Download presentation
Presentation is loading. Please wait.

2
Machine Learning – Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 (3 rd ed.) Ch 20.1-20.7, but not the part of 20.3 after “Learning Bayesian Networks” (2nd ed.)
 Ch , but not the part of 20.3 after Learning Bayesian Networks (2nd ed.)")
3
Mid-term Exam: Thursday, April 29 (one week) Tuesday, April 22, will be Review, Catch-up, Question&Answer Exam Format: –Closed Book, Closed Notes –No calculators, cell phones, or other electronic devices –Paper discussion 2:00-2:15, Exam 2:20-3:20 Topics: –Agents & Environments: All of Ch 2 except agent types (not 2.4.2-2.4.7) –Search: All of Ch 3; Ch 4.1-4.2 (not 4.3-4.5) (3 rd ed.) Ch 3.1-3.5 (not 3.6); Ch 4.1-4.4 (not 4.5) (2 nd ed.) –Probability & Uncertainty: All of Ch 13; Ch 14.1-14.2 –Learning: Ch 18 (not 18.5); Ch 20.1-20.3.2 (not 20.3.3-5) (2 nd & 3 rd ed.) Ch 20.4-20.7 (2 nd ed.) –Plus all material in class slides and homework related to the topics above – but not including face detection material in today’s slides
 Tuesday, April 22, will be Review, Catch-up, Question&Answer Exam Format: –Closed Book, Closed Notes –No calculators, cell phones, or other electronic devices –Paper discussion 2:00-2:15, Exam 2:20-3:20 Topics: –Agents & Environments: All of Ch 2 except agent types (not ) –Search: All of Ch 3; Ch (not ) (3 rd ed.) Ch (not 3.6); Ch (not 4.5) (2 nd ed.) –Probability & Uncertainty: All of Ch 13; Ch –Learning: Ch 18 (not 18.5); Ch (not ) (2 nd & 3 rd ed.) Ch (2 nd ed.) –Plus all material in class slides and homework related to the topics above – but not including face detection material in today’s slides")
4
Useful Probability “Counting” Relationship Suppose we make n Boolean tests (or draws or predictions) –Each i.i.d. (independent and identically distributed) –P(success) for each trial is p What is the probability of exactly k successes in n tests? P(k in n) = ( ) p k (1-p) (n-k) ( ) = n!/k!(n-k)! – Read “n choose k” – The number of distinct ways to choose k objects from a set of n objects nknk nknk
 –P(success) for each trial is p What is the probability of exactly k successes in n tests. P(k in n) = ( ) p k (1-p) (n-k) ( ) = n!/k!(n-k). – Read n choose k – The number of distinct ways to choose k objects from a set of n objects nknk nknk.")
5
Outline Different types of learning problems Different types of learning algorithms Supervised learning –Decision trees –Naïve Bayes –Perceptrons, Multi-layer Neural Networks –Boosting Applications: learning to detect faces in images

6
Inductive learning Let x represent the input vector of attributes –x j is the ith component of the vector x –value of the jth attribute, j = 1,…d Let f(x) represent the value of the target variable for x –The implicit mapping from x to f(x) is unknown to us –We just have training data pairs, D = {x, f(x)} available We want to learn a mapping from x to f, i.e., h(x; ) is “close” to f(x) for all training data points x are the parameters of our predictor h(..) Examples: –h(x; ) = sign(w 1 x 1 + w 2 x 2 + w 3 ) –h k (x) = (x1 OR x2) AND (x3 OR NOT(x4))
 represent the value of the target variable for x –The implicit mapping from x to f(x) is unknown to us –We just have training data pairs, D = {x, f(x)} available We want to learn a mapping from x to f, i.e., h(x; ) is close to f(x) for all training data points x are the parameters of our predictor h(..) Examples: –h(x; ) = sign(w 1 x 1 + w 2 x 2 + w 3 ) –h k (x) = (x1 OR x2) AND (x3 OR NOT(x4))")
7
Training Data for Supervised Learning

