Download presentation
Presentation is loading. Please wait.

1
A BigData Tour – HDFS, Ceph and MapReduce These slides are possible thanks to these sources – Jonathan Drusi - SCInet Toronto – Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing – SICS; Yahoo! Developer Network MapReduce Tutorial

2
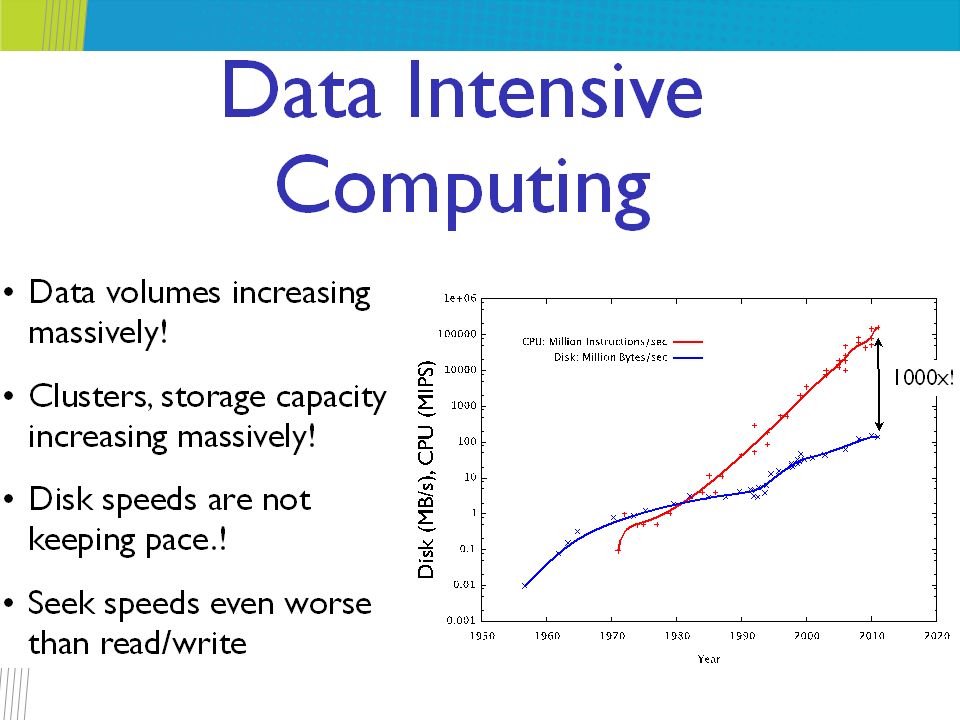
Data Management and Processing Data intensive computing Concerns with the production, manipulation and analysis of data in the range of hundreds of megabytes (MB) to petabytes (PB) and beyond A range of supporting parallel and distributed computing technologies to deal with the challenges of data representation, reliable shared storage, efficient algorithms and scalable infrastructure to perform analysis
 to petabytes (PB) and beyond A range of supporting parallel and distributed computing technologies to deal with the challenges of data representation, reliable shared storage, efficient algorithms and scalable infrastructure to perform analysis")
3
Challenges Ahead Challenges with data intensive computing Scalable algorithms that can search and process massive datasets New metadata management technologies that can scale to handle complex, heterogeneous and distributed data sources Support for accessing in-memory multi-terabyte data structures High performance, highly reliable petascale distributed file system Techniques for data reduction and rapid processing Software mobility to move computation where data is located Hybrid interconnect with support for multi-gigabyte data streams Flexible and high performance software integration technique Hadoop A family of related project, best known for MapReduce and Hadoop Distributed File System (HDFS)
")
5
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

9
Why Hadoop Drivers 500M+ unique users per month Billions of interesting events per day Data analysis is key Need massive scalability PB’s of storage, millions of files, 1000’s of nodes Need to do this cost effectively Use commodity hardware Share resources among multiple projects Provide scale when needed Need reliable infrastructure Must be able to deal with failures – hardware, software, networking Failure is expected rather than exceptional Transparent to applications very expensive to build reliability into each application The Hadoop infrastructure provides these capabilities

10
Introduction to Hadoop Apache Hadoop Based on 2004 Google MapReduce Paper Originally composed of HDFS (distributed F/S), a core-runtime and an implementation of Map-Reduce Open Source – Apache Foundation project Yahoo! is Apache Platinum Sponsor History Started in 2005 by Doug Cutting Yahoo! became the primary contributor in 2006 Yahoo! scaled it from 20 node clusters to 4000 node clusters today Portable Written in Java Runs on commodity hardware Linux, Mac OS/X, Windows, and Solaris

11
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

12
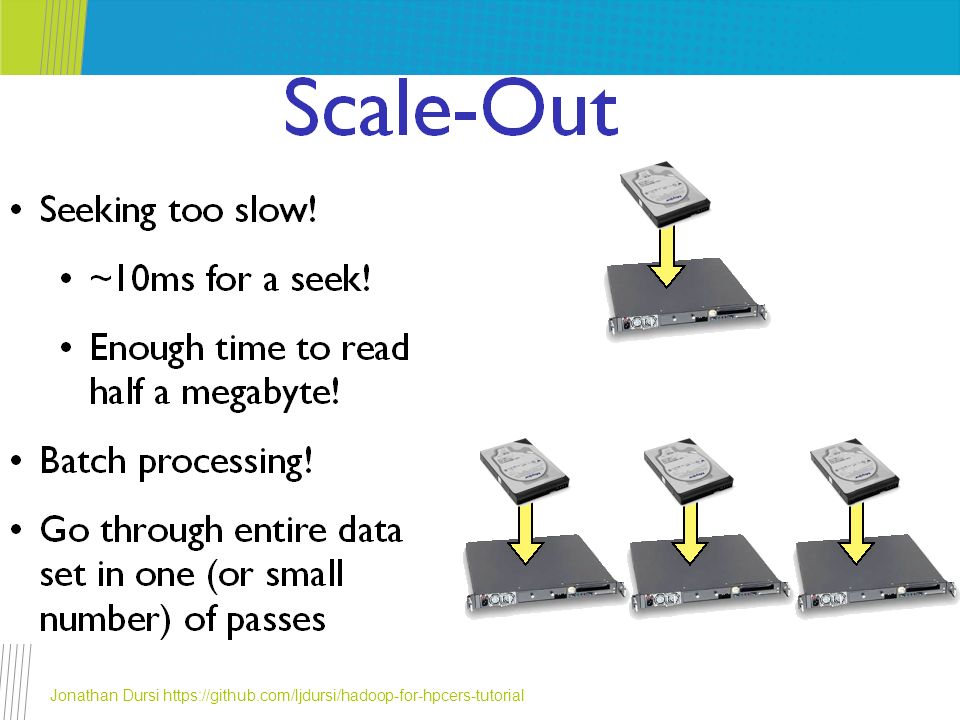
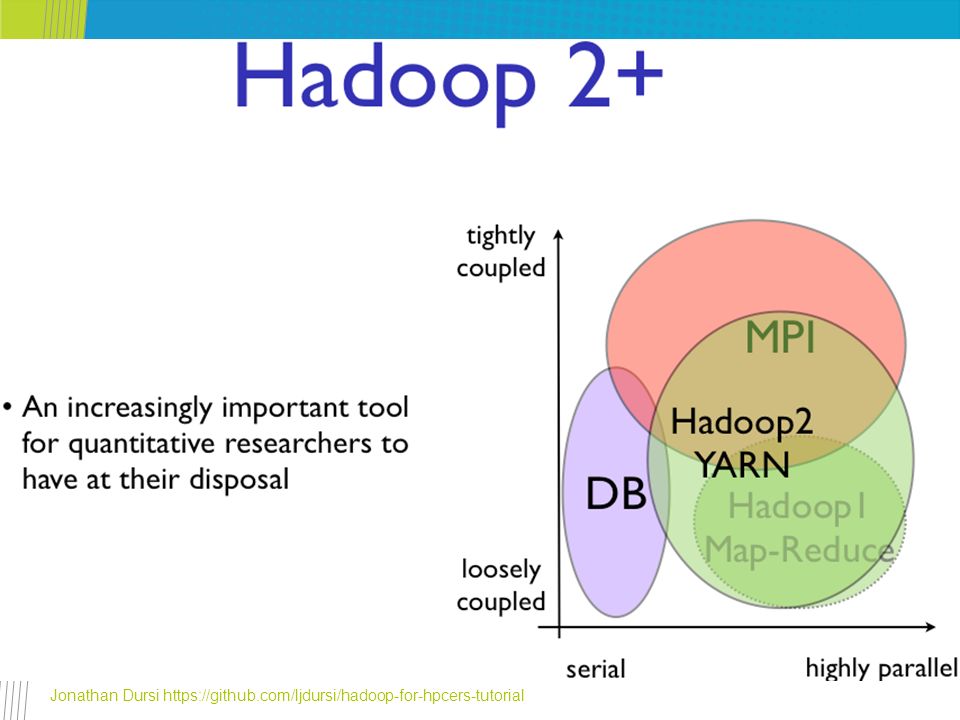
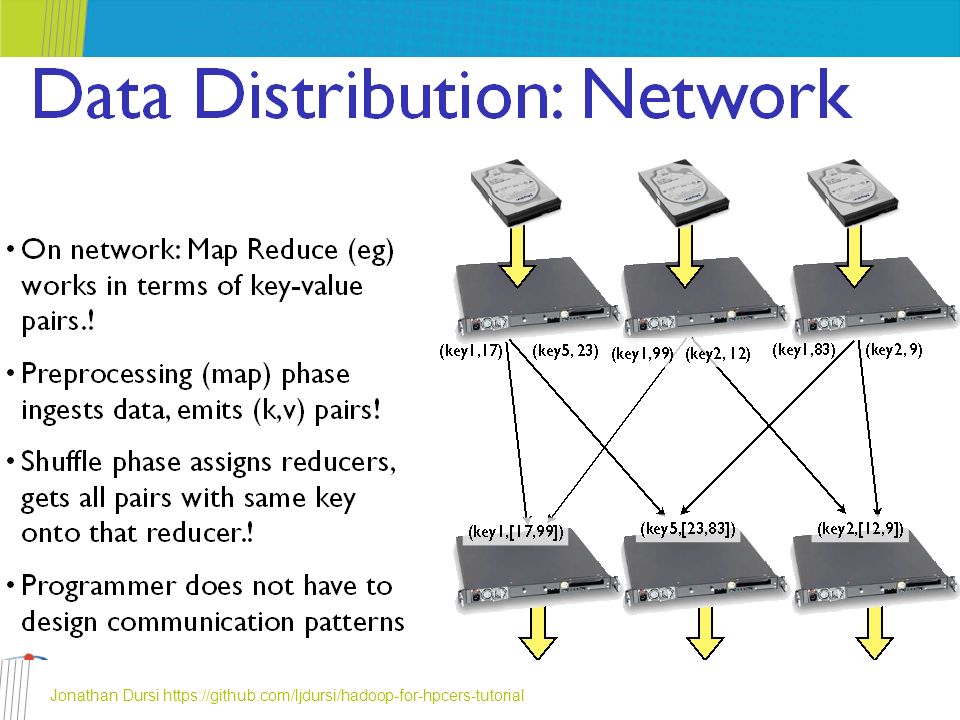
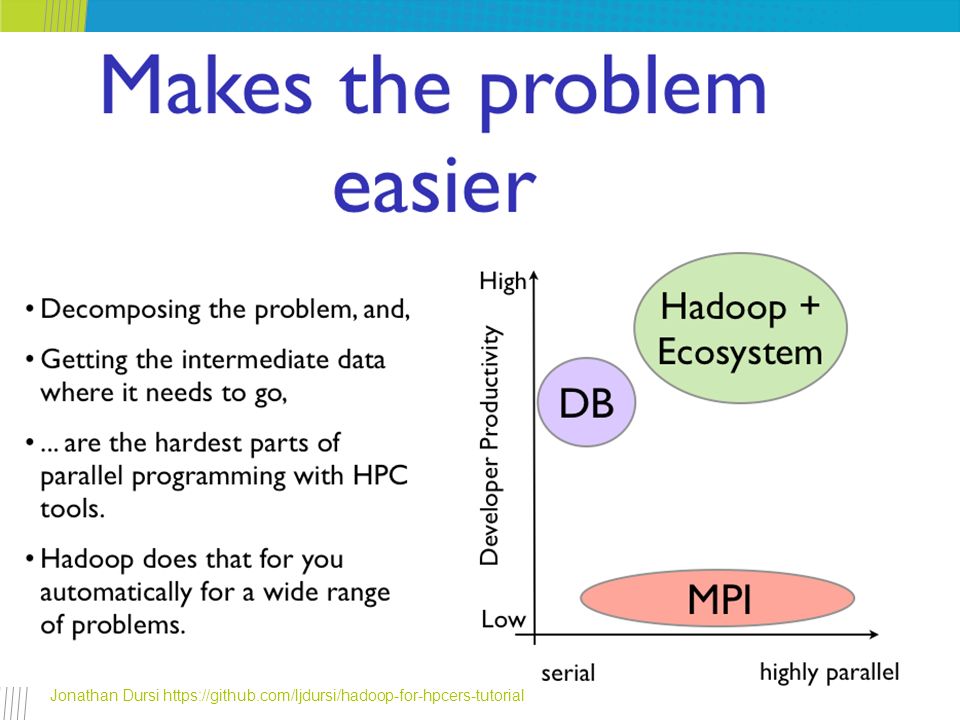
HPC vs Hadoop HPC attitude – “The problem of disk-limited, loosely-coupled data analysis was solved by throwing more disks and using weak scaling” Flip-side: A single novice developer can write real, scalable, 1000+ node data-processing tasks in Hadoop-family tools in an afternoon MPI... less so Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

