Download presentation
Presentation is loading. Please wait.

1
1 Chapter 6: Semantic Analysis

2
2 Semantic Analyzer ==> Semantic Structure - What is the program supposed to do? - Semantics analysis can be done during syntax analysis phase or intermediate code generator phase or the final code generator. - typical static semantic features include declarations and type checking. - information (attributes) gathered can be either added to the tree as annotations or entered into the symbol table.
 gathered can be either added to the tree as annotations or entered into the symbol table..")
3
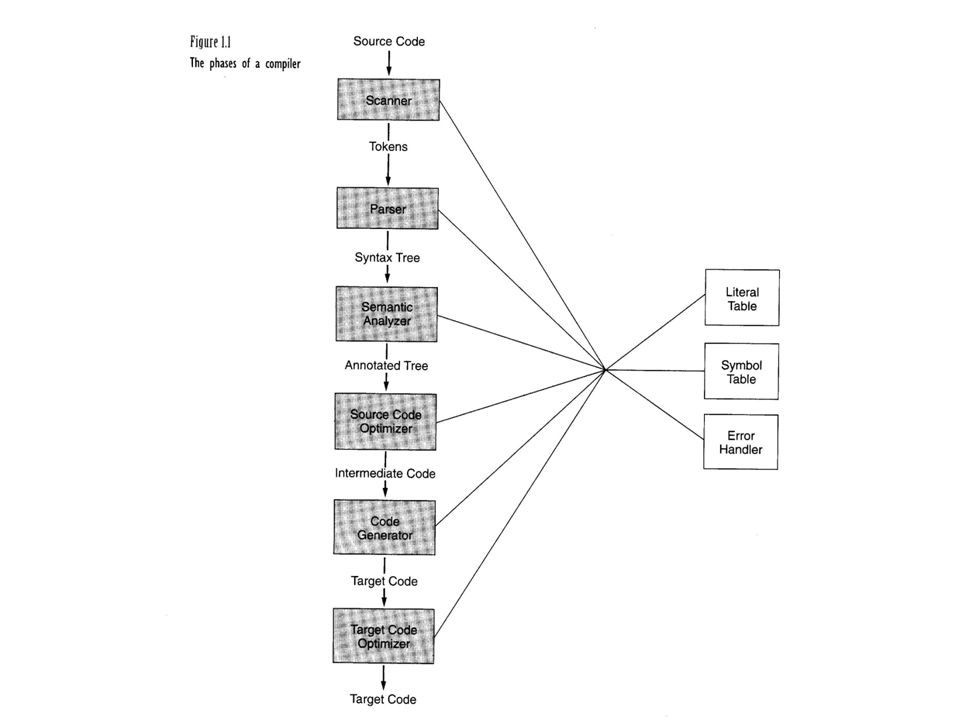
3 Compiling Process & Compiler Structure Input (Stream of chars) char handler scannerparser intermediate code generator code optimizercode generator peephole optimizer semantic analyzer Target Code
 char handler scannerparser intermediate code generator code optimizercode generator peephole optimizer semantic analyzer Target Code")
5
5 Output of the semantic analyzer – annotated AST with subscripts from a range

6
6 Two Categories of Semantic Analysis 1. The analysis of a program to meet the definition of the programming language. 2. The analysis of a program to enhance the efficiency of execution of the translated program.

7
7 Semantic Analysis Process includes formally: - description of the analyses to perform - implementation of the analysis (translation of the description) that may use appropriate algorithms.
 that may use appropriate algorithms.")
8
8 Description of Semantic Analysis 1. Identify attributes (properties) of language (syntactic) entities. 2. Write attribute equations (or semantic rules) that express how the computation of such attributes is related to the grammar rules of the language. Such a set of attributes and equations is called an attribute grammar.
 of language (syntactic) entities. 2. Write attribute equations (or semantic rules) that express how the computation of such attributes is related to the grammar rules of the language. Such a set of attributes and equations is called an attribute grammar..")
9
9 Syntax-directed semantics - The semantic content of a program is closely related to its syntax. - All modern languages have this property.

10
10 Attributes - An attribute is any property of a programming language construct. - Typical examples of attributes are: the data type of a variable, the value of an expression, the location of a variable in memory, the object code of a procedure, the number of significant digits in a number. - Attribute corresponds to the name of a field of a structure.

11
11 Attribute Grammars In syntax-directed semantics, attributes are associated with grammar symbols of the language. That is, if X is a grammar symbol and a is an attribute associated to X, then we write X.a for the value of a associated to X. For each grammar rule X 0 -> X 1 X 2 …X n the values of the attributes X i.a j of each grammar symbol X i are related to the values of the attributes of other grammar symbols in the rule.

12
12 That is, each relationship is specified by an attribute equation or semantic rule of the form: X i.a j = f ij (X 0.a 1,.., X 0.a k,.., X 1.a 1,.., X 1.a k,.., X n.a 1,.., X n.a k ) An attribute grammar for the attributes a 1,…,a k is the collection of all such attribute equations (semantic rules), for all the grammar rules of the language.
 An attribute grammar for the attributes a 1,…,a k is the collection of all such attribute equations (semantic rules), for all the grammar rules of the language.")
13
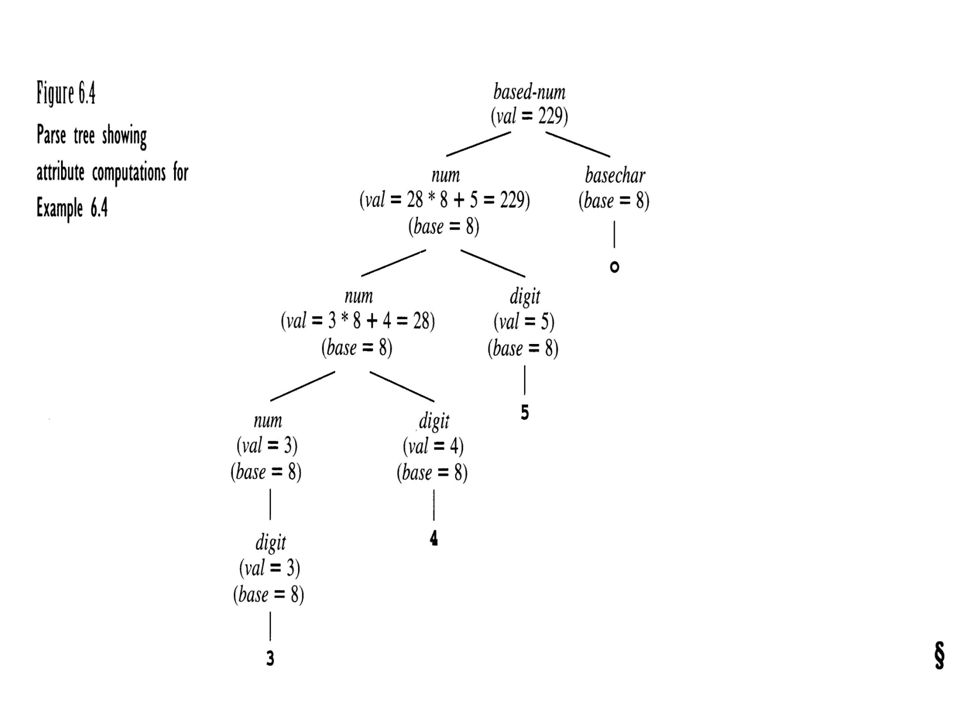
13 number.val must be computed prior to factor.val

14
14 Attribute grammars may involve several interdependent attributes.

