Download presentation
Presentation is loading. Please wait.

1
Authors: Kenneth S.Bogh, Sean Chester, Ira Assent (Data-Intensive Systems Group, Aarhus University). Type: Research Paper Presented by: Dardan Xhymshiti Fall 2015

2
Introduction Skyline computation Related-Work GPU-Friendly partitioning The SKYALIGN algorithm Experimental evaluation

3
Skyline operator: First introduced: Stephan Borzsonyi, Donald Kossman, Konrad Stocker 2001 (Universitat Passau & Technische Universitat Muncen Germany)
")
4
Skyline operator: Example: 1. Go for a one day skiing in one of the Colorado’s ski center. 2. You have spent a lot of money. 3. It happens a car defect. 4. Try to find the nearest and cheapest hotel. 5. Take your phone and lunch the unknown touristic application. 6. A lot of hotels in different locations with variety of prices. 7. You want to find the CHEAPEST and the NEAREST one!?

5
Skyline operator: Example: Query results: Result queryPriceDistance (Miles) Hotel A$1201.5 Hotel B$1401 Hotel C$2002 Hotel D$1500.7 ….…… 120 140 150 200 0.7 1 1.5 2
 Hotel A$ Hotel B$1401 Hotel C$2002 Hotel D$ ….……")
6
Skyline operator: Example: Query results: Result queryPriceDistance (Miles) Hotel A$1201.5 Hotel B$1401 Hotel C$2002 Hotel D$1500.7 ….…… 120 140 150 200 0.7 1 1.5 2 Skyline set = {Hotel A, Hotel B, Hotel D} Term: Dominance
 Hotel A$ Hotel B$1401 Hotel C$2002 Hotel D$ ….…… Skyline set = {Hotel A, Hotel B, Hotel D} Term: Dominance")
7
Major problems: Multidimensional data. Computation intensive. Comparison tuple-to-tuple (point-to-point). What is done till now: State-of-the art sequential algorithms. Parallel skyline query processing algorithms. Often try to achieve device’s maximum theoretical compute throughput. Throughput is costly. The most efficient GPU algorithm GSS, does up to 650 times more work comparing to the best sequential algorithm, even if executing in 2688 cores. For benchmark datasets, sequential algorithms perform 3x faster than GPU ones. Should we use GPU or NOT?
. What is done till now: State-of-the art sequential algorithms. Parallel skyline query processing algorithms. Often try to achieve device’s maximum theoretical compute throughput. Throughput is costly. The most efficient GPU algorithm GSS, does up to 650 times more work comparing to the best sequential algorithm, even if executing in 2688 cores. For benchmark datasets, sequential algorithms perform 3x faster than GPU ones. Should we use GPU or NOT .")
8
Sequential algorithms high performance is achieved by using: Trees Recursion Strict ordering of computation. Unpredictable branching. Motivation: Come up with a new algorithm called SkyAlign which: MAIN POINT: Avoid as much as it can point-to-point comparisons. Employ a globally static grid schema to make the dataset compatible for GPU. This algorithm do not maximizes THROUGHPUT but is WORK-EFFICIENT. Many of these techniques are not compatible with GPU.

9
Dataset Skyline set Parallel DatasetSkyline set Sequential VS

10
Id 123 221 241 333

13
GPU Computation Tesla K80: 4992 number of Cuda Cores. Threads are grouped into warps usually of sizes 32. Warps are grouped into thread blocks. All threads within a warp execute the same instruction at the same time. Problem: branch divergence.

14
Partition-based skyline algorithms Divide-and-Conquer: Halved the dataspace recursively by the median of an arbitrarily chosen dimension and solved each half. After that the results are merged. Sequential partition-based algorithms: These algorithms employ recursive, point-based partitioning. For each partition defined, a skyline point (pivot), is found, and the other points are partitioned based on their relationship to the pivot. The work performed varies from the pivot selected. SkyAlign: is a partition-based method, but it is not recursive and has no merge.
, is found, and the other points are partitioned based on their relationship to the pivot. The work performed varies from the pivot selected. SkyAlign: is a partition-based method, but it is not recursive and has no merge..")
17
Get to know with point-based methods Point-based recursive partitioning methods use a quad-tree partitioning of the data set and record skyline points as they are found in a tree. C B E A D F

19
Why recursive partitioning is not preferred? High divergence Traversal Consider when points in F are to compare with points in D. First a DT with the root E is performed for each point, so generating bitmasks. These bitmasks are then used to determine which branches of D each point of F should traverse. Results often diverge. Partitioning Each partition has to be sub-partitioned relative to its own pivot. The pivot needs to be skyline. High dimensions Quad-tree partitioning do not scale well with dimensionality.