20
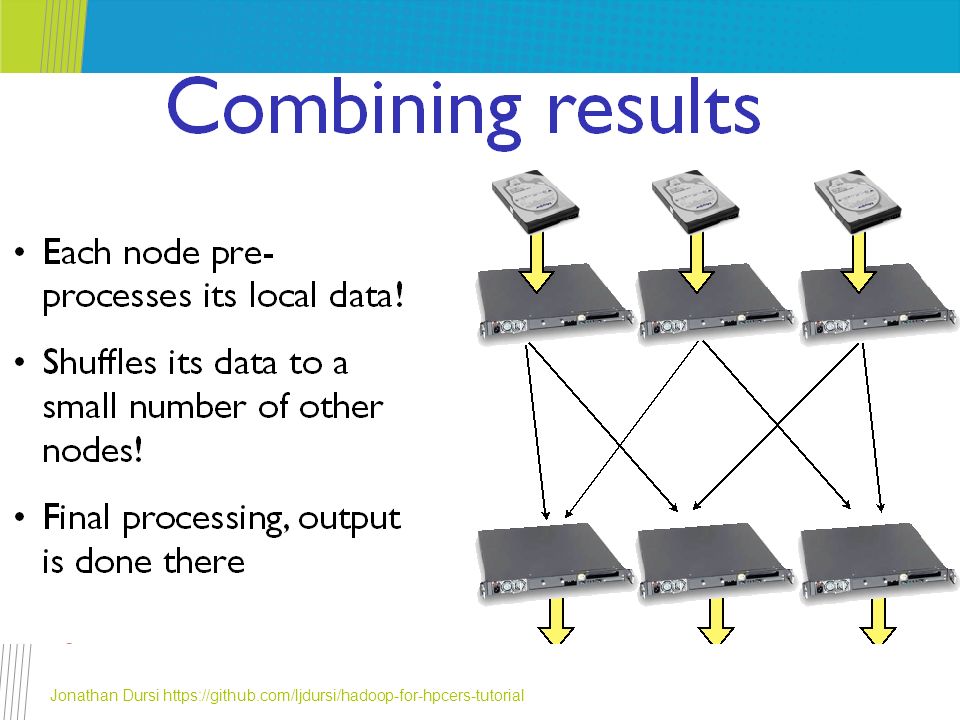
Everything is converging – 1/2 Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

21
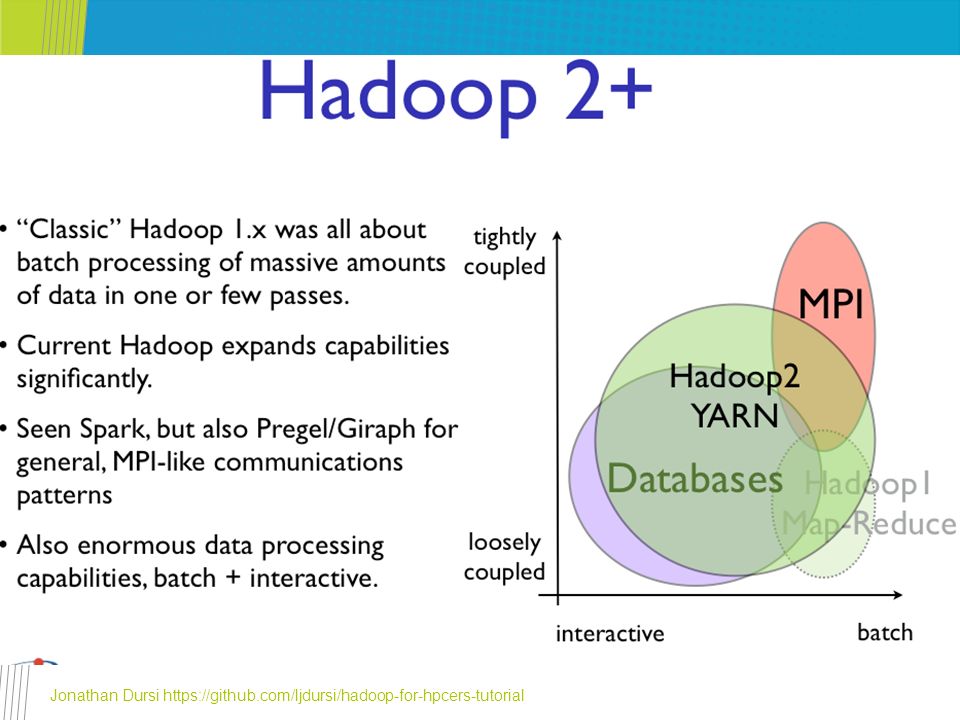
Everything is converging – 2/2 Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

22
Big Data Analytics Stack Amir Payberah https://www.sics.se/~amir/dic.htm

23
Big Data – Storage (sans POSIX) Amir Payberah https://www.sics.se/~amir/dic.htm
 Amir Payberah")
24
Big Data - Databases Amir Payberah https://www.sics.se/~amir/dic.htm

25
Big Data – Resource Management Amir Payberah https://www.sics.se/~amir/dic.htm

26
YARN – 1/3 To address Hadoop v1 deficiencies with scalability, memory usage and synchronization, the Yet Another Resource Negotiator (YARN) Apache sub-project was started Previously a JobTracker service ran on each node. Its roles were then split into separate daemons for Resource management Job scheduling/monitoring Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/

27
YARN – 2/3 YARN splits the JobTracker’s responsibilities into Resource management – the global Resource Manager daemon Per application Application Master The resource manger and per-node slave Node Managers allow generic node management The resource manager has a pluggable scheduler Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/

28
YARN – 3/3 The Scheduler performs its scheduling function based on the resource requirements of the applications; it does so based on the abstract notion of a Resource Container which incorporates resource elements such as memory, cpu, disk, network The NodeManager is the per-machine slave, which is responsible for launching the applications’ containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager. The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress. From the system perspective, the ApplicationMaster itself runs as a normal container. Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/