15
e.g. 345o 128d 128o (x)
")
17
17 Attribute grammars may be defined for different purposes.

18
18

19
19 Algorithms for attribute computation Dependency graph and evaluation order

20
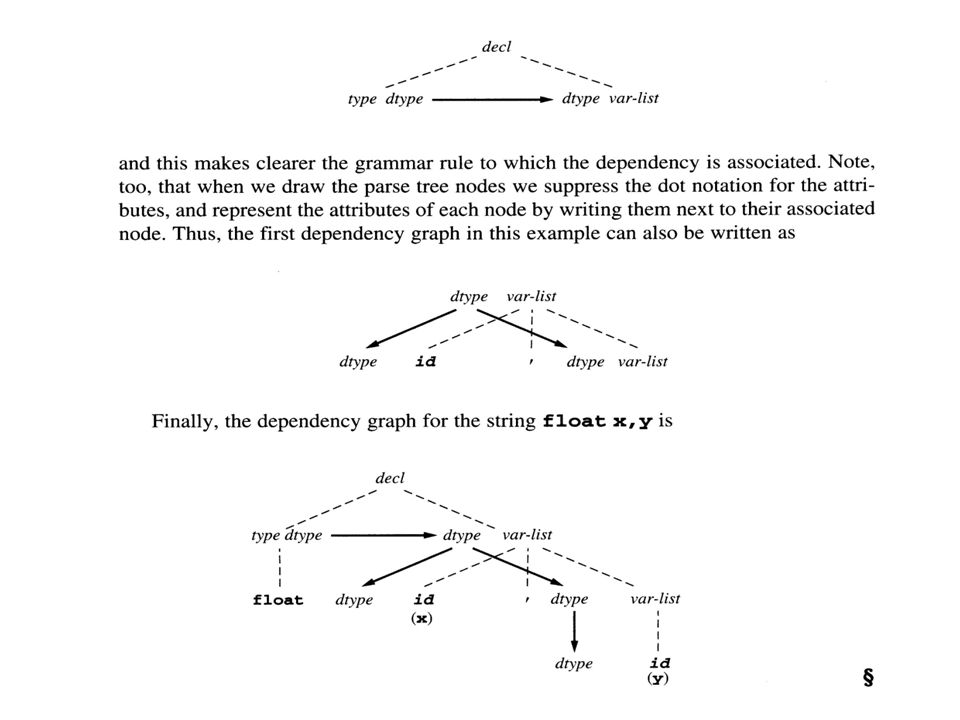
Attribute grammar for simple C-like variable declarations Grammar Rules Semantic Rules decl type var-list var-list.dtype = type.dtype type int type.dtype = integer type float type.dtype = real var-list 1 id, var-list 2 id.dtype = var-list 1.dtype var-list 2.dtype = var-list 1.dtype var-list id id.dtype = var-list.dtype

21
decl type (dtype = real) float var-list (dtype = real) id, var-list (x)(x) (dtype = real) id (y)(y) (dtype = real) Parse tree for the string float x, y
 float var-list (dtype = real) id, var-list (x)(x) (dtype = real) id (y)(y) (dtype = real) Parse tree for the string float x, y")
24
decl type (dtype = real) float var-list (dtype = real) id, var-list (x) (dtype = real) id (y) (dtype = real) Parse tree for the string float x, y trivial dependency
 float var-list (dtype = real) id, var-list (x) (dtype = real) id (y) (dtype = real) Parse tree for the string float x, y trivial dependency")
26
Procedure PreEval (T: treenode); begin for each child C of T do compute all inherited attributes of C; PreEval (C); end; Algorithm for evaluating inherited attributes preorder traversal
; begin for each child C of T do compute all inherited attributes of C; PreEval (C); end; Algorithm for evaluating inherited attributes preorder traversal")
27
27

28
28

30
30

31
31

32
base is computed in preorder and val in postorder

33
33 Synthesized Attributes An attribute a is synthesized if, given a grammar rule A -> X 1 X 2 …X n, the only associated attribute equation with an a on the left-hand side is of the form: A.a = f (X 1.a 1,.., X 1.a k,.., X n.a 1,.., X n.a k ) e.g., E 1 -> E 2 + E 3 {E 1.val = E 2.val + E 3.val; } where E.val represents the attribute (numerical value obtained) for E An attribute grammar in which all the attributes are synthesized is called S-attributed grammar.
 e.g., E 1 -> E 2 + E 3 {E 1.val = E 2.val + E 3.val; } where E.val represents the attribute (numerical value obtained) for E An attribute grammar in which all the attributes are synthesized is called S-attributed grammar.")
34
34

35
+ - 8 64

36
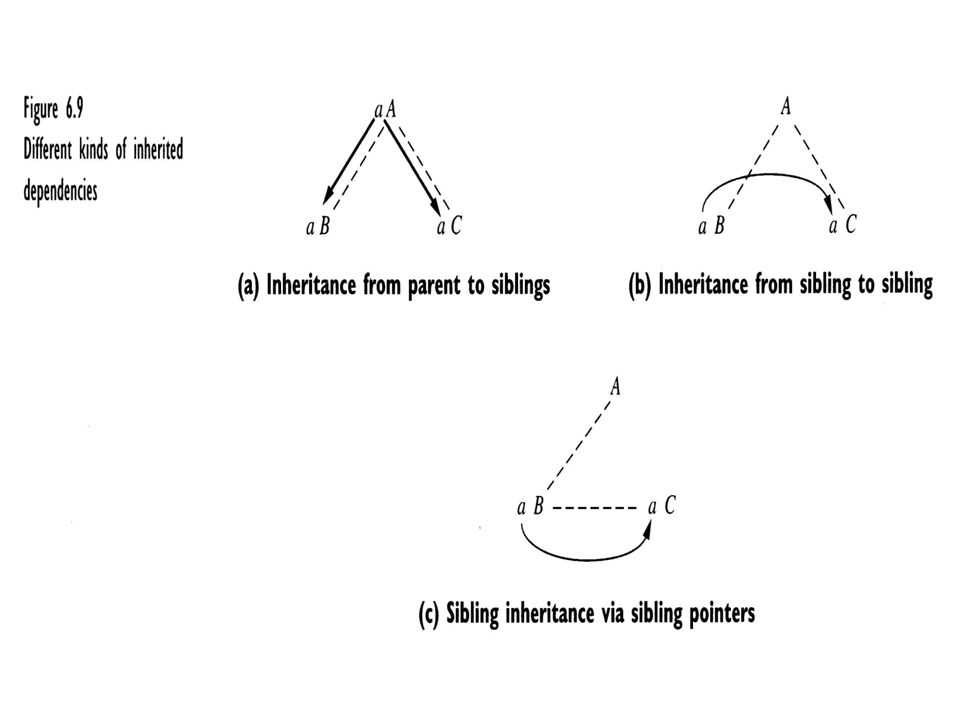
36 Inherited Attributes An attribute that is not synthesized is called an inherited attribute.