8
True Tree (left) versus Learned Tree (right)
 versus Learned Tree (right)")
9
Classification Problem with Overlap

10
Decision Boundaries Decision Boundary Decision Region 1 Decision Region 2

11
Classification in Euclidean Space A classifier is a partition of the space x into disjoint decision regions –Each region has a label attached –Regions with the same label need not be contiguous –For a new test point, find what decision region it is in, and predict the corresponding label Decision boundaries = boundaries between decision regions –The “dual representation” of decision regions We can characterize a classifier by the equations for its decision boundaries Learning a classifier searching for the decision boundaries that optimize our objective function

12
Example: Decision Trees When applied to real-valued attributes, decision trees produce “axis-parallel” linear decision boundaries Each internal node is a binary threshold of the form x j > t ? converts each real-valued feature into a binary one requires evaluation of N-1 possible threshold locations for N data points, for each real-valued attribute, for each internal node

13
Decision Tree Example Income Debt

14
Decision Tree Example t1 Income Debt Income > t1 ??

15
Decision Tree Example t1 t2 Income Debt Income > t1 Debt > t2 ??

16
Decision Tree Example t1t3 t2 Income Debt Income > t1 Debt > t2 Income > t3

17
Decision Tree Example t1t3 t2 Income Debt Income > t1 Debt > t2 Income > t3 Note: tree boundaries are linear and axis-parallel

18
A Simple Classifier: Minimum Distance Classifier Training –Separate training vectors by class –Compute the mean for each class, k, k = 1,… m Prediction –Compute the closest mean to a test vector x’ (using Euclidean distance) –Predict the corresponding class In the 2-class case, the decision boundary is defined by the locus of the hyperplane that is halfway between the 2 means and is orthogonal to the line connecting them This is a very simple-minded classifier – easy to think of cases where it will not work very well
 –Predict the corresponding class In the 2-class case, the decision boundary is defined by the locus of the hyperplane that is halfway between the 2 means and is orthogonal to the line connecting them This is a very simple-minded classifier – easy to think of cases where it will not work very well")
19
Minimum Distance Classifier

20
Another Example: Nearest Neighbor Classifier The nearest-neighbor classifier –Given a test point x’, compute the distance between x’ and each input data point –Find the closest neighbor in the training data –Assign x’ the class label of this neighbor –(sort of generalizes minimum distance classifier to exemplars) If Euclidean distance is used as the distance measure (the most common choice), the nearest neighbor classifier results in piecewise linear decision boundaries Many extensions –e.g., kNN, vote based on k-nearest neighbors –k can be chosen by cross-validation
 If Euclidean distance is used as the distance measure (the most common choice), the nearest neighbor classifier results in piecewise linear decision boundaries Many extensions –e.g., kNN, vote based on k-nearest neighbors –k can be chosen by cross-validation")
21
Local Decision Boundaries 1 1 1 2 2 2 Feature 1 Feature 2 ? Boundary? Points that are equidistant between points of class 1 and 2 Note: locally the boundary is linear

22
Finding the Decision Boundaries 1 1 1 2 2 2 Feature 1 Feature 2 ?

23
Finding the Decision Boundaries 1 1 1 2 2 2 Feature 1 Feature 2 ?

24
Finding the Decision Boundaries 1 1 1 2 2 2 Feature 1 Feature 2 ?

25
Overall Boundary = Piecewise Linear 1 1 1 2 2 2 Feature 1 Feature 2 ? Decision Region for Class 1 Decision Region for Class 2

