Download presentation
Presentation is loading. Please wait.

1
1 Topic 2 – Simple Linear Regression KKNR Chapters 4 – 7

2
2 Overview Regression Models; Scatter Plots SAS GPLOT Procedure Estimation and Inference in SLR SAS REG Procedure ANOVA Table & Coefficient of Determination (R 2 )
")
3
3 Simple Linear Regression Model We take n pairs of observations The goal is to find a model that best fits with the data. Model will be linear in terms of the parameters (betas). These won’t appear in exponents or anything unusual. Allowed to be nonlinear in terms of predictor variables (we may transform these somewhat freely). We may also transform the response.
. These won’t appear in exponents or anything unusual. Allowed to be nonlinear in terms of predictor variables (we may transform these somewhat freely). We may also transform the response..")
4
4 Simple Linear Regression Model (2) Some sample models Notice the betas always function in the same way, and the analysis will always proceed in the same way too (after we make whatever transformations we might need).
 Some sample models Notice the betas always function in the same way, and the analysis will always proceed in the same way too (after we make whatever transformations we might need).")
5
5 Simple Linear Regression Model (3) Key question: How do you decide on the “best” form for the model? Always view a scatter plot (use PROC GPLOT in SAS). Curvature in the plot will help you determine the need for a transformation on either X or Y. Always consider residual plots. Some patterns in these plots will also indicate the need for transformation (more on this later).
. Curvature in the plot will help you determine the need for a transformation on either X or Y. Always consider residual plots. Some patterns in these plots will also indicate the need for transformation (more on this later)..")
6
6 Scatter Plot Approach If you can look at a scatter plot and the data “look linear”, then likely no transformation is necessary. Try not to look for things that are not there. If you see curvature, then some transformation may be appropriate: Use scientific theory & experience Try transformations you think may work – look at scatter plots of the transformed data to assess whether they do work.

7
7 Finding the “Best” Model There is no “absolute” strategy. Some common mistakes (why are these bad?): Try several different methods and simply take the one for which you get the best results (e.g. highest R 2 ) Over-fit the model by including lots of extra terms (e.g. squares, cubes, etc.) in hopes to get the curve to go through all of the data points (note that this would be MLR)
: Try several different methods and simply take the one for which you get the best results (e.g. highest R 2 ) Over-fit the model by including lots of extra terms (e.g. squares, cubes, etc.) in hopes to get the curve to go through all of the data points (note that this would be MLR).")
8
8 Collaborative Learning Activity CLG #2.1-2.3 First, make sure you read enough to understand the dataset we will be considering. Then, please try to answer these questions related to scatter plots.

9
9 Scatter Plot Examples (1)
")
10
10 Scatter Plot Examples (2)
")
11
11 Scatter Plot Examples (3)
")
12
12 Scatter Plot Examples (4)
")
13
13 Comments on GPLOT Utilize SYMBOL, AXIS, and TITLE statements to make your plots look nice. ORFONT provides a good symbol-set. You can also manipulate the COLOR of symbols in order help the viewer differentiate groups. Be careful to remember that SAS reuses these statements, so you will need to redefine them as necessary.

14
14 SAS ORFONT

15
15 Fitting the SLR Model Once we decide on the form of our model, we need to estimate the parameters that yield the “best” fit. The arithmetic involved is accomplished with a computer, but it is useful to have some understanding of the how the estimates are calculated.

