Download presentation
Presentation is loading. Please wait.

1
Monitoring year-to-year variation in structural business statistics Contribution to Q2008 – Rome, 9 July 2008 Session: Editing and Imputation I Guy.Vekeman@ec.europa.eu, ESTAT – G1

2
Structural Business Statistics (SBS) Yearly statistics covering the Business Economy (NACE sections C-K). Geographical coverage: EEA + candidate countries Many characteristics: financial, employment… Multiple breakdowns: activity, size class, region Produced by National Statistical Institutes, using uniform definitions (but data collection methodologies may vary) Role of ESTAT: collecting, validating data flows, confidentiality treatment, publishing data series. Actors
 Role of ESTAT: collecting, validating data flows, confidentiality treatment, publishing data series. Actors.")
3
Data validation: a macro editing tool Main variation causes of aggregates in data flows: –performance of the individual enterprises –change in the composition of the set of enterprises –raw data error (misreporting) –data processing error (editing flaw).
 –data processing error (editing flaw).")
4
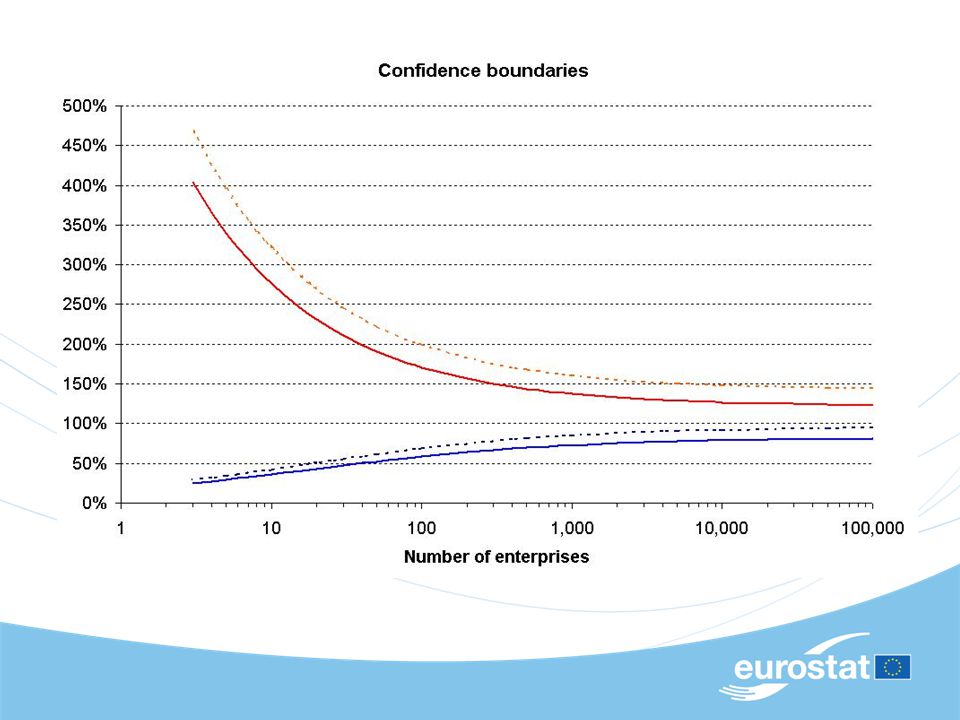
Essential characteristics of macro-editing tool not to overload correspondents with false alerts suitable threshold to single out influential anomalies Previous practice Symmetric [-20%, +20%] confidence interval Applied to all (but a few) characteristics Possibly generating hundreds (if not thousands) of anomalous variations Skilful application required by ESTAT database manager Small aggregates vary more -> Unreasonable burden for NSI of small countries
![Essential characteristics of macro-editing tool not to overload correspondents with false alerts suitable threshold to single out influential anomalies Previous practice Symmetric [-20%, +20%] confidence interval Applied to all (but a few) characteristics Possibly generating hundreds (if not thousands) of anomalous variations Skilful application required by ESTAT database manager Small aggregates vary more -> Unreasonable burden for NSI of small countries](http://images.slideplayer.com/4/1426019/slides/slide_4.jpg "Essential characteristics of macro-editing tool not to overload correspondents with false alerts suitable threshold to single out influential anomalies Previous practice Symmetric [-20%, +20%] confidence interval Applied to all (but a few) characteristics Possibly generating hundreds (if not thousands) of anomalous variations Skilful application required by ESTAT database manager Small aggregates vary more -> Unreasonable burden for NSI of small countries")
5
Factors influencing evolution of SBS data Macro-economic –Economic growth –Inflation PPI/CPI (SBS data are in current prices) –Currency fluctuations Micro economic –Prospering of enterprises –Business demography in the sector Administrative: business register related –Registering enterprises / deregistering merged, closed down or suspended units –Activity classification of enterprises <- can be compensated for
 –Currency fluctuations Micro economic –Prospering of enterprises –Business demography in the sector Administrative: business register related –Registering enterprises / deregistering merged, closed down or suspended units –Activity classification of enterprises <- can be compensated for")
6
Heuristics: Basic assumptions Assumptions: –year-to-year variations (YTYV) of individual enterprises = set of random observations –Enterprises very unevenly distributed in size and the YTYV of large corporation influential on the sector average. –Economies of scale come to our rescue: since large YTYV more typical for small companies. –variance of average: YTYV ~ 1/n –Standard deviation on the average Knowing economic growth G and inflation I, change of the aggregates could be estimated. –So can we expect V t є [V t-1 * (1+G t )*(1+I t )*(1 ± 2.σ/n t-1 )] with 95% probability ? No, because of several sources of bias
*(1+I t )*(1 ± 2.σ/n t-1 )] with 95% probability . No, because of several sources of bias.")
7
Heuristics: sources of bias Non-financial business economy: NACE C-K \ J: not a full coverage Stratification by NACE: non-random sample -> heavily biased sector evolution, moreover: –We use one unique inflation number (CPI) instead of array of sectoral PPI GDP is a sum of values added. Other characteristics: possibly different evolution Result of bias: expectation value => expectation interval