26
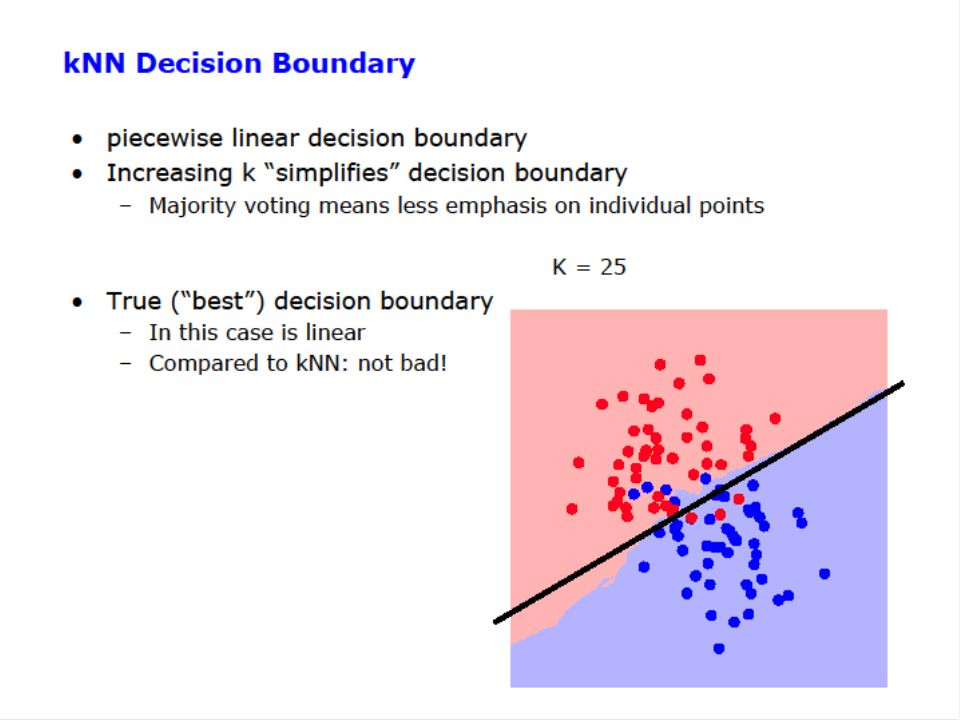
Nearest-Neighbor Boundaries on this data set? Predicts blue Predicts red

30
Linear Classifiers Linear classifier single linear decision boundary (for 2-class case) We can always represent a linear decision boundary by a linear equation: w 1 x 1 + w 2 x 2 + … + w d x d = w j x j = w t x = 0 In d dimensions, this defines a (d-1) dimensional hyperplane –d=3, we get a plane; d=2, we get a line For prediction we simply see if w j x j > 0 The w i are the weights (parameters) –Learning consists of searching in the d-dimensional weight space for the set of weights (the linear boundary) that minimizes an error measure –A threshold can be introduced by a “dummy” feature that is always one; it weight corresponds to (the negative of) the threshold Note that a minimum distance classifier is a special (restricted) case of a linear classifier
 We can always represent a linear decision boundary by a linear equation: w 1 x 1 + w 2 x 2 + … + w d x d = w j x j = w t x = 0 In d dimensions, this defines a (d-1) dimensional hyperplane –d=3, we get a plane; d=2, we get a line For prediction we simply see if w j x j > 0 The w i are the weights (parameters) –Learning consists of searching in the d-dimensional weight space for the set of weights (the linear boundary) that minimizes an error measure –A threshold can be introduced by a dummy feature that is always one; it weight corresponds to (the negative of) the threshold Note that a minimum distance classifier is a special (restricted) case of a linear classifier")
34
The Perceptron Classifier (pages 740-743 in text) The perceptron classifier is just another name for a linear classifier for 2-class data, i.e., output(x) = sign( w j x j ) Loosely motivated by a simple model of how neurons fire For mathematical convenience, class labels are +1 for one class and -1 for the other Two major types of algorithms for training perceptrons –Objective function = classification accuracy (“error correcting”) –Objective function = squared error (use gradient descent) –Gradient descent is generally faster and more efficient – but there is a problem! No gradient!

