Download presentation
Presentation is loading. Please wait.

1
Issues in Designing a Confidentiality Preserving Model Server by Philip M Steel & Arnold Reznek

2
Talk Outline Background Basic design Description of operation Confidentiality outline Constraints on universe formation Other constraints Summary

3
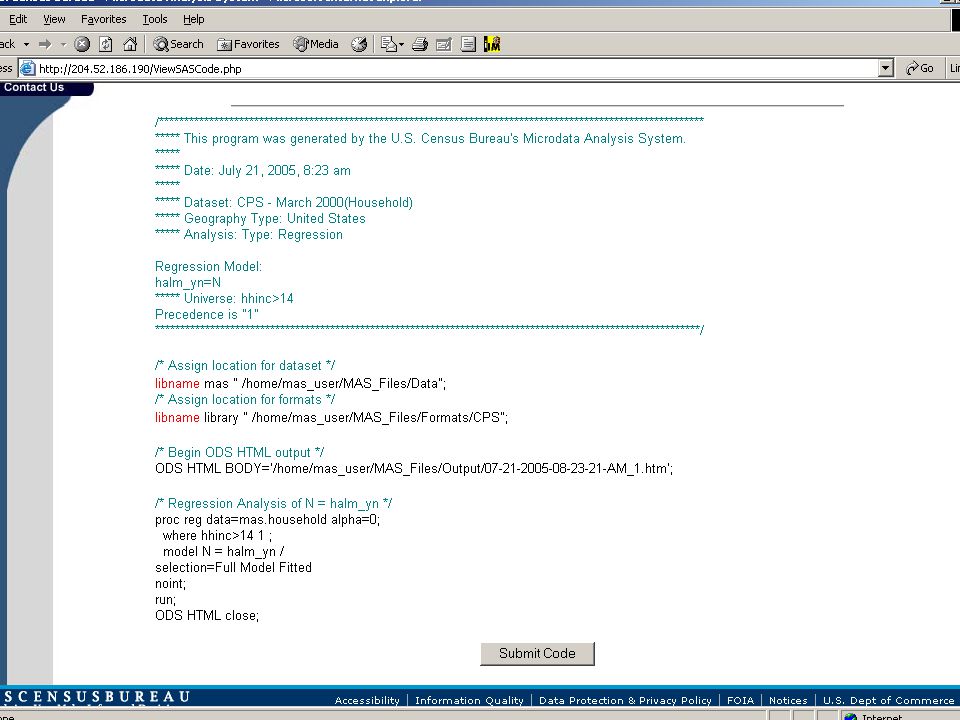
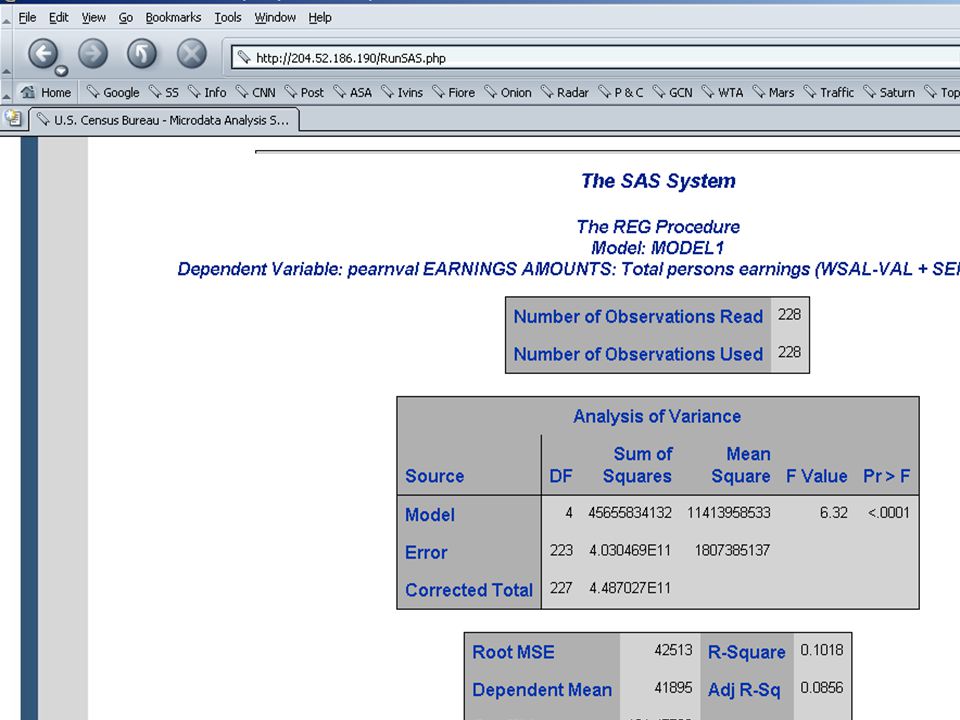
Background PUBLIC remote access to confidential data Restriction of queries and responses rather than the registering and monitoring the user Current population survey (CPS), employment and economic well-being; demographic supplement Software development by Synectics HTML, mySQL, php, to develop the query … SAS as the statistical package run against the data
, employment and economic well-being; demographic supplement Software development by Synectics HTML, mySQL, php, to develop the query … SAS as the statistical package run against the data")
4
Risk Model for Microdata Intruder has access to record linkage software and identified data sources Disclosure occurs if the intruder is successful in linking his identified data with the published microdata