29
Big Data – Execution Engine Amir Payberah https://www.sics.se/~amir/dic.htm

30
Big Data – Query/Scripting Languages Amir Payberah https://www.sics.se/~amir/dic.htm

31
Big Data – Stream Processing Amir Payberah https://www.sics.se/~amir/dic.htm

32
Big Data – Graph Processing Amir Payberah https://www.sics.se/~amir/dic.htm

33
Big Data – Machine Learning Amir Payberah https://www.sics.se/~amir/dic.htm

34
Hadoop Big Data Analytics Stack Amir Payberah https://www.sics.se/~amir/dic.htm

35
Spark Big Data Analytics Stack Amir Payberah https://www.sics.se/~amir/dic.htm

36
Hadoop Ecosystem Hortonworks http://hortonworks.com/industry/manufacturing/

37
Hadoop Ecosystem 2008 onwards – usage exploded Creation of many tools on top of Hadoop infrastructure

38
The Need For Filesystems Amir Payberah https://www.sics.se/~amir/dic.htm

39
Distributed Filesystems Amir Payberah https://www.sics.se/~amir/dic.htm

41
Hadoop Distributed File System (HDFS) A distributed file system designed to run on commodity hardware HDFS was originally built as infrastructure for the Apache Nutch web search engine project, with the aim to achieve fault tolerance, ability to run on low-cost hardware and handle large datasets It is now an Apache Hadoop subproject Share similarities with existing distributed file systems and supports traditional hierarchical file organization Reliable data replication and accessible via Web interface and Shell commands Benefits: Fault tolerant, high throughput, streaming data access, robustness and handling of large data sets HDFS is not a general purpose F/S
 A distributed file system designed to run on commodity hardware HDFS was originally built as infrastructure for the Apache Nutch web search engine project, with the aim to achieve fault tolerance, ability to run on low-cost hardware and handle large datasets It is now an Apache Hadoop subproject Share similarities with existing distributed file systems and supports traditional hierarchical file organization Reliable data replication and accessible via Web interface and Shell commands Benefits: Fault tolerant, high throughput, streaming data access, robustness and handling of large data sets HDFS is not a general purpose F/S")
42
Assumptions and Goals Hardware failures Detection of faults, quick and automatic recovery Streaming data access Designed for batch processing rather than interactive use by users Large data sets Applications that run on HDFS have large data sets, typically in gigabytes to terabytes in size Optimized for batch reads rather than random reads Simple coherency model Applications need a write-once, read-many times access model for files Computation migration Computation is moved closer to where data is located Portability Easily portable between heterogeneous hardware and software platforms

43
What HDFS is not good for Amir Payberah https://www.sics.se/~amir/dic.htm

44
HDFS Architecture The Hadoop Distributed File System (HDFS) Offers a way to store large files across multiple machines, rather than requiring a single machine to have disk capacity equal to/greater than the summed total size of the files HDFS is designed to be fault- tolerant Using data replication and distribution of data When a file is loaded into HDFS, it is replicated and broken up into "blocks" of data These blocks are stored across the cluster nodes designated for storage, a.k.a. DataNodes. http://www.revelytix.com/?q=content/hadoop-ecosystem

45
Files and Blocks – 1/3 Amir Payberah https://www.sics.se/~amir/dic.htm

46
Files and Blocks – 2/3 Amir Payberah https://www.sics.se/~amir/dic.htm

47
Files and Blocks – 3/3 Amir Payberah https://www.sics.se/~amir/dic.htm

48
HDFS Daemons HDFS cluster is manager by three types of processes Namenode Manages the filesystem, e.g., namespace, meta-data, and file blocks Metadata is stored in memory Datanode Stores and retrieves data blocks Reports to Namenode Runs on many machines Secondary Namenode Only for checkpointing. Not a backup for Namenode Amir Payberah https://www.sics.se/~amir/dic.htm

49
Hadoop Server Roles http://www.revelytix.com/?q=content/hadoop-ecosystem

50
NameNode – 1/3 The HDFS namespace is a hierarchy of files and directories These are represented in the NameNode using inodes Inodes record attributes permissions, modification and access times; namespace and disk space quotas. The file content is split into large blocks (typically 128 megabytes, but user selectable file-by-file), and each block of the file is independently replicated at multiple DataNodes (typically three, but user selectable file-by-file) The NameNode maintains the namespace tree and the mapping of blocks to DataNodes A Hadoop cluster can have thousands of DataNodes and tens of thousands of HDFS clients per cluster, as each DataNode may execute multiple application tasks concurrently http://www.revelytix.com/?q=content/hadoop-ecosystem
, and each block of the file is independently replicated at multiple DataNodes (typically three, but user selectable file-by-file) The NameNode maintains the namespace tree and the mapping of blocks to DataNodes A Hadoop cluster can have thousands of DataNodes and tens of thousands of HDFS clients per cluster, as each DataNode may execute multiple application tasks concurrently q=content/hadoop-ecosystem.")
51
NameNode – 2/3 The inodes and the list of blocks that define the metadata of the name system are called the image (FsImage above) NameNode keeps the entire namespace image in RAM Each client-initiated transaction is recorded in the journal, and the journal file is flushed and synced before the acknowledgment is sent to the client The NameNode is a multithreaded system and processes requests simultaneously from multiple clients. http://www.revelytix.com/?q=content/hadoop-ecosystem

52
NameNode – 3/3 HDFS requires A NameNode process to run on one node in the cluster All other nodes run the DataNode service to run on each "slave" node that will be processing data. When data is loaded into HDFS Data is replicated and split into blocks that are distributed across the DataNodes The NameNode is responsible for storage and management of metadata, so that when MapReduce or another execution framework calls for the data, the NameNode informs it where the needed data resides. http://www.revelytix.com/?q=content/hadoop-ecosystem

53
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

54
DataNode – 1/3 Each block replica on a DataNode is represented by two files in the local native filesystem. The first file contains the data itself and the second file records the block's metadata including checksums for the data and the generation stamp. At startup each DataNode connects to a NameNode and preforms a handshake. The handshake verifies that the DataNode is part of the NameNode and runs the same version of software A DataNode identifies block replicas in its possession to the NameNode by sending a block report. A block report contains the block ID, the generation stamp and the length for each block replica the server hosts The first block report is sent immediately after the DataNode registration Subsequent block reports are sent every hour and provide the NameNode with an up-to-date view of where block replicas are located on the cluster. http://www.aosabook.org/en/hdfs.html

55
DataNode – 2/3 During normal operation DataNodes send heartbeats to the NameNode to confirm that the DataNode is operating and the block replicas it hosts are available If the NameNode does not receive a heartbeat from a DataNode in ten minutes, it considers the DataNode to be out of service and the block replicas hosted by that DataNode to be unavailable The NameNode then schedules creation of new replicas of those blocks on other DataNodes. Heartbeats from a DataNode also carry information about total storage capacity, fraction of storage in use, and the number of data transfers currently in progress. These statistics are used for the NameNode's block allocation and load balancing decisions. http://www.aosabook.org/en/hdfs.html

56
DataNode – 3/3 The NameNode does not directly send requests to DataNodes. It uses replies to heartbeats to send instructions to the DataNodes The instructions include commands to replicate blocks to other nodes, remove local block replicas, re-register and send an immediate block report, and shut down the node These commands are important for maintaining the overall system integrity and therefore it is critical to keep heartbeats frequent even on big clusters. The NameNode can process thousands of heartbeats per second without affecting other NameNode operations. http://www.aosabook.org/en/hdfs.html

57
HDFS Client – 1/3 User applications access the filesystem using the HDFS client, a library that exports the HDFS filesystem interface User is oblivious to backend implementation details eg # of replicas and which servers have appropriate blocks http://www.aosabook.org/en/hdfs.html

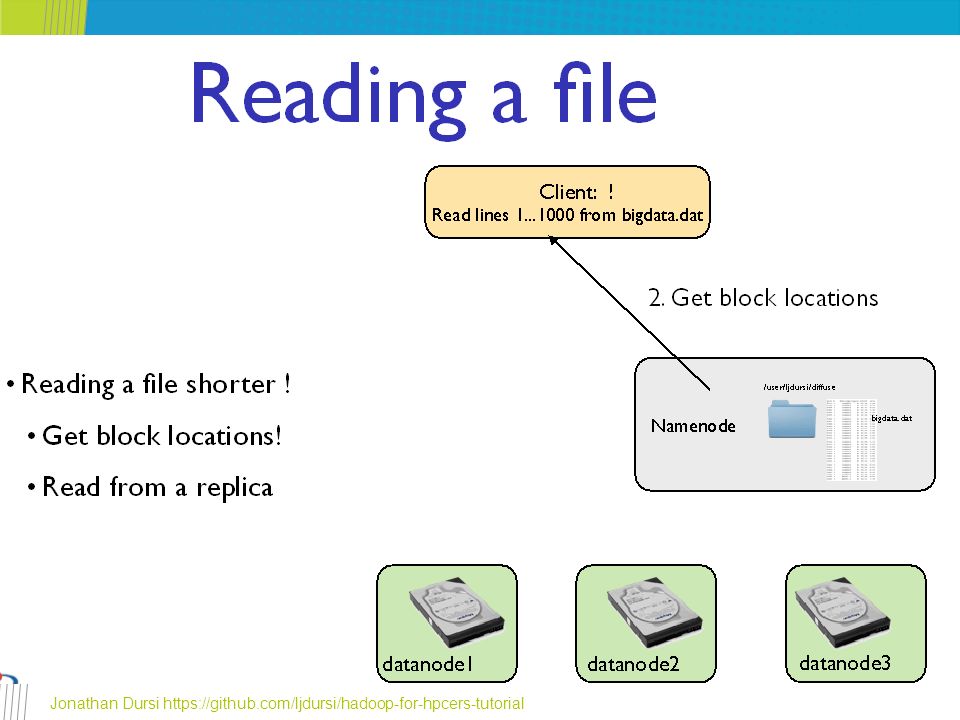
58
HDFS Client – 2/3 When an application reads a file, the HDFS client first asks the NameNode for the list of DataNodes that host replicas of the blocks of the file The list is sorted by the network topology distance from the client The client contacts a DataNode directly and requests the transfer of the desired block. http://www.aosabook.org/en/hdfs.html
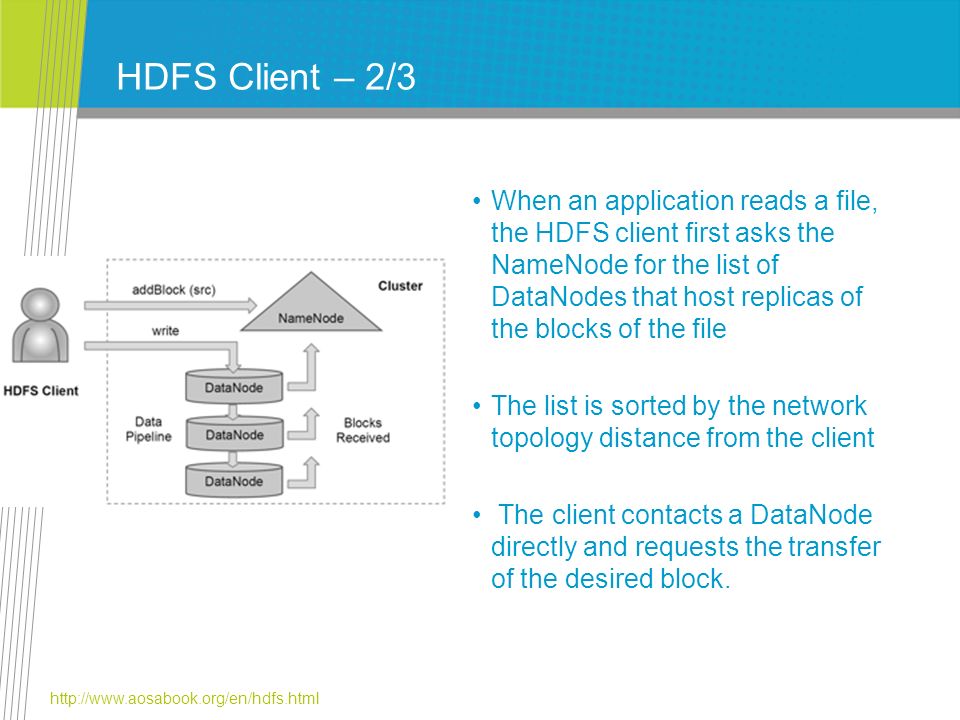
59
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