16
16 The SLR Model Whatever the transformations may be, our model is in the form of a straight line: Epsilon represents the inherent variation (or error) in the model. Model involves two other parameters (unknown, but fixed in value): slope (change in y for a one unit change in x) intercept (value of y for x = 0; usually not particularly interested in this)
: slope (change in y for a one unit change in x) intercept (value of y for x = 0; usually not particularly interested in this).")
17
17 Observations An observation Y at a particular X is a random variable. So you can think of each observation as having been drawn from a normal distribution centered at and having standard deviation. Be careful to remember that these parameters (represented by greek letters) are fixed – but can never be known exactly. We can only estimate them.
 are fixed – but can never be known exactly. We can only estimate them..")
18
18 Graphical Representation

19
19 Model Assumptions We make three assumptions on the error term in our model. A simple statement of these assumptions is that The assumptions on the errors apply to both regression and ANOVA and we will be assuming these throughout the course. For regression, we also make a 4 th assumption that our model (in this case linear relationship between X and Y) is appropriate.
 is appropriate..")
20
20 Assumptions on Errors Constance Variance (Homoscedasticity) – the variance associated to the error is the same for ANY value of X. Normality – the errors follow a normal distribution with a mean of zero. Independence – the errors (and hence also the responses) are statistically independent of each other.
 are statistically independent of each other..")
21
21 Checking Your Assumptions Reminder: We can never know the exact values of the errors because we can never know the true regression equation. We can (and will) estimate the errors by the residuals. The residuals can then be used (mostly in graphical analyses) to assess the assumptions – giving us some idea of whether the assumptions of our model are satisfied. More on this later...
 estimate the errors by the residuals. The residuals can then be used (mostly in graphical analyses) to assess the assumptions – giving us some idea of whether the assumptions of our model are satisfied. More on this later....")
22
22 Estimation of the “Best” Line We want to obtain estimates of the parameters and (remember, we can never know them exactly). Notation: Generally, I will use lower case English letters to represent estimates for parameters. You may also see hat-notation. For example, if is a parameter, would be its estimated value from data. Our estimates will be denoted. The residuals will be denoted by.

23
23 Parameter Estimates Key Point: Parameters are fixed, but their estimates are random variables. If we take a different sample, we’ll get a different estimate. Thus all of the estimates we compute will have associated standard errors that we may also estimate. The method of least squares is used to obtain both parameter estimates and standard errors. This method is desirable because the estimates are unbiased, minimum variance estimates.

24
24 Least-squares Method The least squares method obtains the estimated regression line that minimizes the sum of the squared residuals (also called the SSE or sum of squares error). Another way to think of this is that the least squares estimates allow us to explain as much of the variation in Y as we possibly can using X as a predictor. The SSR (sums of squares due to our model) is maximized.
 is maximized..")
25
25 Least Squares Estimates The estimates have formulas in terms of the data:

26
26 Least Squares Estimates (2) It is not important to memorize these formulas. I won’t ask you to calculate a parameter estimate by hand from the data. We have computers for this. What is important will be to understand that, because the Y i are random variables, and because all of these estimates depend on the Y i, the estimates themselves will also be random variables. Thus we may estimate their standard errors, develop confidence intervals, and draw statistical inferences.