35
The Sigmoid Function Sigmoid function is defined as [ f ] = [ 2 / ( 1 + exp[- f ] ) ] - 1 Derivative of sigmoid f [ f ] =.5 * ( [f]+1 ) * ( 1-[f] ) f f)
![The Sigmoid Function Sigmoid function is defined as [ f ] = [ 2 / ( 1 + exp[- f ] ) ] - 1 Derivative of sigmoid f [ f ] =.5 * ( [f]+1 ) * ( 1-[f] ) f f)](http://images.slideplayer.com/31/9763491/slides/slide_35.jpg "The Sigmoid Function Sigmoid function is defined as [ f ] = [ 2 / ( 1 + exp[- f ] ) ] - 1 Derivative of sigmoid f [ f ] =.5 * ( [f]+1 ) * ( 1-[f] ) f f)")
36
Two different types of perceptron output o(f) f x-axis below is f(x) = f = weighted sum of inputs y-axis is the perceptron output f) Thresholded output, takes values +1 or -1 Sigmoid output, takes real values between -1 and +1 The sigmoid is in effect an approximation to the threshold function above, but has a gradient that we can use for learning f
 f x-axis below is f(x) = f = weighted sum of inputs y-axis is the perceptron output f) Thresholded output, takes values +1 or -1 Sigmoid output, takes real values between -1 and +1 The sigmoid is in effect an approximation to the threshold function above, but has a gradient that we can use for learning f")
37
Squared Error for Perceptron with Sigmoidal Output Squared error = E[w] = i [ (f[x(i)]) - y(i) ] 2 where x(i) is the ith input vector in the training data, i=1,..N y(i) is the ith target value (-1 or 1) f[x(i)] = w j x j is the weighted sum of inputs (f[x(i)]) is the sigmoid of the weighted sum Note that everything is fixed (once we have the training data) except for the weights w So we want to minimize E[w] as a function of w
![Squared Error for Perceptron with Sigmoidal Output Squared error = E[w] = i [ (f[x(i)]) - y(i) ] 2 where x(i) is the ith input vector in the training data, i=1,..N y(i) is the ith target value (-1 or 1) f[x(i)] = w j x j is the weighted sum of inputs (f[x(i)]) is the sigmoid of the weighted sum Note that everything is fixed (once we have the training data) except for the weights w So we want to minimize E[w] as a function of w](http://images.slideplayer.com/31/9763491/slides/slide_37.jpg "Squared Error for Perceptron with Sigmoidal Output Squared error = E[w] = i [ (f[x(i)]) - y(i) ] 2 where x(i) is the ith input vector in the training data, i=1,..N y(i) is the ith target value (-1 or 1) f[x(i)] = w j x j is the weighted sum of inputs (f[x(i)]) is the sigmoid of the weighted sum Note that everything is fixed (once we have the training data) except for the weights w So we want to minimize E[w] as a function of w")
38
Gradient Descent Learning of Weights Gradient Descent Rule: w new = w old - ( E[w] ) where (E[w]) is the gradient of the error function E wrt weights, and is the learning rate (small, positive) Notes: 1. This moves us downhill in direction ( E [ w ] ) (steepest downhill) 2. How far we go is determined by the value of
![Gradient Descent Learning of Weights Gradient Descent Rule: w new = w old - ( E[w] ) where (E[w]) is the gradient of the error function E wrt weights, and is the learning rate (small, positive) Notes: 1.](http://images.slideplayer.com/31/9763491/slides/slide_38.jpg "This moves us downhill in direction ( E [ w ] ) (steepest downhill) 2. How far we go is determined by the value of .")
39
Gradient Descent Update Equation From basic calculus, for perceptron with sigmoid, and squared error objective function, gradient for a single input x(i) is ( E[w] ) = - ( y(i) – [f(i)] ) [f(i)] x j (i) Gradient descent weight update rule: w j = w j + ( y(i) – [f(i)] ) [f(i)] x j (i) – can rewrite as: w j = w j + * error * c * x j (i)
![Gradient Descent Update Equation From basic calculus, for perceptron with sigmoid, and squared error objective function, gradient for a single input x(i) is ( E[w] ) = - ( y(i) – [f(i)] ) [f(i)] x j (i) Gradient descent weight update rule: w j = w j + ( y(i) – [f(i)] ) [f(i)] x j (i) – can rewrite as: w j = w j + * error * c * x j (i)](http://images.slideplayer.com/31/9763491/slides/slide_39.jpg "Gradient Descent Update Equation From basic calculus, for perceptron with sigmoid, and squared error objective function, gradient for a single input x(i) is ( E[w] ) = - ( y(i) – [f(i)] ) [f(i)] x j (i) Gradient descent weight update rule: w j = w j + ( y(i) – [f(i)] ) [f(i)] x j (i) – can rewrite as: w j = w j + * error * c * x j (i)")
40
Pseudo-code for Perceptron Training Inputs: N features, N targets (class labels), learning rate Outputs: a set of learned weights Initialize each w j (e.g.,randomly) While (termination condition not satisfied) for i = 1: N % loop over data points (an iteration) for j= 1 : d % loop over weights deltawj = ( y(i) – [f(i)] ) [f(i)] x j (i) w j = w j + deltawj end calculate termination condition end
![Pseudo-code for Perceptron Training Inputs: N features, N targets (class labels), learning rate Outputs: a set of learned weights Initialize each w j (e.g.,randomly) While (termination condition not satisfied) for i = 1: N % loop over data points (an iteration) for j= 1 : d % loop over weights deltawj = ( y(i) – [f(i)] ) [f(i)] x j (i) w j = w j + deltawj end calculate termination condition end](http://images.slideplayer.com/31/9763491/slides/slide_40.jpg "Pseudo-code for Perceptron Training Inputs: N features, N targets (class labels), learning rate Outputs: a set of learned weights Initialize each w j (e.g.,randomly) While (termination condition not satisfied) for i = 1: N % loop over data points (an iteration) for j= 1 : d % loop over weights deltawj = ( y(i) – [f(i)] ) [f(i)] x j (i) w j = w j + deltawj end calculate termination condition end")