5
Risk Model for a Model Server Intruder has access to record linkage software and identified data sources Intruder uses model server to reconstruct microdata for both the variables overlapping his data sources and a sensitive variable Disclosure occurs if the intruder is successful in linking his identified data with the reconstructed microdata and has valid estimate of a sensitive characteristic or value

6
Basic Design Choice Enable: Choose which functions will operate –Must construct a friendly interface –Limited to the procedures developed –Safe from unknown code Disable: Choose which functions will not operate –User free to program within disabling constraints –No limit on complexity –Must be monitored (human, program or mix)
")
7
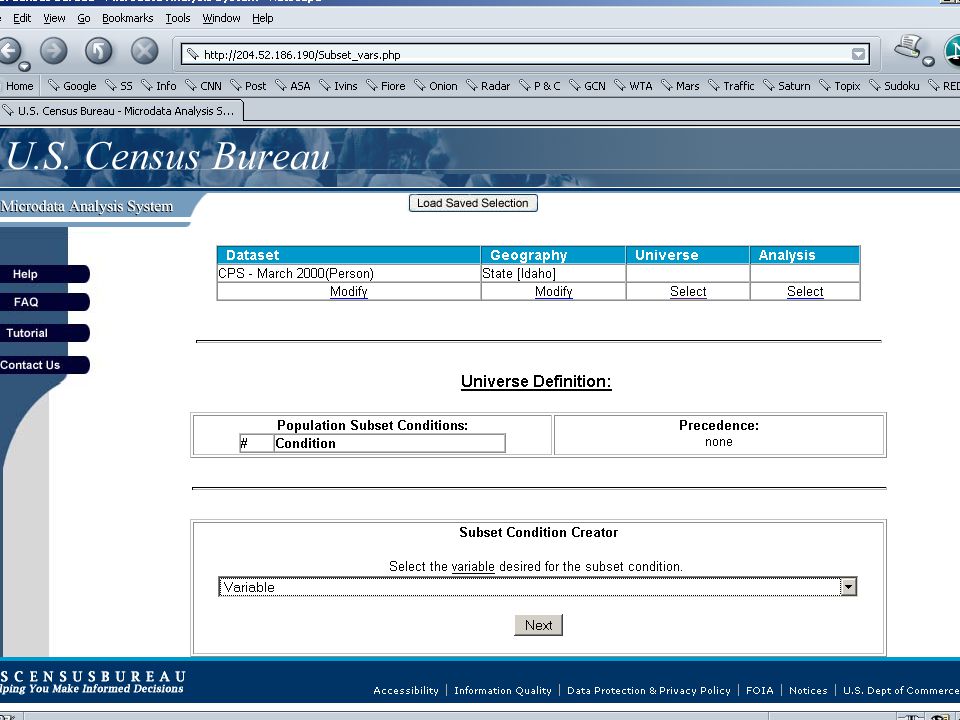
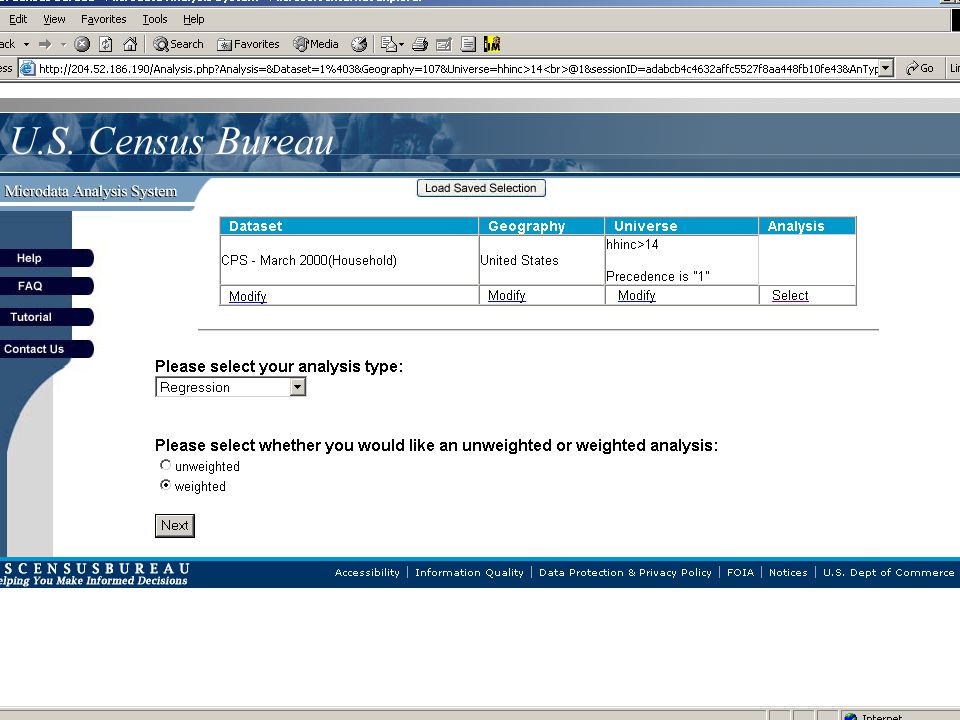
Operation User visits web site, chooses data set, explores data, chooses geography, analysis type User chooses population, constructs model, selects output Web site constructs code to send behind firewall Code checked and run against data at Census Results checked and returned to user

