Download presentation
Presentation is loading. Please wait.

1
Week 6 Dr. Jenne Meyer

2
Article review

3
Rules of variance Keep unaccounted variance small (you want to be able to explain why the variance occurs) Determining the components of variance enables the research to estimate what variance is accounted for. ** variance enables the researcher to interpret statistically significant differences and relationships Measures of variance ANOVA (linear) Regression Analysis of covariance
 Regression Analysis of covariance.")
4
ANalysis Of VAriance can be used to test for the equality of three or more population means using data obtained from observational or experimental studies

5
In Analysis of Variance, we analyze the variance -- not the means “Good” variance is variance between groups; we want this to be different “Bad” variance is variance within groups because too much variance obscures any effects In ANOVA, we will partition the variance to try to: Show a big variance between groups Show a small variance within groups

6
ANOVA test for equality of c population means: Hypothesis: H0: m1 = m2 = m3 =…... = mc HA: Not all population means are equal Test statistic F* = MSA / MSE = numerator / denominator Rejection Rule Reject H0 if F *> Fa where the value of Fa is based on an F distribution with c - 1 numerator degrees of freedom and n - c denominator degrees of freedom.

7
As with other hypothesis tests, the rejection region for a level of significance equal to is F is the “critical value” FF F-distribution Do Not Reject H 0 Reject H 0 Critical Value MSA / MSE

8
A factor is the “general name” for the sample data that is being studied. A level refers to the number of sample variables that are associated with the factor. The levels of a factor are also know as “treatments” The response variable is the quantitative sample data

9
FactorLevels or number of treatments Quantitative Response Variable Absorption material in diaper No. of materialsAmt. of fluid absorbed (oz) College majorNo. of majorsStarting salary dollar amounts ($) Soft drink versionNo. of versionsTaste test (numerical scores) Drug typeNo. of drugsTime it takes drug to work (minutes) Plant locationNo. of facilitiesNumber of employees
 College majorNo. of majorsStarting salary dollar amounts ($) Soft drink versionNo. of versionsTaste test (numerical scores) Drug typeNo. of drugsTime it takes drug to work (minutes) Plant locationNo. of facilitiesNumber of employees.")
10
For example, let’s say you were comparing the “mean time to failure” for computer disks from 3 different suppliers….the “One Factor” that is being considered here is the “suppliers” In this case however, the “one factor” has “three levels” The “response variable” is the quantitative sample data, which is the “mean time to failure” numbers

11
A farmer grows tomatoes. He wants to test three different fertilizers (Gro-Big, Chemical X, and Tomato King) to determine their effect on producing tomatoes. The following table (next slide) shows that the farmer planted 12 plots of equal acreage with tomatoes. He used each of the three fertilizers on four different plots, then compared the number of bushels of tomatoes produced per acre in each plot. (The fertilizers are the "treatments" since they are the source of the variation in the output of tomatoes. The ANOVA analysis determines whether there is a "significant" difference in tomato output by type of fertilizer.)
 to determine their effect on producing tomatoes. The following table (next slide) shows that the farmer planted 12 plots of equal acreage with tomatoes. He used each of the three fertilizers on four different plots, then compared the number of bushels of tomatoes produced per acre in each plot. (The fertilizers are the treatments since they are the source of the variation in the output of tomatoes. The ANOVA analysis determines whether there is a significant difference in tomato output by type of fertilizer.).")
12
Gro-Big fertilizer Chemical X fertilizer Tomato King fertilizer 55 Sample Plot 1 66 Sample Plot 1 47 Sample Plot 1 54 Sample Plot 2 76 Sample Plot 2 51 Sample Plot 2 59 Sample Plot 3 67 Sample Plot 3 46 Sample Plot 3 56 Sample Plot 4 71 Sample Plot 4 48 Sample Plot 4 Tomato Production (bushels per acre)
")
13
F 4.26 Do Not Reject H 0 Reject H 0 MSA / MSE H 0 : 1 = 2 = 3 H A : At least one mean is different F = 2.9 3 samples -1 = 2 12 observations – 3samples = 9