41
Comments on Perceptron Learning Iteration = one pass through all of the data Algorithm presented = incremental gradient descent –Weights are updated after visiting each input example –Alternatives Batch: update weights after each iteration (typically slower) Stochastic: randomly select examples and then do weight updates Rate of convergence –E[w] is convex as a function of w, so no local minima –So convergence is guaranteed as long as learning rate is small enough But if we make it too small, learning will be *very* slow –But if learning rate is too large, we move further, but can overshoot the solution and oscillate, and not converge at all
![Comments on Perceptron Learning Iteration = one pass through all of the data Algorithm presented = incremental gradient descent –Weights are updated after visiting each input example –Alternatives Batch: update weights after each iteration (typically slower) Stochastic: randomly select examples and then do weight updates Rate of convergence –E[w] is convex as a function of w, so no local minima –So convergence is guaranteed as long as learning rate is small enough But if we make it too small, learning will be *very* slow –But if learning rate is too large, we move further, but can overshoot the solution and oscillate, and not converge at all](http://images.slideplayer.com/31/9763491/slides/slide_41.jpg "Comments on Perceptron Learning Iteration = one pass through all of the data Algorithm presented = incremental gradient descent –Weights are updated after visiting each input example –Alternatives Batch: update weights after each iteration (typically slower) Stochastic: randomly select examples and then do weight updates Rate of convergence –E[w] is convex as a function of w, so no local minima –So convergence is guaranteed as long as learning rate is small enough But if we make it too small, learning will be *very* slow –But if learning rate is too large, we move further, but can overshoot the solution and oscillate, and not converge at all")
42
Multi-Layer Perceptrons (p744-747 in text) What if we took K perceptrons and trained them in parallel and then took a weighted sum of their sigmoidal outputs? –This is a multi-layer neural network with a single “hidden” layer (the outputs of the first set of perceptrons) –If we train them jointly in parallel, then intuitively different perceptrons could learn different parts of the solution Mathematically, they define different local decision boundaries in the input space, giving us a more powerful model How would we train such a model? –Backpropagation algorithm = clever way to do gradient descent –Bad news: many local minima and many parameters training is hard and slow –Neural networks generated much excitement in AI research in the late 1980’s and 1990’s But now techniques like boosting and support vector machines are often preferred
 –If we train them jointly in parallel, then intuitively different perceptrons could learn different parts of the solution Mathematically, they define different local decision boundaries in the input space, giving us a more powerful model How would we train such a model. –Backpropagation algorithm = clever way to do gradient descent –Bad news: many local minima and many parameters training is hard and slow –Neural networks generated much excitement in AI research in the late 1980’s and 1990’s But now techniques like boosting and support vector machines are often preferred.")
43
Naïve Bayes Model (p718 in text) Y1Y1 Y2Y2 Y3Y3 C YnYn P(C | Y 1,…Y n ) = P(Y i | C) P (C) Features Y are conditionally independent given the class variable C Widely used in machine learning e.g., spam email classification: Y’s = counts of words in emails Conditional probabilities P(Yi | C) can easily be estimated from labeled data Problem: Need to avoid zeroes, e.g., from limited training data Solutions: Pseudo-counts, beta[a,b] distribution, etc.
![Naïve Bayes Model (p718 in text) Y1Y1 Y2Y2 Y3Y3 C YnYn P(C | Y 1,…Y n ) = P(Y i | C) P (C) Features Y are conditionally independent given the class variable C Widely used in machine learning e.g., spam classification: Y’s = counts of words in s Conditional probabilities P(Yi | C) can easily be estimated from labeled data Problem: Need to avoid zeroes, e.g., from limited training data Solutions: Pseudo-counts, beta[a,b] distribution, etc.](http://images.slideplayer.com/31/9763491/slides/slide_43.jpg "Naïve Bayes Model (p718 in text) Y1Y1 Y2Y2 Y3Y3 C YnYn P(C | Y 1,…Y n ) = P(Y i | C) P (C) Features Y are conditionally independent given the class variable C Widely used in machine learning e.g., spam classification: Y’s = counts of words in s Conditional probabilities P(Yi | C) can easily be estimated from labeled data Problem: Need to avoid zeroes, e.g., from limited training data Solutions: Pseudo-counts, beta[a,b] distribution, etc.")
44
Learning to Detect Faces A Large-Scale Application of Machine Learning (This material is not in the text: for further information see the paper by P. Viola and M. Jones, International Journal of Computer Vision, 2004