38
38 Computation of Attributes During Parsing L-attributed grammars

39
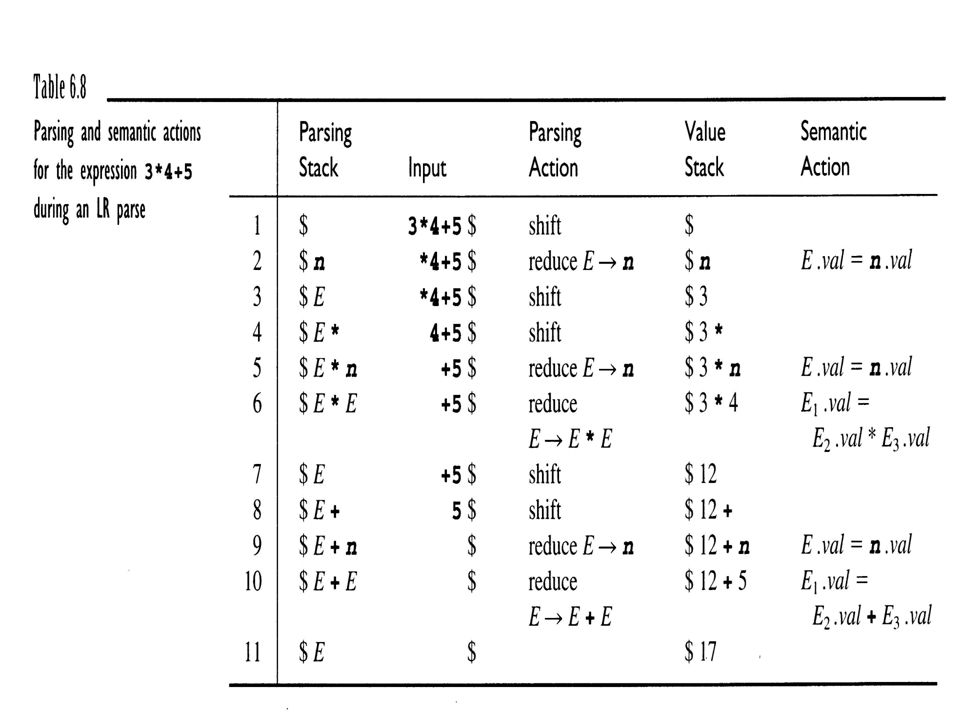
39 -- LALR(1) parser are primarily suited to handling synthesized attributes. -- Two stacks are required. value stack and parsing stack Computing Synthesized Attributes During LR Parsing

41
File: desk.l % “.” {} “+” {return(PLUS);} “-“ {return(MINUS);} “*” {return(MULT);} “/” {return(DIV);} “(“ {return(LPAREN);} “)” {return(RPAREN);} [0-9]+ {return(CONST);} \n {return(EOLN);}. {printf(“Invalid character: %s”,yytext);} % File: desk.y %token PLUS,MINUS,MULT,DIV,POWER,CONST %token LPAREN, RPAREN %token EOLN %left PLUS,MINUS %left MULT,DIV % list : exp ELON {printf(%d\n”,$$);} | list exp ELON {printf(%d\n”,$2);} ; exp : CONST {$$=atoi(yytext);} | exp PLUS exp {$$=$1+$3;} | exp MINUS exp {$$=$1-$3;} | exp MULT exp {$$=$1*$3;} | MINUS exp {$$=-$2;} | exp DIV exp {$$=$1/$3;} | LPAREN exp RPAREN {$$=$2;} ; % #include “lex.yy.c” yyerror() {printf(“Syntax error\n”);} yywrap() {exit(1);} main() {yyparse();}
![File: desk.l % . {} + {return(PLUS);} - {return(MINUS);} * {return(MULT);} / {return(DIV);} ( {return(LPAREN);} ) {return(RPAREN);} [0-9]+ {return(CONST);} \n {return(EOLN);}.](http://images.slideplayer.com/32/9986378/slides/slide_41.jpg "{printf( Invalid character: %s ,yytext);} % File: desk.y %token PLUS,MINUS,MULT,DIV,POWER,CONST %token LPAREN, RPAREN %token EOLN %left PLUS,MINUS %left MULT,DIV % list : exp ELON {printf(%d\n ,$$);} | list exp ELON {printf(%d\n ,$2);} ; exp : CONST {$$=atoi(yytext);} | exp PLUS exp {$$=$1+$3;} | exp MINUS exp {$$=$1-$3;} | exp MULT exp {$$=$1*$3;} | MINUS exp {$$=-$2;} | exp DIV exp {$$=$1/$3;} | LPAREN exp RPAREN {$$=$2;} ; % #include lex.yy.c yyerror() {printf( Syntax error\n );} yywrap() {exit(1);} main() {yyparse();}.")
42
File: Test 3*4+5*14 46-3*2+8/2 -35*3+5 File: Test.out 82 44 -100 Syntax error

43
43

44
44 Translation (Attribute Computation) A translation scheme is merely a context-free grammar in which a program fragment called semantic action is associated with each production.
 A translation scheme is merely a context-free grammar in which a program fragment called semantic action is associated with each production.")
45
45 e.g. A -> XYZ { } In a bottom up parser the semantic actions is taken when XYZ is reduced to A. In a top- down parser the action is taken when A, X, Y, or Z is expanded, whichever is appropriate.

46
46 Semantic Action In addition to those stated before, the semantic action may also involve: 1. the computation of values for variables belonging to the compiler. 2. the generation of intermediate code. 3. the printing of an error diagnostic. 4. the placement of some values in the symbol table.