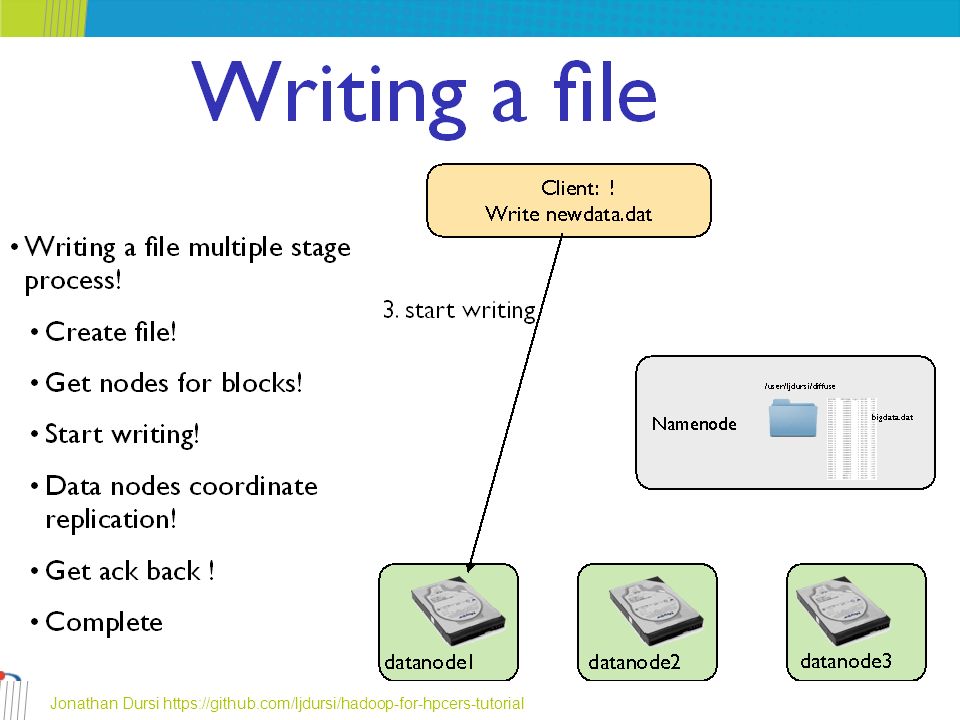
62
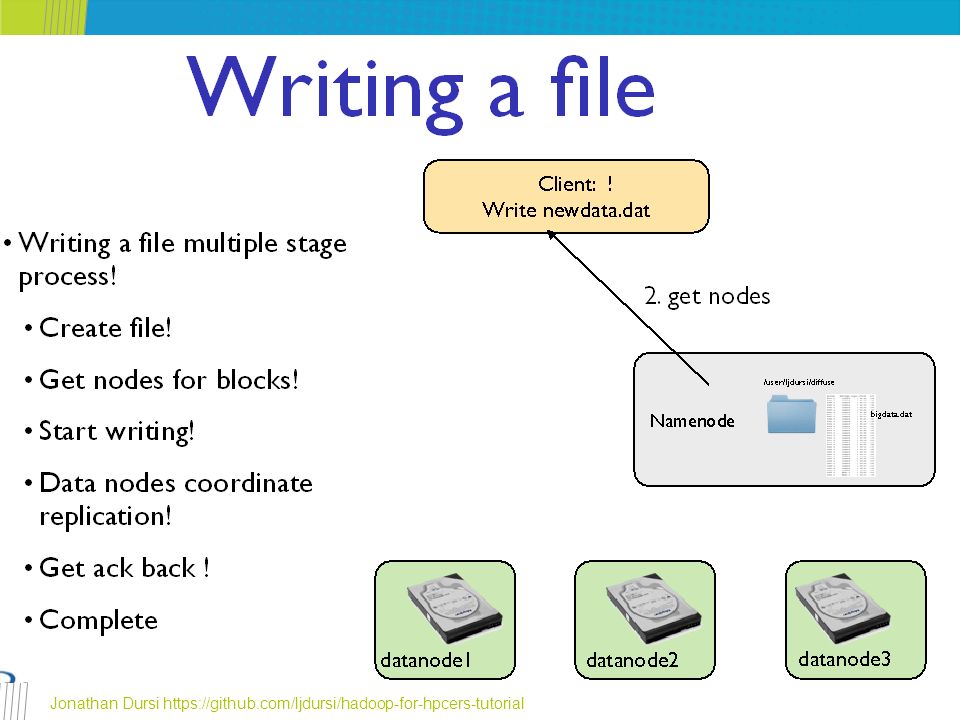
HDFS Client – 3/3 When a client writes, it first asks the NameNode to choose DataNodes to host replicas of the first block of the file The client organizes a pipeline from node-to-node and sends the data When the first block is filled, the client requests new DataNodes to be chosen to host replicas of the next block A new pipeline is organized, and the client sends the further bytes of the file Choice of DataNodes for each block is likely to be different http://www.aosabook.org/en/hdfs.html

63
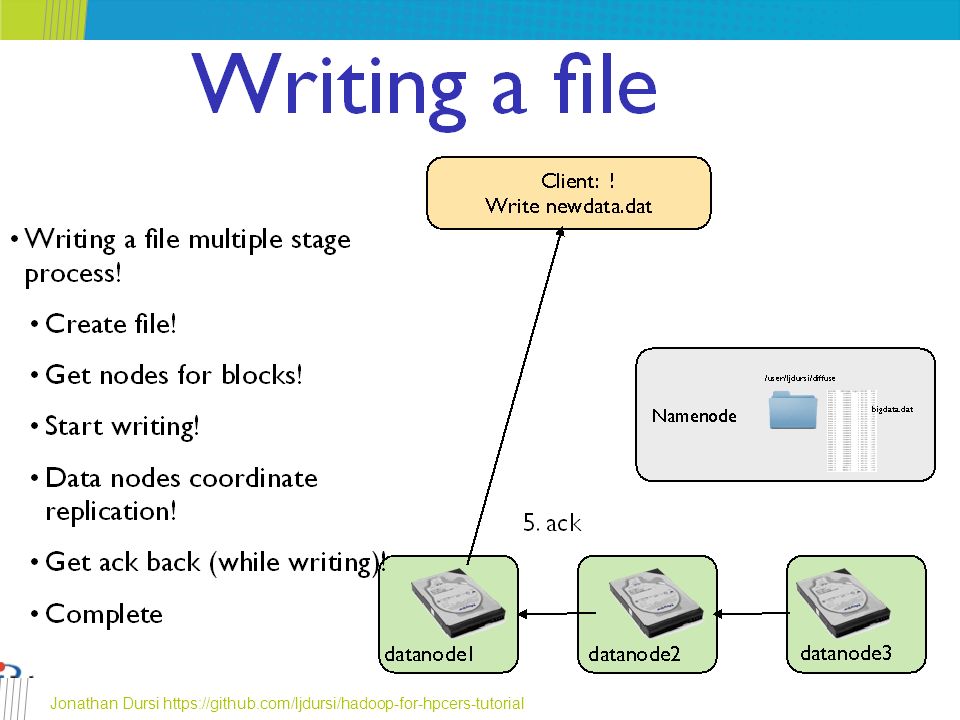
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

69
HDFS Federation Amir Payberah https://www.sics.se/~amir/dic.htm

70
File I/O and Leases in HDFS An application Adds data to HDFS by creating a new file and writing data to it On closing the file, new data can only be appended HDFS implements a single-writer, multiple-reader model Leases are granted by the NameNode to HDFS clients Writer clients need to periodically renew the lease via a heartbeat to the NameNode On file close, the lease is revoked There are soft and hard limits for leases (the hard limit being an hour) A write lease does not prevent multiple readers from reading the file
 A write lease does not prevent multiple readers from reading the file")
71
Data Pipelining for Writing Blocks – 1/2 An HDFS file consists of blocks When there is a need for a new block, the NameNode allocates a block with a unique block ID and determines a list of DataNodes to host replicas of the block The DataNodes form a pipeline, the order of which minimizes the total network distance from the client to the last DataNode http://www.aosabook.org/en/hdfs.html

