Download presentation
Presentation is loading. Please wait.

1
Acquisition of Categorized Named Entities for Web Search Marius Pasca Google Inc. from Conference on Information and Knowledge Management (CIKM) ’04
 ’04.")
2
Introduction The recognition of names and their associated categories relies on semantic lexicons and gazetteers traditionally. They present a lightly supervised method for acquiring named entities in arbitrary categories. The method applies lightweight lexicon-syntactic extraction patterns to the unstructured text of Web documents. Four differences from traditional approaches: Not requiring any start-up seed names or training data Not encoding any domain knowledge in its extraction patterns It is only lightly supervised, and data-driven It does not impose any a-prioir restriction on the categories of extracted names

3
Problems On the input side, users submit queries that usually contain a small number of words. On the output side, there are quantitative limits since most users actually inspect only the first few documents in the search result set. Beyond measurements like term frequencies or term proximity, the occurrence of named entities signals prominent pieces of information. Users might search for lists of names, popular names, unfamiliar names. Names and their categories are hidden within the unstructured text of Web documents.

4
Extracting Categorized Names Identify names and their categories within unstructured text. Lightweight Extraction Method Document pre-processing Extraction of categorical facts Derivation of categories Extension Extraction of Similar Names Automatically-Derived Patterns

5
Lightweight Extraction Method - Document Pre-processing Filtering out HTML tags, the input documents are tokenized, split into sentences and part-of-speech tagged using TnT tagger Each sequence of capitalized terms in the sentence is marked as a potential instance name

6
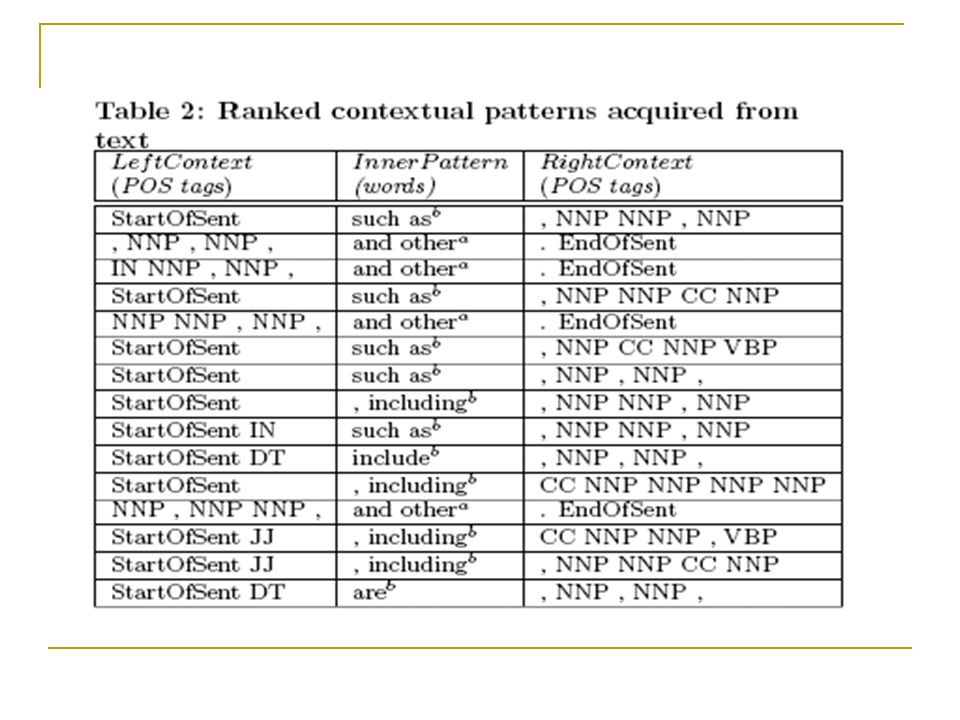
Lightweight Extraction Method - Extraction of Categorical Fact A categorical fact is a sentence nugget that is likely to provide explicitly the category of the associated instance name The fact and associated instance name are captured with a set of patterns which can be summarized as : [StartOfSent] X [such as | including] N [and|,|.] N is the potential instance name X is the categorical fact The matching of the patterns in the sentences results in pairs (X,N) of categorical facts and instance names “That is because software firewalls, including Zone Alarm, offer some semblance of this feature.” All potential instance names that are not associated with a categorical fact are discarded
![Lightweight Extraction Method - Extraction of Categorical Fact A categorical fact is a sentence nugget that is likely to provide explicitly the category of the associated instance name The fact and associated instance name are captured with a set of patterns which can be summarized as : [StartOfSent] X [such as | including] N [and|,|.] N is the potential instance name X is the categorical fact The matching of the patterns in the sentences results in pairs (X,N) of categorical facts and instance names That is because software firewalls, including Zone Alarm, offer some semblance of this feature. All potential instance names that are not associated with a categorical fact are discarded](http://images.slideplayer.com/28/9297990/slides/slide_6.jpg "Lightweight Extraction Method - Extraction of Categorical Fact A categorical fact is a sentence nugget that is likely to provide explicitly the category of the associated instance name The fact and associated instance name are captured with a set of patterns which can be summarized as : [StartOfSent] X [such as | including] N [and|,|.] N is the potential instance name X is the categorical fact The matching of the patterns in the sentences results in pairs (X,N) of categorical facts and instance names That is because software firewalls, including Zone Alarm, offer some semblance of this feature. All potential instance names that are not associated with a categorical fact are discarded")
7
Lightweight Extraction Method - Derivation of Categories The categorical facts X of the pairs (X,N) are searched for the noun phrase which encodes the category of the associated name The phrase is approximated by the rightmost non-recursive noun phrase whose last component is a plural-form noun (1) No plural-form noun phrase exists near the end of the categorical fact, the pair (X,N) is discarded (2) A plural-form noun phrase exists near the end of the categorical fact, but it is immediately (e.g., within 5 tokens) preceded by another plural-form noun phrase, the pair is discarded (3) The noun phrase is retained as the lexicalized category of the instance name N Non-informative 20 most-frequent modifiers computed statistically in a post-processing phase over the entire set of categories (programming languages rather than other programming languages)
 are searched for the noun phrase which encodes the category of the associated name The phrase is approximated by the rightmost non-recursive noun phrase whose last component is a plural-form noun (1) No plural-form noun phrase exists near the end of the categorical fact, the pair (X,N) is discarded (2) A plural-form noun phrase exists near the end of the categorical fact, but it is immediately (e.g., within 5 tokens) preceded by another plural-form noun phrase, the pair is discarded (3) The noun phrase is retained as the lexicalized category of the instance name N Non-informative 20 most-frequent modifiers computed statistically in a post-processing phase over the entire set of categories (programming languages rather than other programming languages)")
8
Lightweight Extraction Method - Derivation of categories