14
Excel Output with calculation components outlined

15
At =.05, Since F > Fcrit, we Reject H 0 and conclude that at least one mean is different (at least one fertilizer yields different output); also, p-value <.05, Reject H 0
; also, p-value <.05, Reject H 0")
16
Step 1:H0: 1 = 2 = 3 HA: At least one mean is different Step 2: = 0.05 with F2,9 “Reject H0 if F >4.256” Step 3: F = 49.6 Step 4: H0 is rejected since test F is greater than critical F Step 5: At least one of the means (mean tomato production) is significantly different than the others
 is significantly different than the others")
17
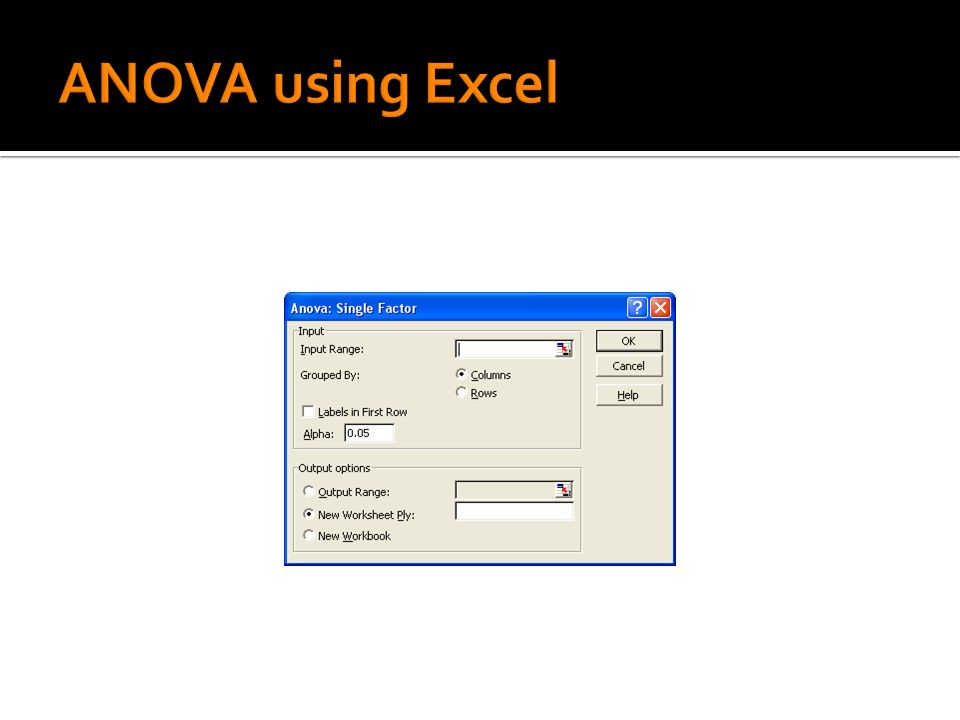
How to: Conduct One-Way ANOVA in Excel The data must be setup such that each population is in its own column Click Tools > Data Analysis… Then select ANOVA: Single Factor Enter the cell range (or sweep) the data, Enter level of significance alpha, and indicate how you want the output directed
 the data, Enter level of significance alpha, and indicate how you want the output directed")
19
J. R. Reed would like to know if the mean number of hours worked per week is the same for the department managers at her three manufacturing plants (Buffalo, Pittsburgh, and Detroit). A simple random sample of 5 managers from each of the three plants was taken and the number of hours worked by each manager for the previous week is shown below.
. A simple random sample of 5 managers from each of the three plants was taken and the number of hours worked by each manager for the previous week is shown below..")
20
F 3.89 Do Not Reject H 0 Reject H 0 MSA / MSE H 0 : 1 = 2 = 3 H A : At least one mean is different

21
At =.05, Since F > Fcrit, we Reject H 0 and conclude that at least one mean is different (at least one plant’s mean number of hours worked is different); also, p-value <.05, Reject H 0
; also, p-value <.05, Reject H 0")
22
Step 1:H0: 1 = 2 = 3 HA: At least one mean is different Step 2: = 0.05 with F2,12 “Reject H0 if F >3.89” Step 3: F = 9.54 Step 4: H0 is rejected since test F is greater than critical F Step 5: At least one of the means is significantly different (at least one plant’s mean number of hours worked is different) than the others
 than the others")
23
Up to now, we have mostly been working data based on “normal” distributions (parametric data) The data was typically interval or ratio level (height, weight, distances, etc) But, what if the data exists merely as COUNTS (frequency) of a particular category, and is nominal type data (nonparametric data)? Qualitative data are typically non-numerical in nature Nominal data categorizes data – color, brand, etc. Ordinal data orders data The frequencies or counts for each category are the only numerical data we have to work with

24
Nonparametric Tests Chi-square ▪ Goodness of fit test ▪ Testing proportions for more than two populations Wilcoxon rank sum test Kruskal-Wallis test

25
Chi-Square Goodness of Fit Test Checks to see how well a set of data fit the model for a particular “expected” probability distribution Compares the observed frequency distribution to what would be expected if the H0 were true. ▪ H0: The data come from a population with a specific probability distribution (normal, binomial, etc.) ▪ HA: The data do not come from a population with the specified distribution
 ▪ HA: The data do not come from a population with the specified distribution.")
26
Chi-Square Goodness of Fit Test The observed frequencies (fo ) (or simply “O”) are the actual number of observations that fall into each class in a frequency distribution or histogram. The expected frequencies (fe) (or simply “E”) are the number of observations that are expected in each category….the expected distribution is also known for as the “hypothesized probability distribution”
 (or simply E ) are the number of observations that are expected in each category….the expected distribution is also known for as the hypothesized probability distribution .")
27
Chi-Square Goodness of Fit Test H0: fo = fe (the data comes from a population with a specific distribution) HA: fo fe (not H0) The test statistic is: The critical value is a chi-square value with (c – 1) degrees of freedom, where c is the number of categories.
 HA: fo fe (not H0) The test statistic is: The critical value is a chi-square value with (c – 1) degrees of freedom, where c is the number of categories.")
28
Example A University expects the distribution of their students to follow the chart below.

29
Example A University expects the distribution of their students to follow the chart at the top right. The University took a survey, and observed the data distribution indicated by the table at the bottom right.

30
To calculate the chi-square, one first multiplies the expected percentages for each category times the observed data total to find the “expected” percentages for each category. Then, calculate (O-E), (O-E)2, (O-E)2/E for each category row; sum the (O-E)2/E column to find the chi-square value, 34.5620.
, (O-E)2, (O-E)2/E for each category row; sum the (O-E)2/E column to find the chi-square value,")
31
Example Find the Chi-square critical cutoff value for df = 4-1 = 3 and a =.05 The critical cutoff value is 7.815

32
Outcome: H0: There is no difference between the observed and the expected frequencies of absences. HA: There is a difference between the observed and the expected Decision Rule: Reject H0 if c2 > 7.815. Test statistic: c2 = 34.56 Conclusion: Reject H0 and conclude that there is a difference between the observed and expected frequencies of student ages.

33
Review Coke example in class

34
Chapter 12 problems 4, 7 Chapter 13 problems 1 (f only), 9, 12
, 9, 12")
Similar presentations
















 & Two-Way ANOVA>")