72
Data Pipelining for Writing Blocks – 2/2 Bytes are pushed to the pipeline as a sequence of packets. The bytes that an application writes first buffer at the client side After a packet buffer is filled (typically 64 KB), the data are pushed to the pipeline The next packet can be pushed to the pipeline before receiving the acknowledgment for the previous packets The number of outstanding packets is limited by the outstanding packets window size of the client. http://www.aosabook.org/en/hdfs.html
, the data are pushed to the pipeline The next packet can be pushed to the pipeline before receiving the acknowledgment for the previous packets The number of outstanding packets is limited by the outstanding packets window size of the client.")
73
HDFS Interfaces There are many interfaces to interact with HDFS Simplest way of interacting with HDFS in command-line Two properties are set in HDFS configuration Default Hadoop filesystem fs.default.name: hdfs://localhost/ Used to determine the host (localhost) and port (8020) for the HDFS NameNode Replication factor dfs.replication Default is 3, disable replication by setting it to 1 (single datanode) Other HDFS interfaces HTTP: a read only interface for retrieving directory listings and data over HTTP FTP: permits the use of the FTP protocol to interact with HDFS
 and port (8020) for the HDFS NameNode Replication factor dfs.replication Default is 3, disable replication by setting it to 1 (single datanode) Other HDFS interfaces HTTP: a read only interface for retrieving directory listings and data over HTTP FTP: permits the use of the FTP protocol to interact with HDFS")
74
Replication in HDFS Replica placement Critical to improve data reliability, availability and network bandwidth utilization Rack-aware policy as rack failure is far less than node failure With the default replication factor (3), one replica is put on one node in the local rack, another on a node in a different (remote) rack, and the last on a different node in the same remote rack One third of replication are on one node; two-third of replicas are on one rack, and the other third are evenly distributed across racks Benefits is to reduce inter-rack write traffic Replica selection A read request is satisfied from a replica that is nearby to the application Minimizes global bandwidth consumption and read latency If HDFS spans multiple data center, replica in the local data center is preferred over any remote replica
, one replica is put on one node in the local rack, another on a node in a different (remote) rack, and the last on a different node in the same remote rack One third of replication are on one node; two-third of replicas are on one rack, and the other third are evenly distributed across racks Benefits is to reduce inter-rack write traffic Replica selection A read request is satisfied from a replica that is nearby to the application Minimizes global bandwidth consumption and read latency If HDFS spans multiple data center, replica in the local data center is preferred over any remote replica")
75
Communication Protocol All HDFS communication protocols are layered on top of the TCP/IP protocol A client establishes a connection to a configurable TCP port on the NameNode machine and uses ClientProtocol DataNodes talk to the NameNode using DataNode protocol A Remote Procedure Call (RPC) abstraction wraps both the ClientProtocol and DataNode protocol NameNode never initiates a RPC, instead it only responds to RPC requests issued by DataNodes or clients
 abstraction wraps both the ClientProtocol and DataNode protocol NameNode never initiates a RPC, instead it only responds to RPC requests issued by DataNodes or clients")
76
Robustness Primary objective of HDFS is to store data reliably even during failures Three common types of failures: NameNode, DataNode and network partitions Data disk failure Heartbeat messages to track the health of DataNodes NameNodes performs necessary re-replication on DataNode unavailability, replica corruption or disk fault Cluster rebalancing Automatically move data between DataNodes, if the free space on a DataNode falls below a threshold or during sudden high demand Data integrity Checksum checking on HDFS files, during file creation and retrieval Metadata disk failure Manual intervention – no auto recovery, restart or failover

77
Ceph – An Alternative to HDFS in One Slide https://www.terena.org/acti vities/tf- storage/ws16/slides/14021 0-low_cost_storage_ceph- openstack_swift.pdf

78
MAP-REDUCE

79
What is it? Amir Payberah https://www.sics.se/~amir/dic.htm

80
MapReduce Basics A programming model and its associated implementation for parallel processing of large data sets It was developed within Google as a mechanism for processing large amounts of raw data, e.g. crawled documents or web request logs. Capable of efficiently distribute processing of TB’s of data on 1000’s of processing nodes This distribution implies parallel computing since the same computations are performed on each CPU, but with a different dataset (or different segment of a large dataset) Implementation’s run-time system library takes care of parallelism, fault tolerance, data distribution, load balancing etc Complementary to RDBMS, but differs in many ways (data size, access, update, structure, integrity and scale) Features: fault tolerance, locality, task granularity, backup tasks, skipping bad records and so on
 Implementation’s run-time system library takes care of parallelism, fault tolerance, data distribution, load balancing etc Complementary to RDBMS, but differs in many ways (data size, access, update, structure, integrity and scale) Features: fault tolerance, locality, task granularity, backup tasks, skipping bad records and so on.")
81
MapReduce Simple Dataflow Amir Payberah https://www.sics.se/~amir/dic.htm

82
MapReduce – Functional Programming Concepts MapReduce programs are designed to compute large volumes of data in a parallel fashion This model would not scale to large clusters (hundreds or thousands of nodes) if the components were allowed to share data arbitrarily The communication overhead required to keep the data on the nodes synchronized at all times would prevent the system from performing reliably or efficiently at large scale Instead, all data elements in MapReduce are immutable, meaning that they cannot be updated If in a mapping task you change an input (key, value) pair, it does not get reflected back in the input files; communication occurs only by generating new output (key, value) pairs which are then forwarded by the Hadoop system into the next phase of execution https://developer.yahoo.com/hadoop/tutorial
 if the components were allowed to share data arbitrarily The communication overhead required to keep the data on the nodes synchronized at all times would prevent the system from performing reliably or efficiently at large scale Instead, all data elements in MapReduce are immutable, meaning that they cannot be updated If in a mapping task you change an input (key, value) pair, it does not get reflected back in the input files; communication occurs only by generating new output (key, value) pairs which are then forwarded by the Hadoop system into the next phase of execution")
83
MapReduce – List Processing Conceptually, MapReduce programs transform lists of input data elements into lists of output data elements A MapReduce program will do this twice, using two different list processing idioms: map, and reduce These terms are taken from several list processing languages such as LISP, Scheme, or ML https://developer.yahoo.com/hadoop/tutorial

84
MapReduce – Mapping Lists The first phase of a MapReduce program is called mapping A list of data elements are provided, one at a time, to a function called the Mapper, which transforms each element individually to an output data element. Say there is a toUpper(str) function, which returns an uppercase version of the input string. The Map would then turn input strings into a list of uppercase strings. Note: the input has not been modifed. A new string has been returned https://developer.yahoo.com/hadoop/tutorial
 function, which returns an uppercase version of the input string. The Map would then turn input strings into a list of uppercase strings. Note: the input has not been modifed. A new string has been returned")
85
MapReduce – Reducing Lists Reducing lets you aggregate values together A reducer function receives an iterator of input values from an input list. It then combines these values together, returning a single output value. Reducing is often used to produce "summary" data, turning a large volume of data into a smaller summary of itself. For example, "+" can be used as a reducing function, to return the sum of a list of input values. https://developer.yahoo.com/hadoop/tutorial

86
Putting Map and Reduce together A MapReduce program has two components: one that implements the mapper, and another that implements the reducer Keys and values: In MapReduce, no value stands on its own. Every value has a key associated with it. Keys identify related values. Eg. the list below is for flight departures and the number of passengers that failed to board The mapping and reducing functions receive not just values, but (key, value) pairs. The output of each of these functions is the same: both a key and a value must be emitted to the next list in the data flow. EK123 65, 12:00pm BA789 50, 12:02pm EK123 40, 12:05pm QF456 25, 12:15pm... https://developer.yahoo.com/hadoop/tutorial
 pairs. The output of each of these functions is the same: both a key and a value must be emitted to the next list in the data flow. EK123 65, 12:00pm BA789 50, 12:02pm EK123 40, 12:05pm QF456 25, 12:15pm...")
87
MapReduce - Keys In MapReduce, an arbitrary number of values can be output from each phase; a mapper may map one input into zero, one, or one hundred outputs. A reducer may compute over an input list and emit one or a dozen different outputs Keys divide the reduce space: A reducing function turns a large list of values into one (or a few) output values In MapReduce, all of the output values are not usually reduced together All of the values with the same key are presented to a single reducer together This is performed independently of any reduce operations occurring on other lists of values, with different keys attached Different colors represent different keys. All values with the same key are presented to a single reduce task. https://developer.yahoo.com/hadoop/tutorial
 output values In MapReduce, all of the output values are not usually reduced together All of the values with the same key are presented to a single reducer together This is performed independently of any reduce operations occurring on other lists of values, with different keys attached Different colors represent different keys. All values with the same key are presented to a single reduce task.")
88
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

89
High-Level Structure of a MR Program – 1/2 mapper (filename, file-contents): for each word in file-contents: emit (word, 1) reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) https://developer.yahoo.com/hadoop/tutorial
: for each word in file-contents: emit (word, 1) reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum)")
90
High-Level Structure of a MR Program – 2/2 Several instances of the mapper function are created on the different machines in a Hadoop cluster Each instance receives a different input file (it is assumed that there are many such files) The mappers output (word, 1) pairs which are then forwarded to the reducers Several instances of the reducer method are also instantiated on the different machines Each reducer is responsible for processing the list of values associated with a different word The list of values will be a list of 1's; the reducer sums up those ones into a final count associated with a single word. The reducer then emits the final (word, count) output which is written to an output file. mapper (filename, file-contents): for each word in file-contents: emit (word, 1) reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) https://developer.yahoo.com/hadoop/tutorial
 output which is written to an output file. mapper (filename, file-contents): for each word in file-contents: emit (word, 1) reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum)")
91
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

94
MapReduce Data Flow – 1/4 https://developer.yahoo.com/hadoop/tutorial

95
MapReduce Data Flow – 2/4 MapReduce inputs typically come from input files loaded onto the Hadoop cluster’s HDFS F/S These files are evenly distributed across all nodes Running a MapReduce program involves running mapping tasks on many or all of the nodes in the Hadoop cluster Each of these mapping tasks is equivalent: no mappers have particular "identities" associated with them Thus, any mapper can process any input file. Each mapper loads the set of files local to that machine and processes them https://developer.yahoo.com/hadoop/tutorial

96
MapReduce Data Flow – 3/4 When the mapping phase has completed, the intermediate (key, value) pairs must be exchanged between machines All values with the same key are sent to a single reducer https://developer.yahoo.com/hadoop/tutorial
 pairs must be exchanged between machines All values with the same key are sent to a single reducer")
97
MapReduce Data Flow – 4/4 The reduce tasks are spread across the same nodes in the cluster as the mappers. This is the only communication step in MapReduce The user never explicitly marshals information from one machine to another. All data transfer is handled by the Hadoop MapReduce platform runtime, guided implicitly by the different keys associated with values. This is a fundamental element of Hadoop MapReduce's reliability. If nodes in the cluster fail, tasks must be able to be restarted. If they have been performing side-effects, e.g., communicating with the outside world, then the shared state must be restored in a restarted task. By eliminating communication and side-effects, restarts can be handled more gracefully. https://developer.yahoo.com/hadoop/tutorial