47
47 Consider the following basic programming-language constructs for generating intermediate codes: 1. Declarations (ˇ) 2. arithmetic assignment operations (ˇ) 3. Boolean expressions (ˇ) 4. flow-of-control statements` if-statement(ˇ) while (ˇ) 5. array references (Δ) 6. procedure calls (ˇ) 7. switch statements (Δ) 8. structure-type references (Δ)
 2. arithmetic assignment operations (ˇ) 3. Boolean expressions (ˇ) 4. flow-of-control statements` if-statement(ˇ) while (ˇ) 5. array references (Δ) 6. procedure calls (ˇ) 7. switch statements (Δ) 8. structure-type references (Δ).")
48
Bottom-up Translation of S-attributed Grammars - A bottom-up parser uses a stack to hold information about subtrees that have been parsed. We can use extra fields in the parser stack to hold the values of synthesized attributes. e.g. A -> XYZ {A.a = f (X.x, Y.y, Z.z)} - Before reduction: the value of the attribute Z.z is in val [top], Y.y is in val [top-1], and Z.z is in val [top-2]. After reduction: top is decremented by 2, A.a is put in val [top]
} - Before reduction: the value of the attribute Z.z is in val [top], Y.y is in val [top-1], and Z.z is in val [top-2]. After reduction: top is decremented by 2, A.a is put in val [top].")
49
49 For Special Conditions : Hook stmt -> IF cond THEN { action to emit appropriate cond. jump } stmt ELSE { action to emit appropriate uncond. jump } stmt Or hook1-> { action to emit appropriate conditional jump } hook2-> { action to emit appropriate unconditional jump } stmt -> IF cond THEN hook1 stmt ELSE hook2 stmt stmt -> IF cond THEN stmt ELSE stmt ==>

50
50 Semantic Actions for different language constructs 1. Declarations e.g. int x,y,z; float w, z, s;

51
51 Suggested grammar: (Note: This is a very simple grammar mainly used for explanation.) P -> MD; M -> /* empty string */ D -> D, id | int id | float id P M D D, id int id ; int x, y ;
 P -> MD; M -> /* empty string */ D -> D, id | int id | float id P M D D, id int id ; int x, y ;")
52
52 (Syntax-directed) Translation P -> MD; {/* do nothing */} M -> { if offset was not initialized then offset = 0;} D -> int id { enter (id.name, int, offset); /* a function entering type “int” and particular offset to the entry id.name of the symbol table */ D.type = int; offset = offset + 4; /*bytes, width of int*/ D.offset = offset; }
 Translation P -> MD; {/* do nothing */} M -> { if offset was not initialized then offset = 0;} D -> int id { enter (id.name, int, offset); /* a function entering type int and particular offset to the entry id.name of the symbol table */ D.type = int; offset = offset + 4; /*bytes, width of int*/ D.offset = offset; }")
53
D -> float id { enter (id.name, float, offset); D.type = float; offset = offset + 8; /*bytes, width of float*/ D.offset = offset ; } D -> D (1), id { enter (id.name, D (1).type, D (1).offset); D.type = D (1).type; If D (1).type == int D.offset = D (1).offset + 4; else if D (1).type == float D.offset = D (1).offset+8; offset = D.offset;} Note: We can construct a data structure to store the information (attributes) of D. (i.e., D.type and D.offset)
.")
54
54 Avoided grammar: D -> int namelist ; | float namelist ; namelist -> id, namelist | id Why? When the 'id' is reduced into namelist, we cannot know the type of 'id' (int or float?) immediately. Therefore, it is troublesome to enter such type information into the corresponding field of the 'id' in the symbol table. Hence, we must use special coding technique (e.g. linked list keeping the ids name (pointers to symbol table) to achieve such a purpose. (* In other words, we need backpatch to chain the data type.) D int namelist ; id int x ;
 immediately. Therefore, it is troublesome to enter such type information into the corresponding field of the id in the symbol table. Hence, we must use special coding technique (e.g. linked list keeping the ids name (pointers to symbol table) to achieve such a purpose. (* In other words, we need backpatch to chain the data type.) D int namelist ; id int x ;.")
55
55 Acceptable grammar: D -> int intlist ; | float floatlist ; intlist -> id, intlist | id Advantage: The above-mentioned problem will not happen. That is, when 'id' is reduced, we can identify the type of id. (If id is reduced to intlist, then id is of “int” type) Defect: too much production will occur. => too many states => bad performance floatlist -> id, floatlist | id
 Defect: too much production will occur. => too many states => bad performance floatlist -> id, floatlist | id.")
56
56 How to handle the following declaration? x,y,z : float Two approaches: (I) decl -> id_list ':' type id_list -> id_list ',' id | id type -> int | float (II) decl -> id ':' type | id, decl type -> int | float Which one is better for LR parsing? Why?
 decl -> id_list : type id_list -> id_list , id | id type -> int | float (II) decl -> id : type | id, decl type -> int | float Which one is better for LR parsing. Why .")
57
57 Suggested Grammar for the following Declaration: var x,y,z : real; u,v,t : integer; … declarations : VAR decl_list | /* empty (no declaration is permitted) */ ; decl_list : declaration ';' | declaration ';' decl_list ; declaration : ID ':' type | ID ',' declaration ; type : REAL | INTEGER ;
 */ ; decl_list : declaration ; | declaration ; decl_list ; declaration : ID : type | ID , declaration ; type : REAL | INTEGER ;")
58
Try to construct a parse tree for the following declaration and see how to parse it: var x: real; y: integer; declarations VAR decl_list var declaration ; decl_list ID : type declaration ; x real ID : type y integer

59
59 The following grammar for declaration is difficult for attribute gathering. declaration : id_list ':' type ; id_list : ID | id_list ',' ID type : REAL | INTEGER

60
e.g., declaration id_list : type id_list, ID REAL id_list, ID ID

61
Intermediate Code Generation Three Address Code (Two Address code => Triples) Quadruples (a collective data structure, each unit is with 4 fields) Operator Arg1 Arg2 Result =+ =- =* =/ =% []= =[] …. Note: The entries of operator column are integers that represent individual operators. The entries of Arg1 (operand1) Arg2 (operand2) and Result are index (pointer) to the symbol table.
![Intermediate Code Generation Three Address Code (Two Address code => Triples) Quadruples (a collective data structure, each unit is with 4 fields) Operator Arg1 Arg2 Result =+ =- =* =/ =% []= =[] ….](http://images.slideplayer.com/32/9986378/slides/slide_61.jpg "Note: The entries of operator column are integers that represent individual operators. The entries of Arg1 (operand1) Arg2 (operand2) and Result are index (pointer) to the symbol table..")
62
Kinds of three-address codes: 1. A = B op (1) C (op is a binary arithmetic or logical operation) 2. A = op (2) B (op is a unary operation, e.g. minus, negation, shift operators, conversion operator, identity operator) 3. goto L (unconditional jump, execute the Lth three- address code) 4. if A relop B goto L (relop denotes relational operators, e.g., <, ==, >, >=, !=, etc.) 5. param A and call P,n (used to implement a procedure call) 6. A = B [i] 7. A[i] = B 8. A = &B 9. A = *B 10. *A = B
 B (op is a unary operation, e.g. minus, negation, shift operators, conversion operator, identity operator) 3. goto L (unconditional jump, execute the Lth three- address code) 4. if A relop B goto L (relop denotes relational operators, e.g., <, ==, >, >=, !=, etc.) 5. param A and call P,n (used to implement a procedure call) 6. A = B [i] 7. A[i] = B 8. A = &B 9. A = *B 10. *A = B.")
63
63 In Quadruples: Operator Arg1 Arg2 Result 1. ==> op (1) B C A 2. ==> op (2) B A 3. ==> goto L 4. ==> relopgoto A B L 5. ==> param A 5. ==> call P n 6. ==> =[] B i A 7. ==> []= B i A 8. ==> =& B A 9. ==> =* B A 10. ==> *= B A
 B A 3. ==> goto L 4. ==> relopgoto A B L 5. ==> param A 5. ==> call P n 6. ==> =[] B i A 7. ==> []= B i A 8. ==> =& B A 9. ==> =* B A 10. ==> *= B A.")
64
Example: D = A*B+C The generated three address code is: T1 = A * B T1 = B * C T2 = T1 + C T2 = A + T1 D = T2 D = T2 Operator Arg1 Arg2 Result =* A B T1 =+ T1 C T2 = T2 D * T1 and T2 are compiler-generated temporary variables and they are also saved in the symbol table. D = A + B * C