27
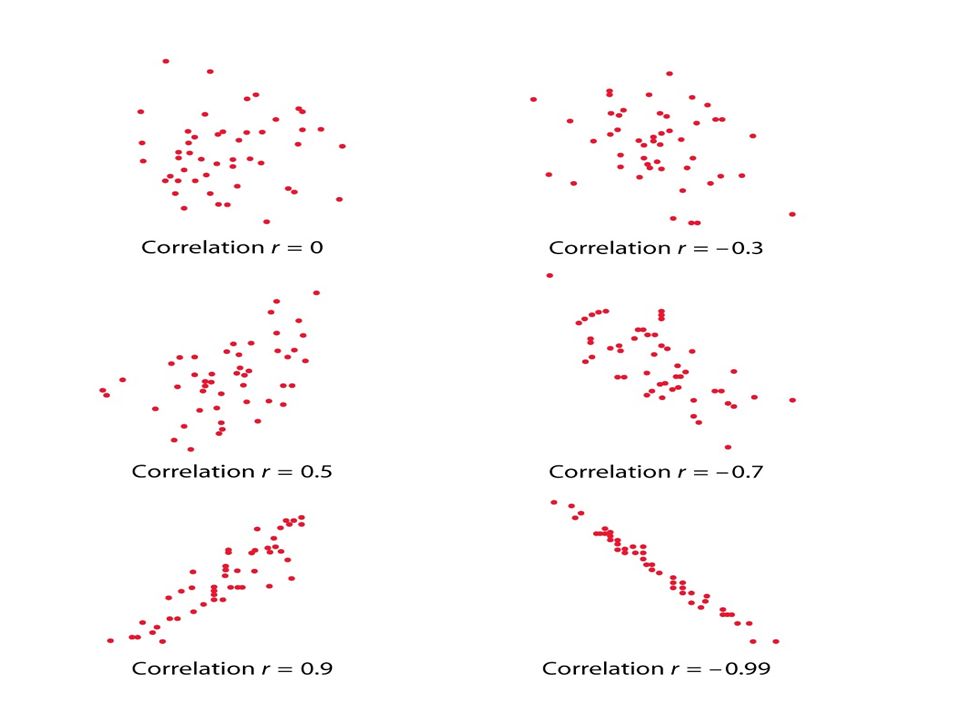
27 Inference about the Slope A non-zero slope implies a linear association between the predictor and response. In some experimental cases the relationship may be causal as well. Thus statistical inference for the slope is quite important.

28
28 Inference About the Slope The first thing to remember is that b 1 is a random variable. In order to do inference, we must first consider that... is normally distributed (why?) The standard error associated to b 1 is
 The standard error associated to b 1 is.")
29
29 Slope Inference (2) For testing, the statistic has a t-distribution with n – 2 degrees of freedom when the null hypothesis is true. A two-sided confidence interval for the slope will be:

30
30 Slope Inference (3) Want to determine: Does X help explain Y through a linear model???? If we reject the null hypothesis, then we may conclude that there is a linear association between X and Y Must have assumptions satisfied. Key point: Failing to reject does not necessarily allow us to conclude that X is unimportant Maybe we need a bigger sample to give better power

31
31 Slope Inference (4) Another Key Point: Violations of the model assumptions may invalidate the significance test. In particular, if there is a nonlinear association or some type of dependence issue, the SLR model should not be used. See pages 65 for some pictures illustrating this.

32
32 Experimental Control In some situations you have experimental control over your predictor variable. Thus you have some control over the SE for the slope: Making SSX large will decrease the SE of your estimate for the slope. Do this by spreading you chosen X values further apart. Increasing n (and hence increasing degrees of freedom) may also help to decrease the SE.
 may also help to decrease the SE..")
33
33 Inference About the Intercept Hypothesis tests and confidence intervals may be constructed similar to inference for the slope. See page 63. Key point: Unless the observed predictor is often in the neighborhood of zero, we have no reason to be interested in the intercept. In fact, the intercept will usually just be an artifact of the model. And if the scope of the model does not include zero, there is no reason to even worry whether the value of b 0 makes sense.

34
34 Further Inference Confidence Intervals for the Mean Response Prediction Intervals

35
35 The Predicted Value The line describes the mean population response for each value of the predictor. If an association exists, then the mean response depends on the value of X. The predicted value of Y at a given X = x 0 is Reminder: Notation may differ some from the text – I try to keep our notation as simple as possible.

36
36 C.I. for the Mean Response or Prediction Interval? If you are trying to predict for a group C.I. for the Mean Response Example: Trying to predict the average blood pressure for all 40 year olds Interval is usually narrower If you are trying to predict for a single observation Prediction Interval Example: Trying to predict the blood pressure for a single 40 year old Interval is usually much wider because of individual variation Some 40 year olds will have much higher or lower B.P.s

37
37 *Calculations of SE for Mean Response First step is to write in terms of estimates. We also need to use a small trick to avoid worrying about a covariance between the two parameter estimates.

