Download presentation
Presentation is loading. Please wait.

1
Part of Speech Tagging in Context month day, year Alex Cheng alcheng@microsoft.com Ling 575 Winter 08 Michele Banko, Robert Moore

2
Overview Comparison of previous methods Using context from both sides Lexicon Construction Sequential EM for tag sequence and lexical probabilities Discussion Questions

3
Previous methods Trigram model P(t_i | t_i-1, t_i-2) Kupiec(1992) divide lexicon into word classes –Words contained within the same equivalence classes posses the same set of POS Brill(1995) UTBL –Uses information from the distribution of unambiguously tagged data to make label decision –Considers both left and right context
 Kupiec(1992) divide lexicon into word classes –Words contained within the same equivalence classes posses the same set of POS Brill(1995) UTBL –Uses information from the distribution of unambiguously tagged data to make label decision –Considers both left and right context")
4
Toutanova (2003) Conditional MM –Supervised learning method –Increase accuracy from 96.10% to 96.55% Lafferty (2001) –Compared HMM with MEMM, and CRF
 Conditional MM –Supervised learning method –Increase accuracy from 96.10% to 96.55% Lafferty (2001) –Compared HMM with MEMM, and CRF")
5
Contextualized HMM Estimate the probability of a word w_i based on t_i-1, t_i and t_i+1 Leads to higher dimensionality in the parameters Standard absolute discounting scheme smoothing

6
Lexicon construction Lexicons provided for both testing and training Initialize with uniform dist for all possible tags for each word Experiments with using word classes in the Kupiec model

7
Problems Limiting the possible tags per lexicon –Tags that appeared less than X% of the time for each word are omitted.

9
HMM Model Training Extracting non-ambiguous tag sequence –Use these n-grams and their counts to bias the initial estimate of state transitions in the HMM Sequential training –Train the transition model probability first, keeping the lexical probabilities constant. –Then train the lexical probabilities, keeping the transition probability constant.

10
Discussion Sequential training of HMM by training the parameters separately. Is there any theoretical significance? Computational cost? What are the effects if we model the tag context differently using p(t_i | t_i- 1, t_i+1)?
 .")
11
Improved Estimation for Unsupervised POS Tagging month day, year Alex Cheng alcheng@microsoft.com Ling 575 Winter 08 Qin Iris Wang, Dale Schuurmans

12
Overview Focus on parameter estimation –Considering only simple models with limited context (using a standard HMM - bigram) Constraint on marginal tag probabilities Smooth lexical parameters using word similarities Discussion Questions
 Constraint on marginal tag probabilities Smooth lexical parameters using word similarities Discussion Questions")
13
Parameter Estimation Banko and Moore (2004) reduces error rate from 22.8% to 4.1% by reducing the set of possible tags for each word. –Requires tagged data to find the artificially reduced lexicon. EM is guaranteed to converge to a local maximum. HMM tends to have multiple local maxima. –This leads to the resulting quality of the parameters may have more to do with the initial parameter estimation than the EM procedure itself.

14
Estimations problems Using the standard model –Tag -> tag unifrom over all tags –Tag -> word uniform over all possible tag for word (as specified in complete lexicon) Estimated parameters of the transition probabilities are quite poor. –‘a’ is always tagged LS. Estimated parameters of the lexical probabilities are also quite poor –Treat each parameter b_t_w1, b_t_w2 as independent. –EM tends to over-fit the lexical model and ignore similarity between words.

15
Marginally Constrained HMMs Tag -> Tag probabilities Maintain a specific marginal distribution over the tag probabilities. –Assuming we are given a target distribution over tags (raw tag frequency) Can be obtained from tagged data Can be approximated (see Toutanova, 2003)
 Can be obtained from tagged data Can be approximated (see Toutanova, 2003).")
16
Similarity based Smoothing Tag -> Word probabilities Using a feature vector f for each word w which consists of the context (left and right word) of w. Took 100,000 most frequent words as features

17
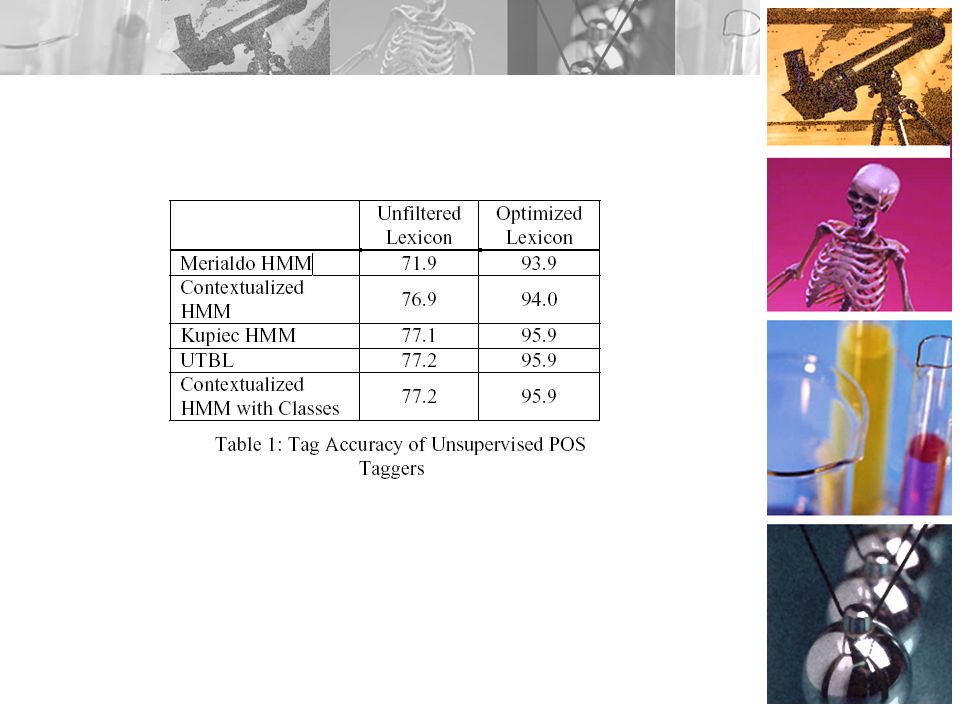
Result

18
Discussion Compared to Banko and Moore, are methods used here “more or less” unsupervised? –Banko and Moore uses lexicon ablation –Here, we use raw frequency of tags

Similar presentations
 Compute maximum probability tag sequence: arg max T 1,N P m (T 1,N | W 1,N ) Compute.>")

 language modeling – evaluate alternative texts and models P m (W 1,N ) 2.Compute.>")

 Slides are based on Introduction to Information Retrieval Book by Manning, Raghavan and Schütze.>")




>")



 Speech and Language Processing, Ch 8 R Dale et al (2000) Handbook of Natural Language Processing,>")