65
65 Actually, in implementation the quadruples look as: Operator Arg1 Arg2 Result 8 6 7 9 15 9 8 11 3 11 10 in symbol table: index identifier attributes 0 twa 1 K.... 6 A 7 B 8 C 9 T1 /* compiler generated temporary variable */ 10 D 11 T2 /* compiler generated temporary variable */

66
66 2. Arithmetic Statements A -> id = E E -> E (1) + E (2) E -> E (1) - E (2) E -> E (1) * E (2) E -> E (1) / E (2) E -> - E (1) E -> (E (1) ) E -> id A id =E E +E x = a + bT1 = a + b x = T1
 + E (2) E -> E (1) - E (2) E -> E (1) * E (2) E -> E (1) / E (2) E -> - E (1) E -> (E (1) ) E -> id A id =E E +E x = a + bT1 = a + b x = T1.")
67
A -> id = E { GEN (id.place = E.place); } /* GEN (argument) - a function used to save its argument into the quadruple. The implementation of E is a data structure with one field E.place which holds the name that will hold the index value of the symbol table. */ E -> E (1) + E (2) { T = NEWTEMP(); /* NEWTEMP() - a function used to generate a temporary variable T and save T into symbol table and return the index value of the symbol table. */ E.place = T; /* T’s index value in symbol table is assigned to E.place */ GEN(E.place = E (1).place + E (2).place); } T = a + b
 + E (2) { T = NEWTEMP(); /* NEWTEMP() - a function used to generate a temporary variable T and save T into symbol table and return the index value of the symbol table. */ E.place = T; /* T’s index value in symbol table is assigned to E.place */ GEN(E.place = E (1).place + E (2).place); } T = a + b.")
68
E -> E (1) * E (2) { T = NEWTEMP(); E.place = T; GEN(E.place = E (1).place * E (2).place); } E -> - E (1) { T = NEWTEMP(); E.place = T; GEN(E.place = -E (1).place); } E -> (E (1) ) { E.place = E (1).place; } E -> id { E.place = id.place; } /* 將 id 之符號表 index 值傳給 E 之 field 'place' ; In implementation id.place refers to the index value of id in the symbol table. */

69
Enhanced version for E -> E (1) op E (2) ** 注意 in this version E 所對應資料結構之設計 ( 應以 array of struct of E 之資料結構來儲存各個 E 之 attributes, 並將對 應之 array index 值儲存於 E 對應之 value stack 中 ) { T = NEWTEMP(); if E (1).type == int and E (2).type == int then { GEN (T = E (1).place intop E (2).place); E.type = int; } else if E (1).type == float and E (2).type == float then { GEN (T = E (1).place floatop E (2).place);
 op E (2) ** 注意 in this version E 所對應資料結構之設計 ( 應以 array of struct of E 之資料結構來儲存各個 E 之 attributes, 並將對 應之 array index 值儲存於 E 對應之 value stack 中 ) { T = NEWTEMP(); if E (1).type == int and E (2).type == int then { GEN (T = E (1).place intop E (2).place); E.type = int; } else if E (1).type == float and E (2).type == float then { GEN (T = E (1).place floatop E (2).place);")
70
E.type = float; } else if E (1).type == int and E (2). type == float then { U = NEWTEMP(); GEN (U = inttofloat E (1).place); GEN (T = U floatop E (2).place); E. type = float; } else /* E (1). type == float and E (2). type == int then { U = NEWTEMP(); GEN (U = inttofloat E (2).place); GEN (T = E (1).place floatop U); E. type = float; }
; GEN (U = inttofloat E (1).place); GEN (T = U floatop E (2).place); E. type = float; } else /* E (1). type == float and E (2). type == int then { U = NEWTEMP(); GEN (U = inttofloat E (2).place); GEN (T = E (1).place floatop U); E. type = float; }.")
71
71 3. Boolean Expression M -> E -> E or M E | E and M E | not E | ( E ) | id | id relop id
 | id | id relop id")
72
72 An example if p < q || r < s && t < u x = y + z; k = m – n; For the above boolean expression the corresponding contents in the quadruples are:

73
Location Three-Address Code … …………. 100 if p < q goto 106 101 goto 102 102 if r < s goto 104 103 goto 108 104 if t < u goto 106 105 goto 108 /*s.next = 105 106 t1 = y + z 107 x = t1 108 t2 = m - n 109 k = t2............ quadruples if p < q || r < s && t < u x = y + z; k = m – n; E E or M E E and M E id < id counter = 100