16
Structure of Confidentiality Rules Data preparation Data exploration Model universe formation Model Statement Model Output

17
Data exploration rules Users may request tables for categorical variables and numeric recodes up to e1 dimensions. (start e1=4 including geo) User may transform numeric recodes using a limited set of functions: log, root, square.
 User may transform numeric recodes using a limited set of functions: log, root, square..")
18
Universe formation: Categorical Variables Example: Hispanic heads of household with a college degree. Conditions: X 1 =H,X 2 =1,X 3 =5 (table cell) Implication: Data preparation must support safe lower dimensional tables
 Implication: Data preparation must support safe lower dimensional tables.")
19
Universe formation rules: Categorical Variables Limit on the number of categorical variables (u1=3) Minimum on the size of the universe selected (u2=75)
 Minimum on the size of the universe selected (u2=75)")
20
Universe Formation: Numeric Variables Example: Families in poverty Condition: Family income<18,500. Or Family income<18,501? Implication: Rounding or pre-assigned cutpoints.

21
Universe formation rules: Numeric variables Users will select categorical variables first Numeric variables can be used only at pre-assigned cutpoints. The number of observations in the whole CPS universe between cutpoints shall be at least u3 for every numeric variable. (start u3=80)
.")
22
Universe formation rules (cont) If a cutpoint is used in universe formation then the difference in the size of the model universe obtained by incrementing the cutpoint up or down cannot be less than u4. (start u4=4) The universe for the model must have at least u2 observations. (start u2=75) There will be no cutpoints above the 97 th percentile of nonzero points or the last half percentile of all points.
 The universe for the model must have at least u2 observations. (start u2=75) There will be no cutpoints above the 97 th percentile of nonzero points or the last half percentile of all points..")
23
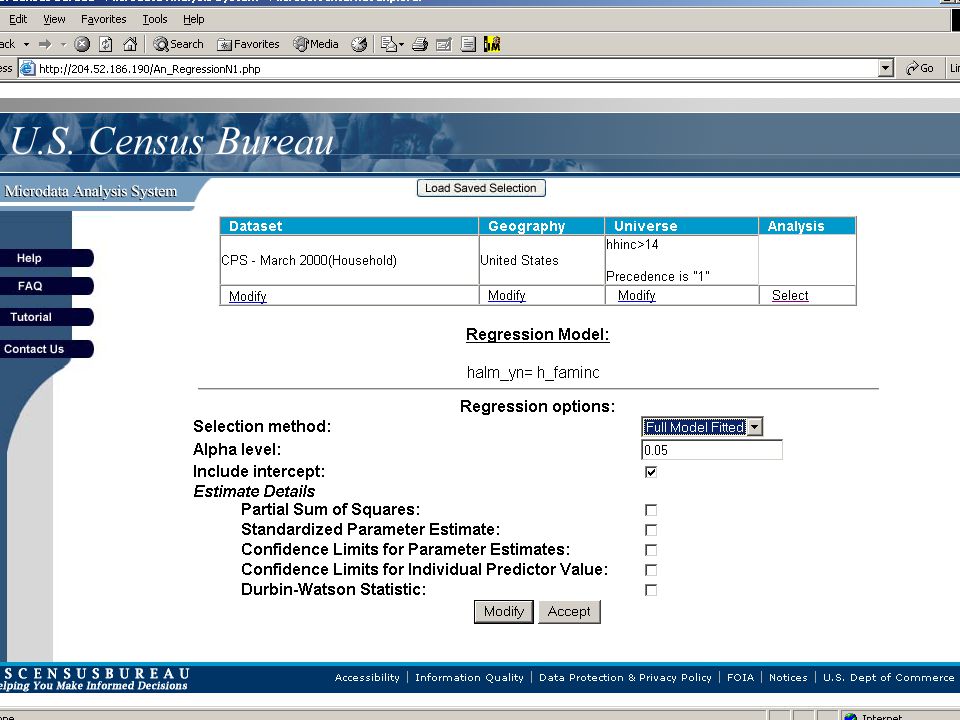
Model statements rules At most m1 variables may be used in the model statement (start m1=20) Dummy variables must distinguish at least m2 observations (start m2=20) No interaction term may involve more than 4 variables. (m3=4) No model involving 3 or more variables can be fully interacted. (m4=3)
