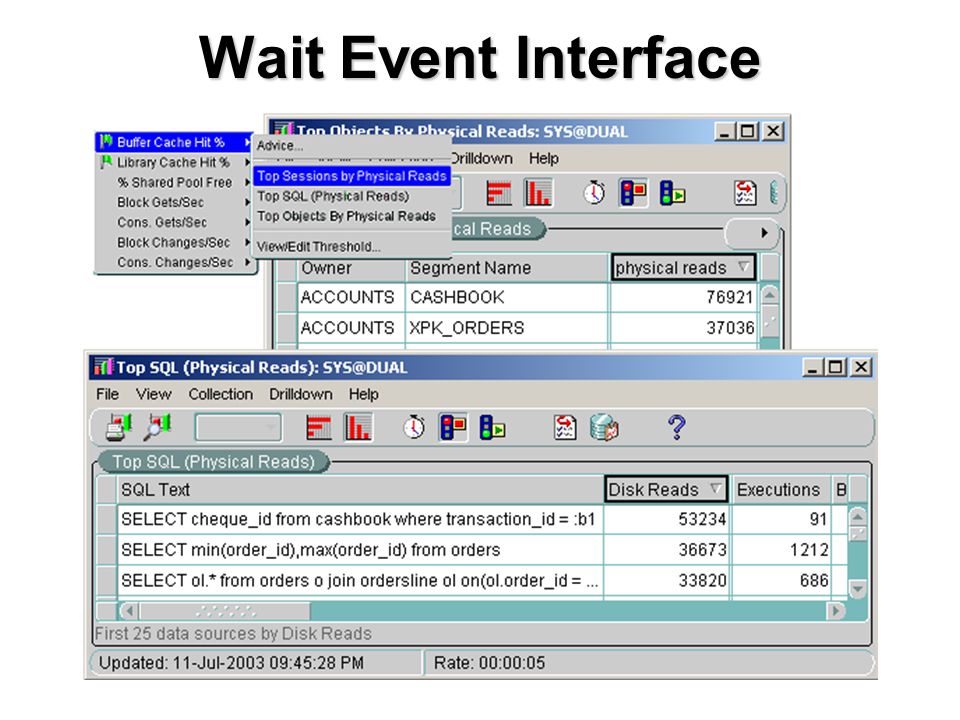
TopSQL

37
EXPLAIN PLAN

38
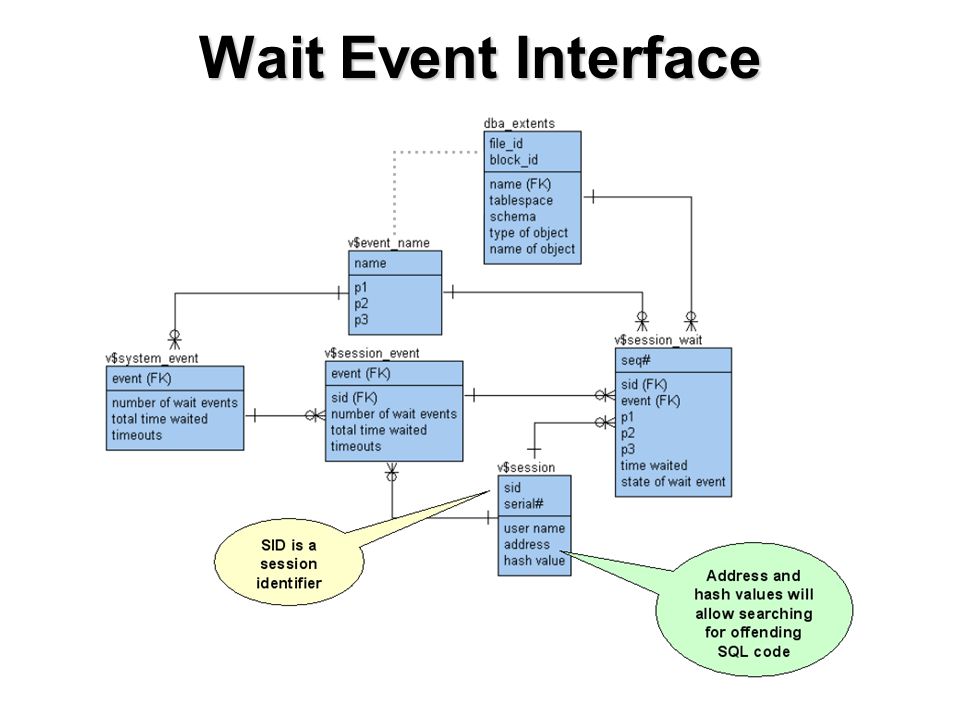
Wait Event Interface

41
Use the help files Use the HELP FILES in Oracle Enterprise Manager











Leccotech Create Index Redefine Main memory structures (SGA in Oracle) Change the Block Size Materialized Views,>")








>")



>")