74
NEXTQUAD – an integer variable used for saving the index (location) value of the next available entry of the quadruples. E.true – an attribute of E that holds a set of indexes (locations) of the quadruples, each indexed quadruple saves the three-address code with ‘true’ boolean expression. E.false – an attribute of E that holds a set of indexes of the quadruples, each indexed quadruple saves the three-address code with ‘false’ boolean expression. GEN(x) – a function that translates x (a kind of three-address-code) into quadruple representation. So, we need to construct a data structure for E which includes two fields, each field can save an unlimited number of integer. Meanwhile, we need to construct an array of this E’s structure to store several Es’ attributes to be used in the same period of time.
 of the quadruples, each indexed quadruple saves the three-address code with ‘true’ boolean expression. E.false – an attribute of E that holds a set of indexes of the quadruples, each indexed quadruple saves the three-address code with ‘false’ boolean expression. GEN(x) – a function that translates x (a kind of three-address-code) into quadruple representation. So, we need to construct a data structure for E which includes two fields, each field can save an unlimited number of integer. Meanwhile, we need to construct an array of this E’s structure to store several Es’ attributes to be used in the same period of time..")
75
1. M -> { M.quad = NEXTQUAD; } /* M.quad is a data structure associated with M */ 2. E -> E (1) or M E (2) { BACKPATCH (E (1).false, M.quad); E.true = MERGE (E (1).true, E (2).true); E.false = E (2).false; } /* BACKPATCH (p, i) – a function that makes each of the quadruple index values on the list pointed to by p take quadruple i as a target (i.e., goto i).*/ /* MERGE (a, b) – a function that takes the lists pointed to by a and b, concatenates them into one list, and returns a pointer to the concatenated list. */
 or M E (2) { BACKPATCH (E (1).false, M.quad); E.true = MERGE (E (1).true, E (2).true); E.false = E (2).false; } /* BACKPATCH (p, i) – a function that makes each of the quadruple index values on the list pointed to by p take quadruple i as a target (i.e., goto i).*/ /* MERGE (a, b) – a function that takes the lists pointed to by a and b, concatenates them into one list, and returns a pointer to the concatenated list. */.")
76
3. E -> E (1) and M E (2) { BACKPATCH (E (1).true, M.quad); E.true = E (2).true; E.false = MERGE (E (1).false, E (2).false); } 4. E -> not E (1) { E.true = E (1).false; E.false = E (1).true;} 5. E -> ( E (1) ) { E.true = E (1).true; E.false = E (1).false;}
 and M E (2) { BACKPATCH (E (1).true, M.quad); E.true = E (2).true; E.false = MERGE (E (1).false, E (2).false); } 4. E -> not E (1) { E.true = E (1).false; E.false = E (1).true;} 5. E -> ( E (1) ) { E.true = E (1).true; E.false = E (1).false;}.")
77
6. E -> id { E.true = MAKELIST (NEXTQUAD); E.false = MAKELIST(NEXTQUAD + 1); GEN (if id.place goto _ ); GEN (goto _); } /* MAKELIST ( i ) – a function that creates a list containing i, an index into the array of quadruples, and returns a pointer to the list it has made. */ /* GEN(x) – a function that translates x (a kind of three-address- code) into quadruple representation. */
; E.false = MAKELIST(NEXTQUAD + 1); GEN (if id.place goto _ ); GEN (goto _); } /* MAKELIST ( i ) – a function that creates a list containing i, an index into the array of quadruples, and returns a pointer to the list it has made. */ /* GEN(x) – a function that translates x (a kind of three-address- code) into quadruple representation. */.")
78
78 7. E -> id (1) relop id (2) { E.true = MAKELIST (NEXTQUAD); E.false = MAKELIST(NEXTQUAD + 1); GEN (if id (1).place relop id (2).place goto _ ); GEN (goto _); } false E true 20 if id (1).place relop id (2).place goto _ 20 21goto _ …. NEXTQUAD 21 … 22
 relop id (2) { E.true = MAKELIST (NEXTQUAD); E.false = MAKELIST(NEXTQUAD + 1); GEN (if id (1).place relop id (2).place goto _ ); GEN (goto _); } false E true 20 if id (1).place relop id (2).place goto _ 20 21goto _ …. NEXTQUAD 21 … 22.")
79
79 4. Flow-of-Control statements A. Conditional Statements S -> if E then S else S | if E then S | A | begin L end L -> S | L ; S /* A – denotes a general assignment statement L – denotes statement list S – denotes statement */