45
Viola-Jones Face Detection Algorithm Overview : –Viola Jones technique overview –Features –Integral Images –Feature Extraction –Weak Classifiers –Boosting and classifier evaluation –Cascade of boosted classifiers –Example Results

46
Viola Jones Technique Overview Three major contributions/phases of the algorithm : –Feature extraction –Learning using boosting and decision stumps –Multi-scale detection algorithm Feature extraction and feature evaluation. –Rectangular features are used, with a new image representation their calculation is very fast. Classifier learning using a method called boosting A combination of simple classifiers is very effective

47
Features Four basic types. –They are easy to calculate. –The white areas are subtracted from the black ones. –A special representation of the sample called the integral image makes feature extraction faster.

48
Integral images Summed area tables A representation that means any rectangle’s values can be calculated in four accesses of the integral image.

49
Fast Computation of Pixel Sums

50
Feature Extraction Features are extracted from sub windows of a sample image. –The base size for a sub window is 24 by 24 pixels. –Each of the four feature types are scaled and shifted across all possible combinations In a 24 pixel by 24 pixel sub window there are ~160,000 possible features to be calculated.

51
Learning with many features We have 160,000 features – how can we learn a classifier with only a few hundred training examples without overfitting? Idea: –Learn a single very simple classifier (a “weak classifier”) –Classify the data –Look at where it makes errors –Reweight the data so that the inputs where we made errors get higher weight in the learning process –Now learn a 2 nd simple classifier on the weighted data –Combine the 1 st and 2 nd classifier and weight the data according to where they make errors –Learn a 3 rd classifier on the weighted data –… and so on until we learn T simple classifiers –Final classifier is the combination of all T classifiers –This procedure is called “Boosting” – works very well in practice.
 –Classify the data –Look at where it makes errors –Reweight the data so that the inputs where we made errors get higher weight in the learning process –Now learn a 2 nd simple classifier on the weighted data –Combine the 1 st and 2 nd classifier and weight the data according to where they make errors –Learn a 3 rd classifier on the weighted data –… and so on until we learn T simple classifiers –Final classifier is the combination of all T classifiers –This procedure is called Boosting – works very well in practice..")
52
“Decision Stumps” Decision stumps = decision tree with only a single root node –Certainly a very weak learner! –Say the attributes are real-valued –Decision stump algorithm looks at all possible thresholds for each attribute –Selects the one with the max information gain –Resulting classifier is a simple threshold on a single feature Outputs a +1 if the attribute is above a certain threshold Outputs a -1 if the attribute is below the threshold –Note: can restrict the search for to the n-1 “midpoint” locations between a sorted list of attribute values for each feature. So complexity is n log n per attribute. –Note this is exactly equivalent to learning a perceptron with a single intercept term (so we could also learn these stumps via gradient descent and mean squared error)
.")
53
Boosting Example