98
In Depth View of Map-Reduce

99
https://developer.yahoo.com/hadoop/tutorial
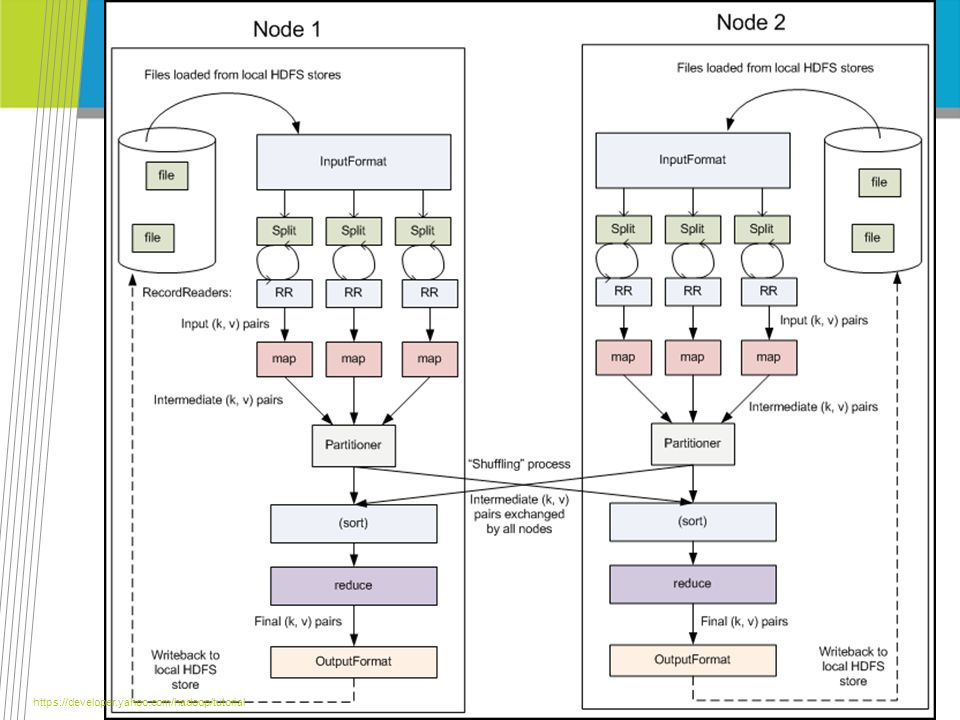
100
InputFormat – 1/2 Input files reside on HDFS and can be of an arbitrary format Deciding how to split up and read these files is decided by the InputFormat class. It: Selects the files or other objects that should be used for input Defines the InputSplits that break a file into tasks Provides a factory for RecordReader objects that read the file https://developer.yahoo.com/hadoop/tutorial

101
InputFormat – 2/2 An InputSplit is the unit of work which comprises a single map task By default this is a 64MB chunk. As various blocks make up a file, it is possible to run parallel Map tasks on these chunks https://developer.yahoo.com/hadoop/tutorial

102
RecordReader and Mapper An InputSplit defined a unit of work The RecordReader class defines how to load the data and convert into (key, value) pairs that the Map phase can use The Mapper function does the Map, emitting (key, value) pairs for use by the Reduce phase https://developer.yahoo.com/hadoop/tutorial
 pairs that the Map phase can use The Mapper function does the Map, emitting (key, value) pairs for use by the Reduce phase")
103
Partition and Shuffle On completion of the first batch of Map tasks, nodes begin exchanging outputs to Reducers – this is called the Shuffle phase Each reducer is given a different subset of the key space (called Partitions) by the Partitioner class These (key,value) pairs are then inputs for the Reduce phase https://developer.yahoo.com/hadoop/tutorial
 by the Partitioner class These (key,value) pairs are then inputs for the Reduce phase")
104
Sort, Reduce and Output Intermediate (key, value) pairs from the Shuffle process are then sorted as input to the Reducer The Reducers iterate over all their values and produce an output The outputs are then written back to HDFS https://developer.yahoo.com/hadoop/tutorial
 pairs from the Shuffle process are then sorted as input to the Reducer The Reducers iterate over all their values and produce an output The outputs are then written back to HDFS")
105
Handling Failure Worker failure To detect failure, the master pings every worker periodically If no response is received from a worker in a certain amount of time, the master marks the worker as failed Any map tasks completed by the worker are reset back to their initial idle state, and therefore become eligible for scheduling on other workers Completed map tasks are re-executed as their output on is stored on the local disk(s) of the failed machine and is therefore inaccessible Completed reduce tasks do not need to be re-executed since their output is stored in a global file system Master failure Periodic checkpoints are written to handle master failure If the master task dies, a new copy can be started from the last checkpoint state
 of the failed machine and is therefore inaccessible Completed reduce tasks do not need to be re-executed since their output is stored in a global file system Master failure Periodic checkpoints are written to handle master failure If the master task dies, a new copy can be started from the last checkpoint state")
106
Data Locality Network bandwidth is a valuable scarce resource and it should be consumed wisely The distributed file system replicates data across different nodes The Master takes these locations into account when scheduling Map tasks, trying to place them with the data Otherwise, Map tasks are scheduled to reside “near” a replica of the data (e.g., on a worker machine that is on the same network switch) When running large MapReduce operations, most input data is read locally and consume no network bandwidth Data locality worked well with a Hadoop-specific distributed file system Integration of a Cloud-based file system incurs extra cost and loss data locality
 When running large MapReduce operations, most input data is read locally and consume no network bandwidth Data locality worked well with a Hadoop-specific distributed file system Integration of a Cloud-based file system incurs extra cost and loss data locality")
107
Task Granularity Finely granular tasks: many more map tasks than machines Better dynamic load balancing Minimizes time for fault recovery Can pipeline the shuffling/grouping while maps are still running Typically 200k Map tasks, 5k Reduce tasks for 2k hosts For M map tasks and R reduce tasks there are O(M+R) scheduling decisions and O(M*R) states
 scheduling decisions and O(M*R) states")
108
Load Balancing Built-in dynamic load balancing One other problem that can slow calculations is the existence of stragglers; machines suffering from either hardware defects, contention for resources with other applications etc. When an overall MapReduce operation passes some point deemed to be “nearly complete,” the Master schedules backup tasks for all of the currently in-progress tasks When a particular task is completed, whether it be “original” or back-up, its value is used This strategy costs little more overall, but can result in big performance gains

109
Refinements Partitioning function MapReduce users specify the number of reduce tasks/output files (R) Data gets partitioned across these tasks using a partitioning function on the intermediate key Default is “hash(key) mod R”, resulting in well balanced partitions Special partitioning function can also be used, such as “hash(Hostname(urlkey))” to combine all URLs (output keys) from the same host to the same output file Ordering guarantees Within a given partition, the intermediate key/value pairs are processed in increasing key order This ordering guarantee makes it easy to generate a sorted output file per partition Allows users to have sorted output and efficient access lookups by key
 Data gets partitioned across these tasks using a partitioning function on the intermediate key Default is hash(key) mod R , resulting in well balanced partitions Special partitioning function can also be used, such as hash(Hostname(urlkey)) to combine all URLs (output keys) from the same host to the same output file Ordering guarantees Within a given partition, the intermediate key/value pairs are processed in increasing key order This ordering guarantee makes it easy to generate a sorted output file per partition Allows users to have sorted output and efficient access lookups by key")
110
Refinements (Cont’d) Combiner function There can be significant repetition in the intermediate keys produced by each map task and the reduce task is associative While one reduce task can perform the aggregation, an on-processor combiner function can be used to perform partial merging of Map output locally before sending over the network The combiner function is executed on each machine that performs a map task The program logic for the combiner function and reduce tasks are potentially same, except how the output is handled, i.e. writing output in an intermediate file or in the final output file Input/Output types Multiple input/output format supported User can also add support to new input/output type by providing an implementation to the reader/writer interface

111
Refinements (Cont’d) Skipping bad records MapReduce provides a mode for skipping records that are diagnosed to cause Map() crashes Each worker process installs a signal handler that catches segment violations and bus errors, tracked by master When the master notices more than one failure on a particular record, it indicates that the record should be skipped during re-execution Local execution/debugging Not straightforward due to the distributed computation of MapReduce Alternative implementation of the MapReduce library that sequentially on one node (local machine) Users can use any debugging or testing tools they find useful
 Skipping bad records MapReduce provides a mode for skipping records that are diagnosed to cause Map() crashes Each worker process installs a signal handler that catches segment violations and bus errors, tracked by master When the master notices more than one failure on a particular record, it indicates that the record should be skipped during re-execution Local execution/debugging Not straightforward due to the distributed computation of MapReduce Alternative implementation of the MapReduce library that sequentially on one node (local machine) Users can use any debugging or testing tools they find useful")
112
Refinements (Cont’d) Status information Master contains internal http server to produce status pages with information on how many tasks have been completed, how many are in progress, bytes of input, bytes of intermediate data, bytes of output, and processing rates. The status page contains links to the standard error and standard output files generated by each task A user can monitor progress, predict computation time and accelerate it by adding more hosts Counters Counters A facility to count occurrences of various events To use this facility, user code creates a named counter object and then increments the counter appropriately in Map and/or Reduce function

113
MapReduce Applications Applications Text tokenization (alert system), indexing, and search Data mining, statistical modeling, and machine learning Healthcare – parse, clean and reconcile extremely large amount of data Biosciences – drug discovery, meta-genomics, bioassay activities Cost-effective mash-ups – retrieving and analyzing biomedical knowledge Computational biology – parallelize bioinformatics algorithms for SNP discovery, genotyping and personal genomics, e.g. CloudBurst Emergency response – real-time monitoring/forecasting for operational decision support and so on (Check: http://wiki.apache.org/hadoop/PoweredBy)http://wiki.apache.org/hadoop/PoweredBy MapReduce inapplicability Database management – does not provide traditional DBMS features Database implementation – lack of schema, low data integrity Normalization poses problems for MapReduce, due to non-local reading Applications cannot have read and write many times feature

114
How Hadoop Runs a MapReduce job Client submits MapReduce job JobTracker coordinates job run TaskTracker runs split tasks HDFS is used for file storage Hadoop: The Definitive Guide, O’Reilly

115
Streaming and Pipes Hadoop Streaming, API to MapReduce to write non-Java map and reduce function Hadoop and the user program communicates using standard I/O streams Hadoop Pipes is the C++ interface to MapReduce Uses socket as channel to communicate with the process running the C++ Map or Reduce function Hadoop: The Definitive Guide, O’Reilly

116
Progress and Status Updates Operations constituting progress Reading an input record Writing an output record Setting status description Incrementing a counter Calling progress () method Hadoop: The Definitive Guide, O’Reilly
 method Hadoop: The Definitive Guide, O’Reilly")
117
Hadoop Failures Task failure Map or reduce task throws a runtime exception For streaming tasks, streaming processes exiting with a non-zero exit code are considered as failed Task call also be killed and re-scheduled Tasktracker failure Crash or slow execution can cause infrequent (or stop) sending heartbeats to the job tracker A tasktracker can also be blacklisted by the jobtracker if it fails a significant number of tasks, higher than average task failure rate Jobtracker failure Single point of failure - no mechanism to deal with it One solution is to run multiple jobtracker or have backup jobtracker
 sending heartbeats to the job tracker A tasktracker can also be blacklisted by the jobtracker if it fails a significant number of tasks, higher than average task failure rate Jobtracker failure Single point of failure - no mechanism to deal with it One solution is to run multiple jobtracker or have backup jobtracker")
118
Checkpointing in Hadoop Hadoop: The Definitive Guide, O’Reilly