8
Heuristics: variability of characteristics A few characteristics can be negative of close to zero: –Change in stocks or work in progress (frequently) –Gross operating surplus (rarely) –Value added (almost never) Consequences: –Volatile characteristics -> large % YTYV –Variance increase of the characteristics Measures taken: –Dropping volatile characteristics –Widening confidence limits of expectation interval (lack of predictability extra bias source)
 –Gross operating surplus (rarely) –Value added (almost never) Consequences: –Volatile characteristics -> large % YTYV –Variance increase of the characteristics Measures taken: –Dropping volatile characteristics –Widening confidence limits of expectation interval (lack of predictability extra bias source)")
9
Heuristics: Bringing it together (Standard) Confidence interval limited by a Standard lower boundary (SLB) and standard upper boundary (SUB) Adapted boundaries: number of enterprises in year t-1 SLB / ( ) ; SUB * ( ) 2. σ imply 95% confidence limits, leaving 5% anomalies (too many) … but we have no idea about σ. => 2. σ is considered a parameter: We fit the value 4 to obtain an 80% reduction of the number of anomalies as compared to previous practice.
 … but we have no idea about σ. => 2. σ is considered a parameter: We fit the value 4 to obtain an 80% reduction of the number of anomalies as compared to previous practice..")
10
Heuristics: Method applied Standard Confidence Interval: –width depending on characteristics –tuned using CPI and/or growth data (compare in national currency) –Symmetrical on log-scale Tuned interval for Business demography characteristics. –SLB / ( ) < (n t /n t-1 ) < SUB*( ) Tuned interval for Financial characteristics –[SLB / (1+…) * (1+real growth) * (1+inflation rate) ; SUB*(1+ …) * (1+real growth)*(1+inflation rate)] Tuned interval for Employment characteristics –[SLB / (1+…) * (1+real growth); SUB*(1+ …) * (1+real growth)]
 < (n t /n t-1 ) < SUB*( ) Tuned interval for Financial characteristics –[SLB / (1+…) * (1+real growth) * (1+inflation rate) ; SUB*(1+ …) * (1+real growth)*(1+inflation rate)] Tuned interval for Employment characteristics –[SLB / (1+…) * (1+real growth); SUB*(1+ …) * (1+real growth)].")
11
CharacteristicsInflation?Growth?SLBSUB Number of enterprises NN0.821.22 Turnover YY0.821.22 Purchases YY0.821.22 Value added YY0.771.30 Personnel costs YY0.821.22 Number of employees NY0.821.22 Turnover / person empl. YN0.851.18 Purchases/ product.value NN0.851.15 Confidence interval standard lower and upper boundaries

13
Implementation and discussion Deterministic method => programmed in Access for distribution Test more tolerant on small aggregates => Reduced burden for small MS (confirmation in 2003-04 field test) Raising awareness on influential changes 'macro-editing tool: signalling suspicious aggregates: –Business demographic change? –Micro-data to be reviewed? Selective editing of suspect subset. –Same macro editing tool front end (NSI) and back end (ESTAT) -> shorter validation cycle Field test: Number of anomalies varies between 0.37% and 4.6% (!) Correlation low (0.15) between country size (number of inhabitants) and anomaly frequency: small and large MS are treated on equal footing.
 and back end (ESTAT) -> shorter validation cycle Field test: Number of anomalies varies between 0.37% and 4.6% (!) Correlation low (0.15) between country size (number of inhabitants) and anomaly frequency: small and large MS are treated on equal footing..")
Similar presentations