80
80 1. S -> if E then M (1) S (1) N else M (2) S (2) { BACKPATCH (E.true, M (1).quad); BACKPATCH (E.false, M (2).quad); S.next = MERGE (S (1).next, N.next, S (2).next); } /* S.next is a pointer to a list of all conditional and unconditional jump (goto) to the quadruple following the statement S in execution order. */
 S (1) N else M (2) S (2) { BACKPATCH (E.true, M (1).quad); BACKPATCH (E.false, M (2).quad); S.next = MERGE (S (1).next, N.next, S (2).next); } /* S.next is a pointer to a list of all conditional and unconditional jump (goto) to the quadruple following the statement S in execution order. */.")
81
81 2. S -> if E then M S (1) { BACKPATCH (E.true, M.quad); S.next = MERGE (E.false, S (1).next) } 3. M -> { M.quad = NEXTQUAD; } 4. N -> { N.next = MAKELIST (NEXTQUAD); GEN (goto _); } next N 20 NEXTQUAD = 20 20 Goto ___ NEXTQUAD
 { BACKPATCH (E.true, M.quad); S.next = MERGE (E.false, S (1).next) } 3. M -> { M.quad = NEXTQUAD; } 4. N -> { N.next = MAKELIST (NEXTQUAD); GEN (goto _); } next N 20 NEXTQUAD = Goto ___ NEXTQUAD.")
82
82 5. S -> A { S.next = MAKELIST ( ); } /* initialize S.next to an empty list */ 6. L -> S { L.next = S.next; } 7. L -> L (1) ; M S { BACKPATCH (L (1).next, M.quad); // To resolve all quadruples with conditional & unconditional unresolved ‘goto _’ L.next = S.next; } 8. S -> begin L end { S.next = L.next; }
 ; M S { BACKPATCH (L (1).next, M.quad); // To resolve all quadruples with conditional & unconditional unresolved ‘goto _’ L.next = S.next; } 8. S -> begin L end { S.next = L.next; }.")
83
83 B. Iterative Statement S -> while E do S 9. S -> while M (1) E do M (2) S (1) { BACKPATCH (E.true, M (2).quad); BACKPATCH (S (1).next, M (1).quad); S.next = E.false; GEN (goto M (1).quad); }
 E do M (2) S (1) { BACKPATCH (E.true, M (2).quad); BACKPATCH (S (1).next, M (1).quad); S.next = E.false; GEN (goto M (1).quad); }.")
84
An example: while (A<B) do if (C<D) then X = Y + Z; Index Three-Address Code … ….. 100 if (A<B) goto 102 101 goto __ //will be resolved (filling 107) later 102 if (C<D) goto 104 103 goto 100 104 T = Y + Z 105 X = T 106 goto 100 107 … E 1 3 2 E If (C<D) then X=Y+Z;
 goto goto __ //will be resolved (filling 107) later 102 if (C<D) goto goto T = Y + Z 105 X = T 106 goto … E E If (C<D) then X=Y+Z;.")
85
5. Array References Addressing Array Elements one-dimension: A[low..high] two-dimension: A[low1..high1, low2..high2] n-dimension: A[low1..high1, low2..high2,..., lown..highn] Let: base = address of beginning of A, and w = width of an array element ni = the number of array elements in i-th dimension (row) /* row major */ ( e.g. n1 = high1 - low1 + 1; n2 = high2 - low2 + 1; n3 = high3 - low3 + 1;...)
 /* row major */ ( e.g. n1 = high1 - low1 + 1; n2 = high2 - low2 + 1; n3 = high3 - low3 + 1;...).")
86
A[i] has address: base (of A) + (i - low) * w = i * w + (base – low * w), where base - low * w is compile-time invariant. A[i1, i2] has address (row-major): base + ((i1 - low1) * n2 + i2 - low2) * w = (i1 * n2 + i2) * w + base - (low1 * n2 + low2) * w, where base - (low1 * n2 + low2) * w is compile- time invariant A[i1, i2, i3] has address: base + ((i1 - low1) * n2 * n3 + (i2 – low2) * n3 + (i3 - low3)) * w = base + (((i1 - low1) * n2 + (i2 - low2)) * n3 + (i3 - low3)) * w = ((i1* n2 + i2) * n3 + i3) * w + base - ((low1* n2 + low2) * n3 + low3) * w, where base – ((low1* n2 + low2) * n3 + low3) * w is compile-time invariant.
![A[i] has address: base (of A) + (i - low) * w = i * w + (base – low * w), where base - low * w is compile-time invariant.](http://images.slideplayer.com/32/9986378/slides/slide_86.jpg "A[i1, i2] has address (row-major): base + ((i1 - low1) * n2 + i2 - low2) * w = (i1 * n2 + i2) * w + base - (low1 * n2 + low2) * w, where base - (low1 * n2 + low2) * w is compile- time invariant A[i1, i2, i3] has address: base + ((i1 - low1) * n2 * n3 + (i2 – low2) * n3 + (i3 - low3)) * w = base + (((i1 - low1) * n2 + (i2 - low2)) * n3 + (i3 - low3)) * w = ((i1* n2 + i2) * n3 + i3) * w + base - ((low1* n2 + low2) * n3 + low3) * w, where base – ((low1* n2 + low2) * n3 + low3) * w is compile-time invariant..")
87
In general, A[i1, i2,...,ik] has address: ((..(((i1* n2 + i2) * n3 + i3) *n4 +... ) * nk + ik) * w + base - ((..((low1* n2 + low2) * n3 + low3)... ) * nk + lowk) * w, where base - ((..((low1* n2 + low2) * n3 + low3)... ) * nk + lowk) * w is compile-time invariant. Therefore, we can compute as follows: e1 = i1 e2 = e1* n2 + i2 e3 = e2* n3 + i3. em = em-1* nm + im. ek = ek-1* nk + ik
![In general, A[i1, i2,...,ik] has address: ((..(((i1* n2 + i2) * n3 + i3) *n4 +...](http://images.slideplayer.com/32/9986378/slides/slide_87.jpg ") * nk + ik) * w + base - ((..((low1* n2 + low2) * n3 + low3)... ) * nk + lowk) * w, where base - ((..((low1* n2 + low2) * n3 + low3)... ) * nk + lowk) * w is compile-time invariant. Therefore, we can compute as follows: e1 = i1 e2 = e1* n2 + i2 e3 = e2* n3 + i3. em = em-1* nm + im. ek = ek-1* nk + ik.")
88
88 The address of A[i1, i2,...,ik] is: ek * w + compile- time invariant.
![88 The address of A[i1, i2,...,ik] is: ek * w + compile- time invariant.](http://images.slideplayer.com/32/9986378/slides/slide_88.jpg "88 The address of A[i1, i2,...,ik] is: ek * w + compile- time invariant.")
89
Translation Scheme for Addressing Array Elements Assume: (1) for each id there exists id.place which holds its name, (2) there is a function ‘limit( )’ where limit(array_name, m) = nm i.e., the # of elements of array ‘array_name’ at dimension m-th, (3) we can find the width of an array element from the name of array (i.e. from symbol table)
.")
90
(1) S -> L = E { if L.offset = null then GEN (L.place = E.place) else GEN (L.place[L.offset] = E.place); } (2) E -> E 1 + E 2 /* and E -> E 1 – E 2 E -> E 1 * E 2 …. */ { E.place = newtemp(); //generate a temporary variable and save its symbol table index GEN (E.place = E 1.place+ E 2.place); } /* a[x+y, t-w] is legal array representation */
![(1) S -> L = E { if L.offset = null then GEN (L.place = E.place) else GEN (L.place[L.offset] = E.place); } (2) E -> E 1 + E 2 /* and E -> E 1 – E 2 E -> E 1 * E 2 ….](http://images.slideplayer.com/32/9986378/slides/slide_90.jpg "*/ { E.place = newtemp(); //generate a temporary variable and save its symbol table index GEN (E.place = E 1.place+ E 2.place); } /* a[x+y, t-w] is legal array representation */.")
91
(3) E -> (E (1) ) { E.place = E (1).place } (4) E -> L { if L.offset = null then E.place = L.place else E.place = newtemp(); GEN (E.place = L.place[L.offset]);} (5) L -> Elist ] { L.place = Elist.array; L.offset = newtemp(); GEN (L.offset = w * Elist.place); } /* w is known from declaration of array */
![(3) E -> (E (1) ) { E.place = E (1).place } (4) E -> L { if L.offset = null then E.place = L.place else E.place = newtemp(); GEN (E.place = L.place[L.offset]);} (5) L -> Elist ] { L.place = Elist.array; L.offset = newtemp(); GEN (L.offset = w * Elist.place); } /* w is known from declaration of array */](http://images.slideplayer.com/32/9986378/slides/slide_91.jpg "(3) E -> (E (1) ) { E.place = E (1).place } (4) E -> L { if L.offset = null then E.place = L.place else E.place = newtemp(); GEN (E.place = L.place[L.offset]);} (5) L -> Elist ] { L.place = Elist.array; L.offset = newtemp(); GEN (L.offset = w * Elist.place); } /* w is known from declaration of array */")
92
(6) L -> id { L.place = id.place; L.offset = null } (7) Elist -> Elist (1), E { T = newtemp(); m = Elist (1).ndimen + 1; GEN ( T = Elist (1).place * limit(Elist.array, m)); GEN ( T = T + E.place ); Elist.array = Elist (1).array; Elist.place = T; Elist.ndimen = m; } /* note em = em-1* nm + im, where Elist.place = em, Elist (1).place = em-1, limit(Elist (1).array, m) = nm, and E.place = im */ (8) Elist -> id [ E { Elist.place = E.place; Elist.ndimen = 1; Elist.array := id.place; }
 L -> id { L.place = id.place; L.offset = null } (7) Elist -> Elist (1), E { T = newtemp(); m = Elist (1).ndimen + 1; GEN ( T = Elist (1).place * limit(Elist.array, m)); GEN ( T = T + E.place ); Elist.array = Elist (1).array; Elist.place = T; Elist.ndimen = m; } /* note em = em-1* nm + im, where Elist.place = em, Elist (1).place = em-1, limit(Elist (1).array, m) = nm, and E.place = im */ (8) Elist -> id [ E { Elist.place = E.place; Elist.ndimen = 1; Elist.array := id.place; }")
93
6. Procedure calls 1. call -> id (args) 2. args -> args, E 3. args -> E 1. call -> id (args) { for each item p on QUEUE do GEN (param p); GEN (call id.place, length of QUEUE); } /* QUEUE is a data structure for saving the indexes of the symbol table containing the names of the arguments. The length of QUEUE is the number of elements in QUEUE */
 { for each item p on QUEUE do GEN (param p); GEN (call id.place, length of QUEUE); } /* QUEUE is a data structure for saving the indexes of the symbol table containing the names of the arguments. The length of QUEUE is the number of elements in QUEUE */.")
94
2. args -> args, E { append E.place to the end of QUEUE; } 3. args -> E { initialize QUEUE to contain only E.place; } /* Originally, QUEUE is empty and, after the reduction of E to args, QUEUE contains a single pointer to the symbol table location for the name that denotes the value of E. */

95
7. Structure Declarations type -> struct { fieldlist} /*Note: symbols with bold face are terminals */ | ptr | char | int | float | double fieldlist -> fieldlist field; | field; field -> type id | field [integer /*a token denoting any string of digits*/] int x int x [10] [20] [30] field int x [10] or struct { int x; //offset 0 float y; //offset 2 char k[10];//offset 6 } m; m.width = 16 bytes