119
Job Scheduling in Hadoop Started with FIFO scheduling and now comes with a choice of schedulers The fair scheduler Aims to give every user a fair share of the cluster capacity over time Jobs are placed in pools and by default each user gets their own pool Support preemption – capacity provisioning of over-capacity to under- capacity pool The capacity scheduler Slightly different approach to multi-user scheduling A cluster is made up of a number of queues, which may be hierarchical, and each queue has an allocated capacity Within each queue jobs are scheduled using FIFO scheduling, with priorities

120
MapReduce and HDFS Amir Payberah https://www.sics.se/~amir/dic.htm

121
Fault Tolerance Amir Payberah https://www.sics.se/~amir/dic.htm

122
EXTRA MATERIAL

123
CEPH – A HDFS replacement

124
What is Ceph? Ceph is a distributed, highly available unified object, block and file storage system with no SPOF running on commodity hardware

125
Ceph Architecture – Host Level At the host level… We have Object Storage Devices (OSDs) and Monitors Monitors keep track of the components of the Ceph cluster (i.e. where the OSDs are) The device, host, rack, row, and room are stored by the Monitors and used to compute a failure domain OSDs store the Ceph data objects A host can run multiple OSDs, but it needs to be appropriately provisioned http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
 The device, host, rack, row, and room are stored by the Monitors and used to compute a failure domain OSDs store the Ceph data objects A host can run multiple OSDs, but it needs to be appropriately provisioned")
126
Ceph Architecture – Block Level At the block device level... Object Storage Device (OSD) can be an entire drive, a partition, or a folder OSDs must be formatted in ext4, XFS, or btrfs (experimental). https://hkg15.pathable.com/static/attachments/112267/1423597913.pdf?1423597913
 can be an entire drive, a partition, or a folder OSDs must be formatted in ext4, XFS, or btrfs (experimental)")
127
Ceph Architecture – Data Organization Level At the data organization level… Data are partitioned into pools Pools contain a number of Placement Groups (PGs) Ceph data objects map to PGs (via a modulo of hash of name) PGs then map to multiple OSDs. https://hkg15.pathable.com/static/attachments/112267/1423597913.pdf?1423597913
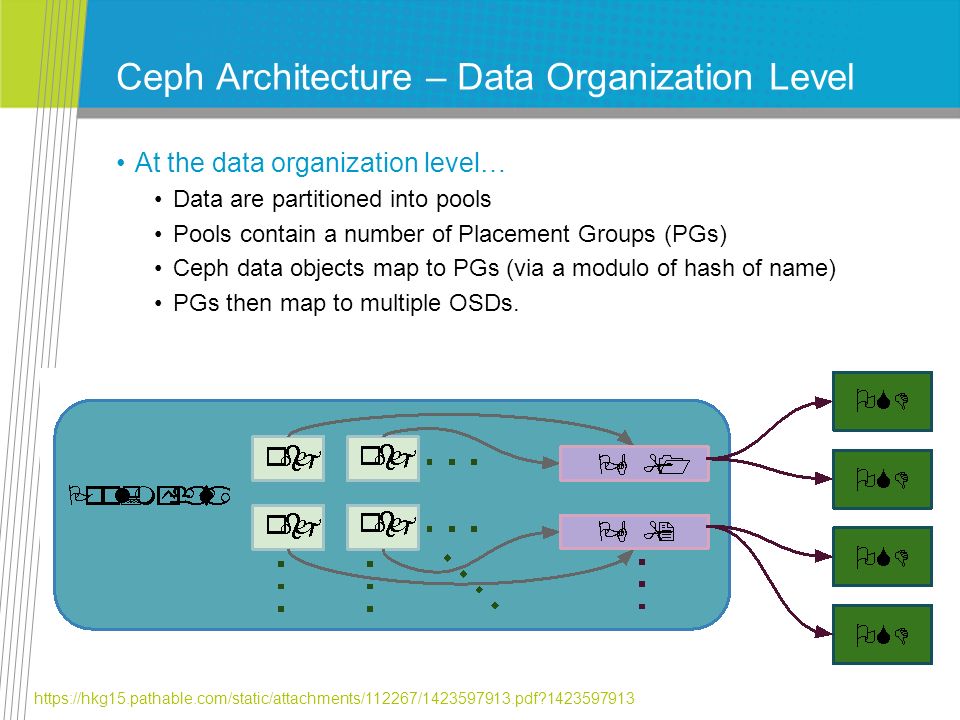
128
Ceph Placement Groups Ceph shards a pool into placement groups distributed evenly and pseudo-randomly across the cluster The CRUSH algorithm assigns each object to a placement group, and assigns each placement group to a set of OSDs—creating a layer of indirection between the Ceph client and the OSDs storing the copies of an object The CRUSH algorithm dynamically assigns each object to a placement group and then assigns each placement group to a set of Ceph OSDs This layer of indirection allows the Ceph storage cluster to re-balance dynamically when new Ceph OSD come online or when Ceph OSDs fail RedHat Ceph Architecture v1.2.3

129
Ceph Architecture – Overall View https://www.terena.org/acti vities/tf- storage/ws16/slides/14021 0-low_cost_storage_ceph- openstack_swift.pdf

130
Ceph Architecture – RADOS An Application interacts with a RADOS cluster RADOS (Reliable Autonomic Distributed Object Store) is a distributed object service that manages the distribution, replication, and migration of objects On top of that reliable storage abstraction Ceph builds a range of services, including a block storage abstraction (RBD, or Rados Block Device) and a cache-coherent distributed file system (CephFS). http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
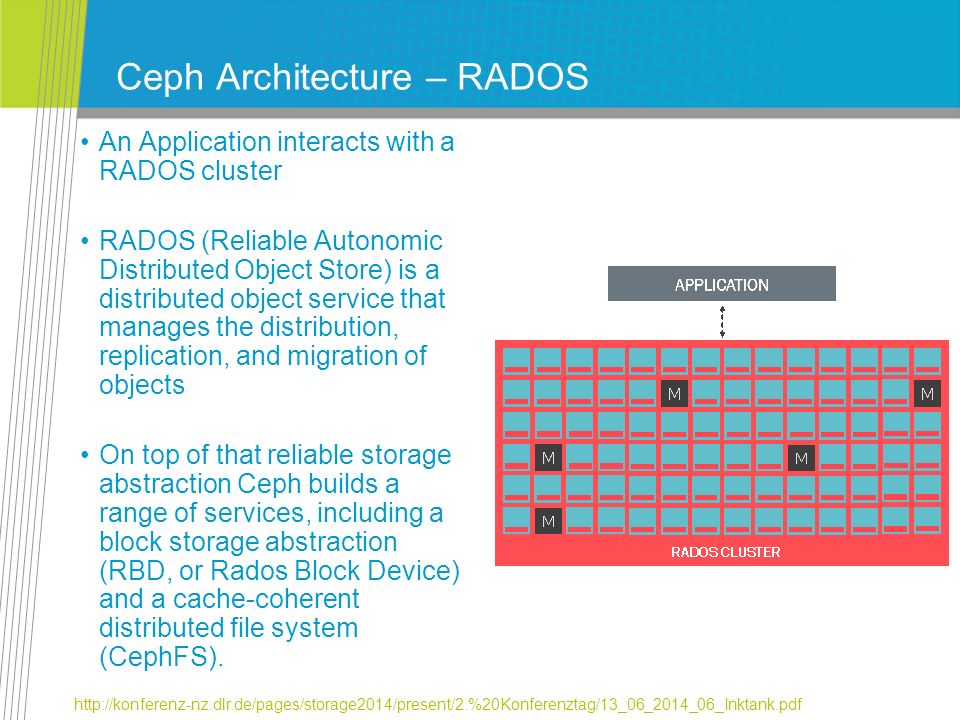
131
Ceph Architecture – RADOS Components http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf

132
Ceph Architecture – Where Do Objects Live? http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
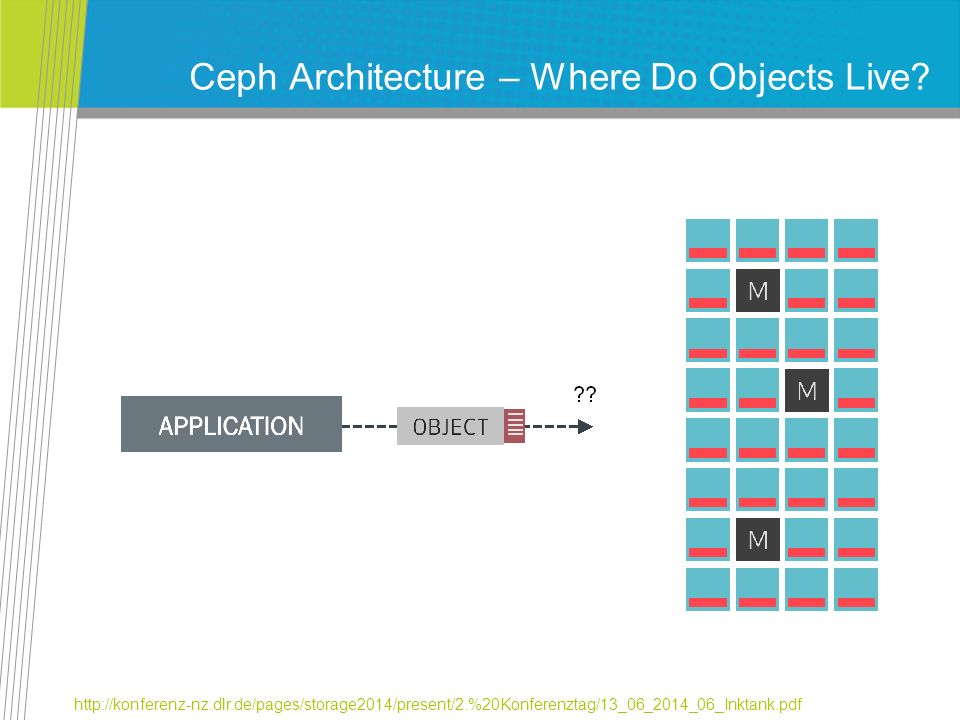
133
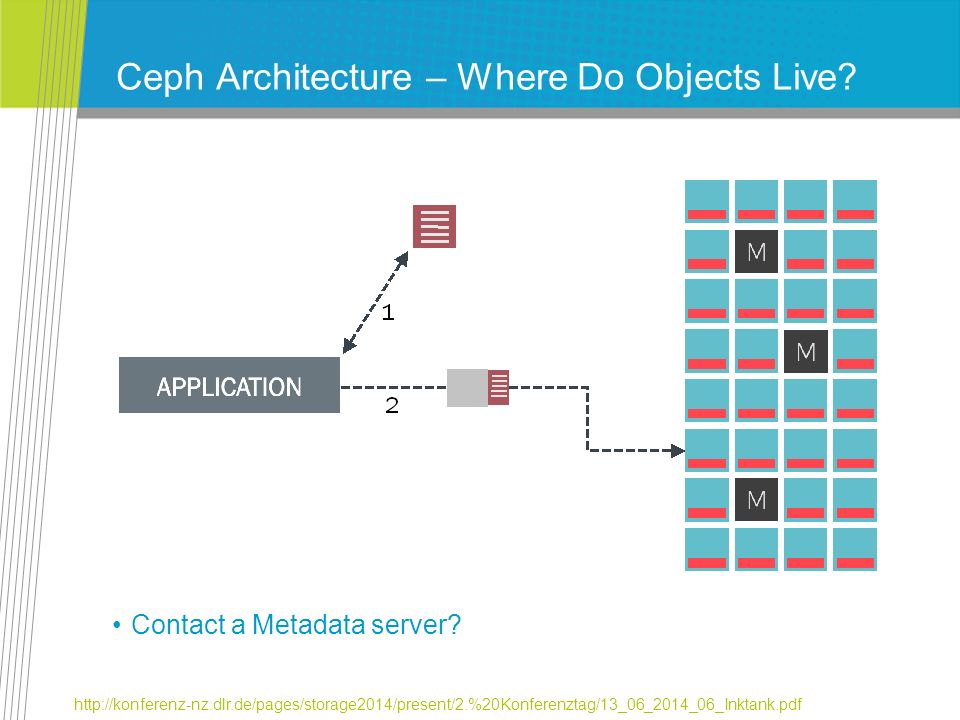
Ceph Architecture – Where Do Objects Live? Contact a Metadata server? http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
134
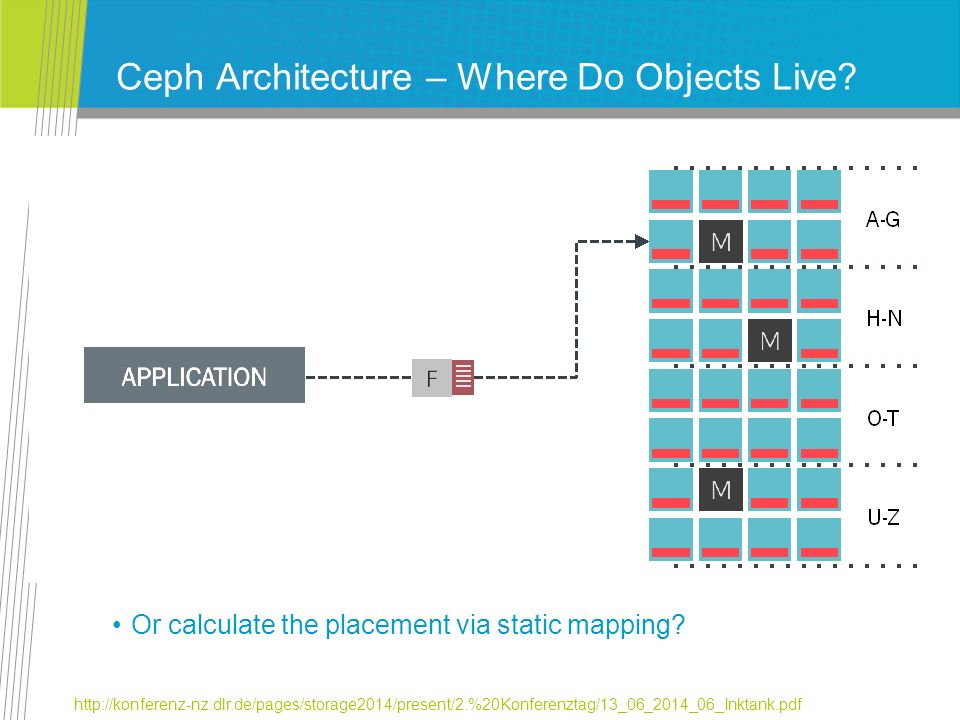
Ceph Architecture – Where Do Objects Live? Or calculate the placement via static mapping? http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
135
Ceph Architecture – CRUSH Maps http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf

136
Ceph Architecture – CRUSH Maps Data objects are distributed across Object Storage Devices (OSD), which refers to either physical or logical storage units, using CRUSH (Controlled Replication Under Scalable Hashing) CRUSH is a deterministic hashing function that allows administrators to define flexible placement policies over a hierarchical cluster structure (e.g., disks, hosts, racks, rows, datacenters) The location of objects can be calculated based on the object identifier and cluster layout (similar to consistent hashing), thus there is no need for a metadata index or server for the RADOS object store http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
, which refers to either physical or logical storage units, using CRUSH (Controlled Replication Under Scalable Hashing) CRUSH is a deterministic hashing function that allows administrators to define flexible placement policies over a hierarchical cluster structure (e.g., disks, hosts, racks, rows, datacenters) The location of objects can be calculated based on the object identifier and cluster layout (similar to consistent hashing), thus there is no need for a metadata index or server for the RADOS object store")
137
Ceph Architecture – CRUSH – 1/2 http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf

138
Ceph Architecture – CRUSH – 2/2 http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf

139
Ceph Architecture – librados http://konferenz- nz.dlr.de/pages/stora ge2014/present/2.% 20Konferenztag/13_ 06_2014_06_Inktank.pdf

140
Ceph Architecture – RADOS Gateway http://konferenz- nz.dlr.de/pages/stora ge2014/present/2.% 20Konferenztag/13_ 06_2014_06_Inktank.pdf

141
Ceph Architecture – RADOS Block Device (RBD) – 1/3 http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
 – 1/3")
142
Ceph Architecture – RADOS Block Device (RBD) – 2/3 Virtual Machine storage using RDB Live Migration using RBD http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
 – 2/3 Virtual Machine storage using RDB Live Migration using RBD")
143
Ceph Architecture – RADOS Block Device (RBD) – 3/3 Direct host access from Linux http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf
 – 3/3 Direct host access from Linux")
144
Ceph Architecture – CephFS – POSIX F/S http://konferenz-nz.dlr.de/pages/storage2014/present/2.%20Konferenztag/13_06_2014_06_Inktank.pdf

145
Ceph – Read/Write Flows https://software.intel.co m/en- us/blogs/2015/04/06/ce ph-erasure-coding- introduction

146
Ceph Replicated I/O RedHat Ceph Architecture v1.2.3

147
Ceph – Erasure Coding – 1/5 Erasure Code is a theory started at 1960s. The most famous algorithm is the Reed-Solomon. Many variations came out, like the Fountain Codes, Pyramid Codes and Local Repairable Codes. Erasure Codes usually defines the number of total disks (N) and the number of data disks (K), and it can tolerate N – K failures with overhead of N/K E,g, a typical Reed Solomon scheme: (8, 5), where 8 is the total disks, 5 is the data disks. In this case, the data in disks would be like: RS (8, 5) can tolerate 3 arbitrary failures. If there’s some data chunks missing, then one could use the rest available data to restore the original content. https://software.intel.com/en-us/blogs/2015/04/06/ceph-erasure-coding-introduction
 and the number of data disks (K), and it can tolerate N – K failures with overhead of N/K E,g, a typical Reed Solomon scheme: (8, 5), where 8 is the total disks, 5 is the data disks. In this case, the data in disks would be like: RS (8, 5) can tolerate 3 arbitrary failures. If there’s some data chunks missing, then one could use the rest available data to restore the original content.")
148
Ceph – Erasure Coding – 2/5 Like replicated pools, in an erasure-coded pool the primary OSD in the up set receives all write operations In replicated pools, Ceph makes a deep copy of each object in the placement group on the secondary OSD(s) in the set For erasure coding, the process is a bit different. An erasure coded pool stores each object as K+M chunks. It is divided into K data chunks and M coding chunks. The pool is configured to have a size of K+M so that each chunk is stored in an OSD in the acting set. The rank of the chunk is stored as an attribute of the object. The primary OSD is responsible for encoding the payload into K+M chunks and sends them to the other OSDs. It is also responsible for maintaining an authoritative version of the placement group logs. https://software.intel.com/en-us/blogs/2015/04/06/ceph-erasure-coding-introduction

149
Ceph – Erasure Coding – 3/5 5 OSDs (K+M=5); sustain loss of 2 (M=2) Object NYAN with data “ABCDEGHI” is split into 3 chunks; padded if length is not a multiple of K Coding blocks are YXY and QGC RedHat Ceph Architecture v1.2.3
; sustain loss of 2 (M=2) Object NYAN with data ABCDEGHI is split into 3 chunks; padded if length is not a multiple of K Coding blocks are YXY and QGC RedHat Ceph Architecture v1.2.3")
150
Ceph – Erasure Coding – 4/5 On reading object NYAN from an erasure coded pool, decoding function retrieves chunks 1, 2, 3 and 4 If any two chunks are missing (ie an erasure is present), decoding function can reconstruct other chunks RedHat Ceph Architecture v1.2.3
, decoding function can reconstruct other chunks RedHat Ceph Architecture v1.2.3")
151
Ceph – Erasure Coding – 4/5 5 OSDs (K+M=5); sustain loss of 2 (M=2) Object NYAN with data “ABCDEGHI” is split into 3 chunks; padded if length is not a multiple of K Coding blocks are YXY and QGC RedHat Ceph Architecture v1.2.3
; sustain loss of 2 (M=2) Object NYAN with data ABCDEGHI is split into 3 chunks; padded if length is not a multiple of K Coding blocks are YXY and QGC RedHat Ceph Architecture v1.2.3")
Similar presentations










>")





 Origin of Hadoop What is Hadoop & what it is not ? Hadoop architecture Hadoop components (Common/HDFS/MapReduce)>")










 INTERESTS: SYSTEMS, WEB.>")

 2007 Google and are licensed under.>")