54
First classifier

55
First 2 classifiers

56
First 3 classifiers

57
Final Classifier learned by Boosting

59
Boosting with Decision Stumps Viola-Jones algorithm –With K attributes (e.g., K = 160,000) we have 160,000 different decision stumps to choose from –At each stage of boosting given reweighted data from previous stage Train all K (160,000) single-feature perceptrons Select the single best classifier at this stage Combine it with the other previously selected classifiers Reweight the data Learn all K classifiers again, select the best, combine, reweight Repeat until you have T classifiers selected –Very computationally intensive Learning K decision stumps T times E.g., K = 160,000 and T = 1000
 we have 160,000 different decision stumps to choose from –At each stage of boosting given reweighted data from previous stage Train all K (160,000) single-feature perceptrons Select the single best classifier at this stage Combine it with the other previously selected classifiers Reweight the data Learn all K classifiers again, select the best, combine, reweight Repeat until you have T classifiers selected –Very computationally intensive Learning K decision stumps T times E.g., K = 160,000 and T = 1000")
60
How is classifier combining done? At each stage we select the best classifier on the current iteration and combine it with the set of classifiers learned so far How are the classifiers combined? –Take the weight*feature for each classifier, sum these up, and compare to a threshold (very simple) –Boosting algorithm automatically provides the appropriate weight for each classifier and the threshold –This version of boosting is known as the AdaBoost algorithm –Some nice mathematical theory shows that it is in fact a very powerful machine learning technique
 –Boosting algorithm automatically provides the appropriate weight for each classifier and the threshold –This version of boosting is known as the AdaBoost algorithm –Some nice mathematical theory shows that it is in fact a very powerful machine learning technique.")
61
Reduction in Error as Boosting adds Classifiers

62
Useful Features Learned by Boosting

63
A Cascade of Classifiers

64
Detection in Real Images Basic classifier operates on 24 x 24 subwindows Scaling: –Scale the detector (rather than the images) –Features can easily be evaluated at any scale –Scale by factors of 1.25 Location: –Move detector around the image (e.g., 1 pixel increments) Final Detections –A real face may result in multiple nearby detections –Postprocess detected subwindows to combine overlapping detections into a single detection
 –Features can easily be evaluated at any scale –Scale by factors of 1.25 Location: –Move detector around the image (e.g., 1 pixel increments) Final Detections –A real face may result in multiple nearby detections –Postprocess detected subwindows to combine overlapping detections into a single detection")
65
Training Examples of 24x24 images with faces

66
Small set of 111 Training Images

67
Sample results using the Viola-Jones Detector Notice detection at multiple scales

68
More Detection Examples

69
Practical implementation Details discussed in Viola-Jones paper Training time = weeks (with 5k faces and 9.5k non-faces) Final detector has 38 layers in the cascade, 6060 features 700 Mhz processor: –Can process a 384 x 288 image in 0.067 seconds (in 2003 when paper was written)
 Final detector has 38 layers in the cascade, 6060 features 700 Mhz processor: –Can process a 384 x 288 image in seconds (in 2003 when paper was written)")
70
Summary Learning –Given a training data set, a class of models, and an error function, this is essentially a search or optimization problem Different approaches to learning –Divide-and-conquer: decision trees –Global decision boundary learning: perceptrons –Constructing classifiers incrementally: boosting Learning to recognize faces –Viola-Jones algorithm: state-of-the-art face detector, entirely learned from data, using boosting+decision-stumps

Similar presentations









>")











 Learning Vector Quantization (SOM) Self Organizing Maps.>")