96
field -> type id { field.width = type.width; field.name = id.name; W_enter(id.name, type.width);} /* W_enter(name,width) enters ‘width’ as the width of each element of ‘name’. If ‘name’ is not an array, then its width is the number of locations taken by data of name’s type. */ | field (1) [integer] { field.width = field (1).width * integer.val; field.name = field (1).name; D_enter(field (1).name, integer.val);}
 [integer] { field.width = field (1).width * integer.val; field.name = field (1).name; D_enter(field (1).name, integer.val);}.")
97
/* D_enter(name,size) increases the number of dimensions for ‘name’ by one and enters the last dimension as ‘size’ in the symbol table entry for ‘name’. */ fieldlist -> field; {O_enter (field.name, 0); fieldlist.width = field.width;} /* O_enter(name,offset) makes ‘offset’ the number for which field name ‘name’ stands. This information, also, is recorded in the symbol table entry for ‘name’. */ |fieldlist (1) field; { fieldlist.width = fieldlist (1).width + field.width; O_enter(field.name, fieldlist (1).width);}
; fieldlist.width = field.width;} /* O_enter(name,offset) makes ‘offset’ the number for which field name ‘name’ stands. This information, also, is recorded in the symbol table entry for ‘name’. */ |fieldlist (1) field; { fieldlist.width = fieldlist (1).width + field.width; O_enter(field.name, fieldlist (1).width);}.")
98
type -> struct '{' fieldlist '} ' { type.width = fieldlist.width; } type -> char { type.width = 1; } /* Assume characters take one byte.*/ type -> ptr {type.width = 4; } /*Assume pointers take four bytes.*/ type -> int { type.width = 2; } /* Assume integers take two bytes.*/.......

99
99 8. Switch Statement Syntax: switch E { case V1: S1; case V2: S2;............. case Vn-1: Sn-1; default: Sn; }

100
When translated into three-address code: 100 Code to evaluate E into T 101 If T V1 goto 104 102 Code for S1 103 Goto 113 104 If T V2 goto 107 105 Code for S2 106 Goto 113 107... 108... 109 If T Vn-1 goto 112 110 Code for Sn-1 111 Goto 113 112 code for Sn 113 …. Temporary variable

101
101 Based on the given translation example, you can infer how to generate the three-address codes for switch statement easily !!!

102
102 Symbol Table consists of the records that associate attributes with various programmer declared objects. The main one is its name (a string of characters, e.g. identifier). semantic action will put information into symbol table or take out attribute from symbol table.
. semantic action will put information into symbol table or take out attribute from symbol table..")
103
103 What kind of objects? 1. variables 2. components of a composition structure (i.e., field names of structure) 3. labels 4. procedure and function name 5. parameters for procedure and function 6. files
 3. labels 4. procedure and function name 5. parameters for procedure and function 6. files.")
104
104 What attributes (attributes of objects)? 1. name 2. type (e.g. int, float, array, struct, a pointer to struct, etc.) 3. location for variables and entry point 4. value for named constant 5. initial value for variable 6. flag showing if it has been accessed.
 3. location for variables and entry point 4. value for named constant 5. initial value for variable 6. flag showing if it has been accessed..")
105
105 How does an attribute be represented? 1. Name strategy: (a) use a field of n char in the symbol table record to store the first (up to) n characters of the identifier. (b) use an auxiliary string table and store a pointer (e.g. 5) to the 1st char. of the identifier and the length ( e.g. 4) of the identifier in the "name" field of symbol table record.
 use a field of n char in the symbol table record to store the first (up to) n characters of the identifier. (b) use an auxiliary string table and store a pointer (e.g. 5) to the 1st char. of the identifier and the length ( e.g. 4) of the identifier in the name field of symbol table record..")
106
106 Scheme(B) allows arbitrary large name, saves space and requires more programming. Often this table is kept for string literals and can be used with little extra programming. Scheme(A) is simpler, faster and require less programming.
 is simpler, faster and require less programming..")
107
107 Def. The static scope of an occurrence of an identifier is that portion of the (source) program in which other occurrence of the same identifier represents the same object. 2. type Since type can be arbitrarily complex, they are best represented by a pointer to a linked data structure that reflects the structure of the type. (type is mainly used to determine if semantics is correct and offset computation.)
 program in which other occurrence of the same identifier represents the same object. 2. type Since type can be arbitrarily complex, they are best represented by a pointer to a linked data structure that reflects the structure of the type. (type is mainly used to determine if semantics is correct and offset computation.).")
108
108 e.g. in Pascal, it is the procedure or function in which it was declared minus all sub-procedures and sub-functions in which it is represented. program P; procedure Q; ----------------------------- var x: real; | procedure R; ----- | var x: integer; | | scope of x | minus this | x :=... | | end; ----- | | x := x + 1 | end; ---------------------------- end.

109
109 Symbol table mechanism ? 1. What should be done when translating a declaration? 2. What should be done when reference to an identifier? 3. What should be done when at scope entry? 4. What should be done when at scope exit?

110
110 Multiscope symbol table - descriptor is a record that describing an object. - its fields are called attributes - its key contains an identifier together with a context (a context is a block or a declaration, represented by a lexical number).
..")
111
111 e.g. float x; ------- struct y{ ----- | int x; | | int z; | inner context | another context. | | } ----- --------

112
Each context associated with a # (number), x will pair with the # to look up at symbol table. - when we enter a context (compiling time - not run time) we give it a new # on to the context stack (it is the current context). - when we exit a context we pop that # from the stack. - when resolving a reference to a simple identifier, say x9, we pair it with the current context and look it up in the symbol table, if not there try with next context, etc. until found, or we run out the context. - when declaring an object we allocate a descriptor for it. Put the current context into its context field and the identifier into its identifier-field. Then fill in other attribute as appropriate. In the case of a record declaration
 we give it a new # on to the context stack (it is the current context). - when we exit a context we pop that # from the stack. - when resolving a reference to a simple identifier, say x9, we pair it with the current context and look it up in the symbol table, if not there try with next context, etc. until found, or we run out the context. - when declaring an object we allocate a descriptor for it. Put the current context into its context field and the identifier into its identifier-field. Then fill in other attribute as appropriate. In the case of a record declaration.")
113
113 y has #2 in its context field and x has # 3 in its internal context field. Lookup y using context # 2. Look up its field x with context # 3. - when resolving a reference to a qualified identifier (e.g. student.grad) we look up the struct as before upon finding, we get an attribute that called (that will be a #) internal-context and lookup the field with the context to find the descriptor for that object. e.g. float x; ------ struct y { ---- | int x; | | int z; | context #3 | context #2. | | } ---- -------
 we look up the struct as before upon finding, we get an attribute that called (that will be a #) internal-context and lookup the field with the context to find the descriptor for that object. e.g. float x; struct y { ---- | int x; | | int z; | context #3 | context #2. | | }")
Similar presentations







 –C –Ada Dynamic (done during run time) –LISP –Smalltalk Optimization.>")









 { if (a > b) return &a; //wrong else return &b; //wrong } int * larger (int *a, int *b)>")