38
38 * Calculations of SE for Mean Response (2) We know the variances for Y-bar and b 1. And it turns out that, even though Y-bar is used in the calculation of b 1, the two are still independent. So the variance of the sum is the sum of the variances:

39
39 SE for the Mean Response The mean response is a random variable since b 0 and b 1 are random. Hence it will have a standard error. It is good to have some understanding of how this works, so we will look very briefly at the calculations (you should just try to follow them, but not worry about memorizing them)
.")
40
40 Confidence Intervals for Mean Response You sometimes want to get confidence intervals for the mean response. Because we have estimated both the mean and variance, the t-distribution applies ( n – 2 degrees of freedom). The CI for a given value of X is:
. The CI for a given value of X is:.")
41
41 SE for the Prediction Interval So the prediction variance is the sum of these two components:

42
42 Prediction Intervals (1) Now consider predicting a new observation at X = x 0. Our point estimate for this would just be the point on the regression line,. Our prediction interval will be of the same form as for the mean response, but with a different standard error:

43
43 Why the difference for the Prediction Interval? The key to understanding the standard error for prediction is to understand the random components involved. (1) The regular variance associated to getting a predicted value (same as the CI mean response error) (2) The individual error for a single observation It basically gives us an extra σ 2 piece Think of the NORMAL DISTRIBUTION centered around the regression line (see slide 18)
 The regular variance associated to getting a predicted value (same as the CI mean response error) (2) The individual error for a single observation It basically gives us an extra σ 2 piece Think of the NORMAL DISTRIBUTION centered around the regression line (see slide 18).")
44
44 Multiple Confidence Intervals We did intervals for 40 year olds, both group and individual, what about 30? 35? Getting multiple CI’s presents a similar problem to multiple hypothesis tests. We would expect one errant CI for every 20 CI’s that we obtain at 95% confidence. Thus some adjustment may need to be made. Bonferroni is too conservative here, because these CI’s are actually dependent and it is possible to take advantage of this.

45
45 Confidence Bands The solution is to change our critical value. Instead of using T, we use a critical value related to the F distribution: This allows us to produce CI’s for the mean response at any and all possible values for the predictor variable. Hence we may also use this to draw confidence bands around the regression line. Useful trick: For significance level 0.05, the value of W is approximately 0.6 more than the value of T. This is slightly conservative, but simplifies computation.

46
46 Interpolation vs. Extrapolation Interpolation ( x 0 within the domain of the observed X’s) is generally ok if the assumptions are satisfied. Extrapolation ( x 0 outside the domain of the observed X’s) is usually a bad idea. No assurance that linearity continues outside the observed domain. Example – Height regressed on age in children.
 is generally ok if the assumptions are satisfied. Extrapolation ( x 0 outside the domain of the observed X’s) is usually a bad idea. No assurance that linearity continues outside the observed domain. Example – Height regressed on age in children..")
47
47 Key Concepts The standard error formulas for the slope, the regression line, and prediction are related – your goal should be to understand these relationships. You should also be able to construct CI’s and do hypothesis tests. Point Estimates Critical Values (know how to look these up) Standard Errors (generally would not be asked to compute these, just use them)
 Standard Errors (generally would not be asked to compute these, just use them).")
48
48 SAS Review

49
49 Collaborative Learning Activity Please complete problems 2.4 (constructing CI’s) and 2.5 (interpreting regression output) on the handout.
 and 2.5 (interpreting regression output) on the handout.")
50
50 Output: ANOVA Table

51
51 Output: Parameter Estimates

52
52 Output: Output Statistics

53
53 ANOVA Table ANOVA stands for analysis of variance. We use an ANOVA table in regression to organize our estimates of different components of variation. It is important to understand how this works for SLR since we will use ANOVA tables for MLR and ANOVA procedures as well.

54
54 ANOVA Table Table consists of variance estimates used to assess the following two questions: Is there an linear association between the response and predictor(s)? How “strong” is that linear association? We need to start by understanding the different components of variation for a single data point.