9
Extensions - Extraction of Similar Names To support multiple-name extraction, the patterns are slightly modified to match enumerations (N1[,N2,…and Nm]) in addition to single names (N).
![Extensions - Extraction of Similar Names To support multiple-name extraction, the patterns are slightly modified to match enumerations (N1[,N2,…and Nm]) in addition to single names (N).](http://images.slideplayer.com/28/9297990/slides/slide_9.jpg "Extensions - Extraction of Similar Names To support multiple-name extraction, the patterns are slightly modified to match enumerations (N1[,N2,…and Nm]) in addition to single names (N).")
10
Extensions - Automatically-Derived Patterns Identifying the additional patterns to increase coverage Match pairs (C,N) of categories and names, extracted in the previous iteration, back into text sentences The form of potential pattern: Duplicates of potential patterns that occur for the same category C and name N are discarded The process continues with a next iteration
 of categories and names, extracted in the previous iteration, back into text sentences The form of potential pattern: Duplicates of potential patterns that occur for the same category C and name N are discarded The process continues with a next iteration")
12
Categorized Names as Lexical Knowledge Each categorized name corresponds to an InstanceOf assertion between the name and the category Find related categories Expand existing knowledge resources

13
Category Relatedness as Set Overlap An IsA semantic relation between two categories will be reflected in their sets of instance names In practice the instance name sets are partial rather than complete Overlap between two sets indicate a strong relation between the corresponding categories Empty or very small overlaps correspond to categories that are not directly related (search engines vs languages) Medium or large-sized overlaps indicate related categories (search engines vs internet portals)
 Medium or large-sized overlaps indicate related categories (search engines vs internet portals)")
14
Category Relatedness as Set Overlap

15
Integration into Existing Knowledge Resources An immediate extension to any knowledge resources that organize English concepts hierarchically is to map the extracted names into new InstanceOf assertions. The new assertion corresponds to a new instance node being linked to an existing node at the bottom of the hierarchies. The process is straightforward only if there is exactly one possible insertion point. In general case, the name belongs to multiple categories, each of which matches zero, one, or multiple WordNet concepts.

16
Inserting Algorithm Map the extracted names into new InstanceOf assertions. The insertion algorithm links a name to at most one WordNet concept. This algorithm matches each category of the input name against WordNet concept. If a category does not match any concept, its modifiers are discarded until one or more matches are found. High-level programming languages -> programming language Each pair of related categories is represented as an additional RelatedTo link in the existing hierarchical structure.

17
Applications to Web Search Processing list-type queries When the input query matches a known category, the search results also include the top names as representative elements of that category Retrieval of siblings Users don’t know the names, but know the similar one Retrieval of similar names, or sibling names, generally anchors the name into a set of possibly-known names, thus guiding the users in their search Query refinement suggestions A set of related queries is generated and offered to the user as suggestions for refinement Each related query consists of the name and one of its categories If the input query is a known name If the input query is a known category

18
Evaluation Results (1/2) Data Two document collections: Web news articles (NewsData 12 million) and Web documents (WebData 500 million) Results
 Data Two document collections: Web news articles (NewsData 12 million) and Web documents (WebData 500 million) Results")
19
Evaluation Results (2/2) Due to the diversity of the acquired categories, we do not currently have a complete qualitative evaluation in terms of precision and recall of all acquired names. An average precision is 88%. The precision was computed over the top 50 instance names of 20 randomly-selected, compound-noun categories.

20
Conclusion (1/2) This paper presented a lightly supervised method for accessing, decoding and exploiting a very small part of the information. The collected categories of names effectively fuse and summarize semantic relations detected within initially-isolated documents. To enhance exist knowledge resources, the acquired categorized names also enable novel Web search applications. In addition to increase precision and recall, we will explore other clues for finding candidate names.

21
Conclusion (2/2) Word capitalization is the only clue used to detect possible names in text. Cannot cover names containing numbers Doesn’t generalize to other languages The extraction patterns used in the paper focus on categorical facts. Descriptive facts are a source of definitions when inserting names in existing knowledge resources like WordNet.

Similar presentations



>")



 January 2009>")
 Presented by Shauna Eggers CS 620 February.>")