 No model involving 3 or more variables can be fully interacted. (m4=3).")
24
Model Output Residuals will be based on synthetic data Limit on the number of significant digits? R 2 cannot be 1? Rules for other diagnostics

25
Synthetic Residuals Users may see synthetic bar charts or distributions and synthetic 2-way plots. Synthetic data must be generated from fixed random number starts and topcoded (and bottom coded where appropriate) at 4 standard deviations from the mean.
 at 4 standard deviations from the mean..")
26
Data preparation The topcode for numeric data needs to be calculated Cutpoints must be determined Separate lists of variables for exploration, universe formation, dependent and independent variables, model estimation Standard recodes added Inference from the collection of all 4-way categorical tables checked

27
Major Hurdles Implementing facility for dummy variables Presentation of geographic options Implementing synthetic residuals Architecture for differing variable roles

28
Future development Relaxation of top codes Implementation of model variance estimation (NSO weighting) Introduction of new dataset Introduction of new statistical procedures Facility to add contextual data or merge files Use of non-sampled data
 Introduction of new dataset Introduction of new statistical procedures Facility to add contextual data or merge files Use of non-sampled data")
29
Overview Avoids (as much as possible) tests which accept or reject a users choice. Restricts the dimension of the data access. Has some flexibility in setting system confidentiality parameters. Changes the intruder model. Introduces a modification of k-anonymity.

30
My thanks to Jerry Reiter, Laura Zayatz and Stephen Wenck http://204.52.186.190/ Contact: philip.m.steel@census.gov

Similar presentations






: A Tool for Data Dissemination Disclaimer: The views expressed are those of the authors and not necessarily those of.>")
 at SURS Andreja Smukavec General Methodology and Standards Sector.>")











 asbl 17, rue des Pommiers L-2343 Luxembourg –City Tél : +(352) 26 00 30 20 Fax: +(352) 26 00.>")