55
55 Components of Variation

56
56 Combining Over All Data We might look at the total deviation as follows: But we cannot simply add deviations across data points. Why? Options?

57
57 Combining Over All Data (2) Squared deviations are chosen because it turns out that they can be used to estimate variances. It also (conveniently) turns out that:
 turns out that:.")
58
58 Sums of Squares The total sums of squares (SST) represents the total available variation that could be explained by the predictor (that not already explained by Ybar). We break this into the two components: Model/Regression sums of squares (SSR) is the part that is explained by the predictor. Error sums of squares (SSE) is the part that is still left unexplained.
 is the part that is explained by the predictor. Error sums of squares (SSE) is the part that is still left unexplained..")
59
59 Degrees of Freedom Each SS has an associated degrees of freedom. For simple linear regression, DF T = n – 1 DF R = 1 DF E = n – 2 Always have In general, you lose one degree of freedom for each parameter you estimate. Since we estimate Ybar before we start, df TOT is n – 1.

60
60 Degrees of Freedom (2) It is important to understand how DF are assigned with the models that we will be discussing. Some key principles: DF Total is always 1 less than the number of observations. You should next determine DF for the model. For regression, each continuous variable requires a slope estimate and takes 1 DF. Lastly, the error DF is determined by subtraction (avoid memorization of formulas).
..")
61
61 Mean Squares A mean square is a SS divided by its associated degrees of freedom. These are the actual variance estimates:

62
62 F-tests Because both MSR and MSE estimate under the null hypothesis, we may utilize their ratio in order to test whether there is a linear association. If the null hypothesis is true, the statistic will have an F distribution with 1 and n – 2 DF. Note: To get your DF for the F-test, simply use the DF for the associated mean squares.

63
63 Relationship of F to T For SLR the F test is identical to the t-test for the slope as in fact: Additionally you will find that in terms of critical values,.

64
64 Example

65
65 Example (2) For SLR, the F-test in ANOVA Table is exactly the same as the test for zero slope. Note 8.13 = (-2.85) 2. Caution: When we get into multiple regression, if the F-test has a small p-value this is a good start, but not the end! In multiple regression, the F-test may be thought of as a test for “model significance”. But it doesn’t tell us which variable(s) are important and which are not.
 2. Caution: When we get into multiple regression, if the F-test has a small p-value this is a good start, but not the end. In multiple regression, the F-test may be thought of as a test for model significance . But it doesn’t tell us which variable(s) are important and which are not..")
66
66 Other Statistics from REG R-square and Adjusted R-square help us to assess the “strength” of the linear relationship. The coefficient of variation is calculated using It measures the variation as a percentage of the mean.

67
67 Coefficient of Determination The coefficient of determination ( R 2 ) gives us some idea as to the strength of the regression relationship.
 gives us some idea as to the strength of the regression relationship.")
68
68 Coefficient of Determination (R 2 ) Reflects the variation in Y that is explained by the regression relationship as a percentage of the total: With perfect linear association, SSE will be zero and R 2 will be 1. If no linear association, SSE will be the same as SST and R 2 will be 0.

69
69 Common Misconceptions Steeper slope means bigger R 2. This is not true. In fact R 2 has nothing to do with the magnitude of the slope for our regression line. The larger the value of R 2, the better the model. This is also not true. R 2 says nothing about appropriateness of model (see page 98). R 2 could be 0 but there could be a non-linear association between X & Y R 2 could be near 1 while a curvilinear model would be more appropriate (scatterplots will generally reveal this)
. R 2 could be 0 but there could be a non-linear association between X & Y R 2 could be near 1 while a curvilinear model would be more appropriate (scatterplots will generally reveal this).")
70
70 The Correlation Coefficient ( r ) Takes the sign of the slope and, for SLR, is simply the square root of R 2. Dimensionless – ranges between -1 and 1. Symmetric – interchanging X & Y will not change the correlation between them.