30
Id 123 221 241 333

31
Mask assignment: Masks are assigned for each point, given the quartiles of the dataset for each dimension.

32
Data sorting: Sort the data points based on their masks order.

33
Data sorting: Sort the data points based on their masks order.

36
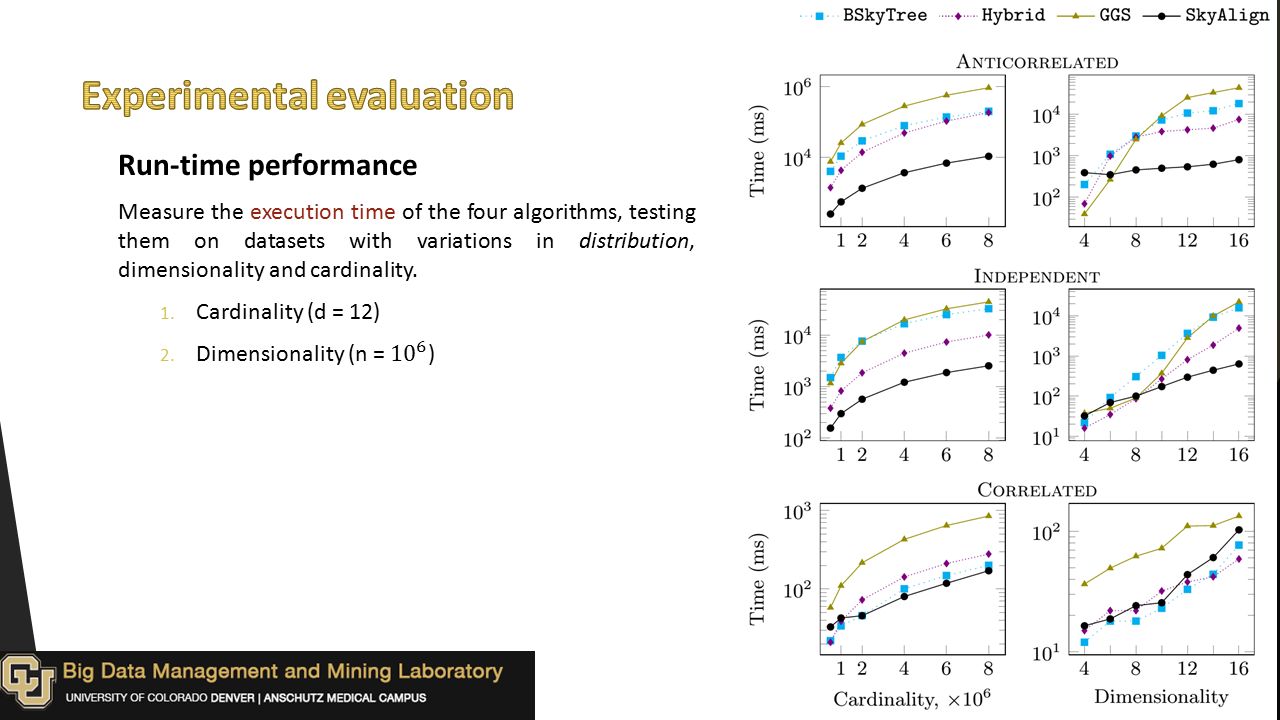
Work-efficiency Compare the performance of the four algorithms with respect to: 1. Dominance tests (DT) 2. Work-efficiency
 2. Work-efficiency.")
37
Work-efficiency Compare the performance of the four algorithms with respect to: 1. Dominance tests (DT) 2. Work-efficiency
 2. Work-efficiency.")
38
Thank You

Similar presentations
















 Republic of Korea 2011. 9. 1 Jongwuk Lee, Seung-won Hwang VLDB 2011.>")

 Presenter: Shehnaaz Yusuf March 2005.>")
