72
72 SAT Example: Interpret R 2 Simple interpretation: 14.8% of the variation in SAT scores is explained by the expenditures. Reality Check: (1) though significant, this is not a very strong relationship and (2) the slope parameter is negative, suggesting that increasing expenditures is associated with a decrease in the average score!
 though significant, this is not a very strong relationship and (2) the slope parameter is negative, suggesting that increasing expenditures is associated with a decrease in the average score!.")
73
73 Adjusted R 2 Uses the mean squares to adjust (penalize) for the number of parameters in the model We’ll discuss this more in multiple regression as it really isn’t important for SLR.
 for the number of parameters in the model We’ll discuss this more in multiple regression as it really isn’t important for SLR.")
74
74 Regression Diagnostics Check Your Assumptions!!!

75
75 Regression Diagnostics Assumptions Correct Model (linearity) Independent Observations Normally Distributed Errors Constant Variance Checking these generally involves PLOTS of the residuals and predicted values. Residual = observed – predicted

76
76 Regression Diagnostics (2) Key Point: Most assumption checks may be done visually by looking at various plots. They may also be done using statistical tests. Looking at plots is generally easier! So the general formula is to check the plots, and if you still have questions then perhaps consider the statistical tests.

77
77 Checking Normality Histogram or Box-plot of Residuals Is the histogram bell-shaped? Is the box-plot symmetric? Normal Probability / QQ plot This is the method we would normally use. Ordered residuals are plotted against cumulative normal probabilities and the result should be approximately linear. PROC UNIVARIATE: QQPLOT statement Shapiro-Wilks or Kolmogorov-Smirnov Test

78
78 SAS Code: QQPlot

79
79 Constancy of Variance Plot the residuals against fitted (predicted) values Check to see if size of residual is somehow associated with predicted value. Megaphone shapes are indicative of a violation. Bartlett’s or Levene’s Test Statistical tests are generally sensitive to violations of normality and cannot be used if the normality assumption is not met.

80
80 Plot: Residuals vs. Fitted Values

81
81 Checking Independence This is the hardest assumption to check. One check on this assumption is to simply think of how the data are collected. Ask the question: Is there anything in the collection of data that could lead to dependent responses? Plot the residuals over time (if applicable). Is there a “drift” or other pattern as trials proceed? Durbin-Watson Test
. Is there a drift or other pattern as trials proceed. Durbin-Watson Test.")
82
82 Other Issues Linearity Assumption: A nonlinear pattern in the residuals vs. predicted values plot suggests that we need to revise our assumption of a linear parametric relationship between X and Y. Outliers: These will show up in rather obvious ways on the various plots.

83
83 When the assumptions are violated... Discarding data is almost always the wrong thing to do. Some things you can do are... Consider transformations of the data. Transformations of the response variable [e.g. Log(Y)] often help with normality and/or constancy of variance issues. Transformations of the predictor variable(s) may solve nonlinearity issues Lastly, we may consider other more complex models.
] often help with normality and/or constancy of variance issues. Transformations of the predictor variable(s) may solve nonlinearity issues Lastly, we may consider other more complex models..")
84
84 When outliers are present... Some formal tests exist to classify outliers (we’ll talk about them later) Investigate – don’t eliminate Lacking a very good reason (e.g. experimenter made error in recording the data) you should never be throwing an outlier away. One good thing to do is to try to figure out how much effect the outlier has on your various estimates (we’ll also learn how to do this later)
 Investigate – don’t eliminate Lacking a very good reason (e.g. experimenter made error in recording the data) you should never be throwing an outlier away. One good thing to do is to try to figure out how much effect the outlier has on your various estimates (we’ll also learn how to do this later).")
85
85 Collaborative Learning Activity Please discuss problem #2.6 from the handout.

86
86 Questions?

87
87 Upcoming in Topic 3... Multiple Regression Analysis Related Reading: Chapter 8

Similar presentations






>")












