Download presentation
Presentation is loading. Please wait.

1
SF-Tree: An Efficient and Flexible Structure for Estimating Selectivity of Simple Path Expressions with Accuracy Guarantee Ho Wai Shing

2
Contents Motivation Problem Definition Perfect Binary SF-Tree Variations of SF-Tree Experiments Conclusion

3
Motivation

4
XML is becoming more and more popular e.g., product catalogs, invoices, documentations, etc We need to extract useful information out of them Queries, usually in form of XQuery or XPath, are important

5
Motivation

6
e.g., FOR $i IN document(“*”)//buyer/name $j IN document(“*”)//seller/name WHERE $i/text()=$j/text() RETURN $i
//buyer/name $j IN document( * )//seller/name WHERE $i/text()=$j/text() RETURN $i")
7
Motivation To evaluate this query, different evaluation plans are available FOR $i IN document(“*”)//buyer/name $j IN document(“*”)//seller/name WHERE $i/text()=$j/text() RETURN $i
//buyer/name $j IN document( * )//seller/name WHERE $i/text()=$j/text() RETURN $i")
8
Motivation To select the best query plan, we need the selectivity of simple path expressions (SPEs) To retrieve selectivity counts, we need a structure to store suitable statistics of the original XML document collection
 To retrieve selectivity counts, we need a structure to store suitable statistics of the original XML document collection")
9
Motivation We may use path indices to store this SPE-to-selectivity mapping e.g., DataGuide, path tree, 1-index etc. disadvantage: designed for absolute path expressions (APEs) and inefficient for simple path expressions (SPEs)
 and inefficient for simple path expressions (SPEs).")
10
Motivation

11
To increase efficiency, we may use suffix trie to store the mapping advantage: really quick, no need to scan the whole index tree disadvantage: very large, especially when the data tree is complex

12
Motivation

13
These structures are not flexible won’t change with frequently asked queries can’t make trade-offs between space and speed We can tolerate some errors in selectivity retrieval and it is good to know a bound on the error

14
Motivation Our goal: to build a new structure for estimating the selectivity of SPEs which, is faster than the path indices requires less space than suffix tries provides flexible trade-off between space and time provides accuracy guarantee on the estimated selectivity

15
Problem Definition

16
XML document is a text document that logically represents a directed edge-labeled graph called data graph consists of Elements, Attributes and other information items

17
Problem Definition

18
Data Paths a set of information items (e 1, e 2, …, e n ) each e i is directly nested within e i-1 for 2 i n i.e., a path in a data graph (not necessarily starts from root)
 each e i is directly nested within e i-1 for 2 i n i.e., a path in a data graph (not necessarily starts from root)")
19
Problem Definition Simple Path Expression (SPE) asks about the structure of XML documents has a form: //t 1 /t 2 /…/t n where t i are tags returns all information items (e n ) which is the end of a data path (e 1, e 2, …, e n ) that satisfies the SPE
 asks about the structure of XML documents has a form: //t 1 /t 2 /…/t n where t i are tags returns all information items (e n ) which is the end of a data path (e 1, e 2, …, e n ) that satisfies the SPE")
20
Problem Definition Satisfy: a data path (e 1, e 2, …, e n ) satisfies an SPE (//t 1 /t 2 /…/t n ) if: every e i has a tag t i Selectivity (or counts, selectivity counts) selectivity of an SPE (//t 1 /t 2 /…/t n ) is the number of information items e n ’s that are returned by the SPE
 satisfies an SPE (//t 1 /t 2 /…/t n ) if: every e i has a tag t i Selectivity (or counts, selectivity counts) selectivity of an SPE (//t 1 /t 2 /…/t n ) is the number of information items e n ’s that are returned by the SPE")
21
Problem Definition e.g., //buyer/name, //name, //invoice/buyer/name are all SPEs selectivity counts of //name is 2, //products is 1, //invoice is 1

22
Problem Definition

23
The Problem: given a simple path expression p and a collection D of XML documents, find the estimated selectivity s 1 of p in D while s 1 should be as close to the actual selectivity s of p in D as possible

24
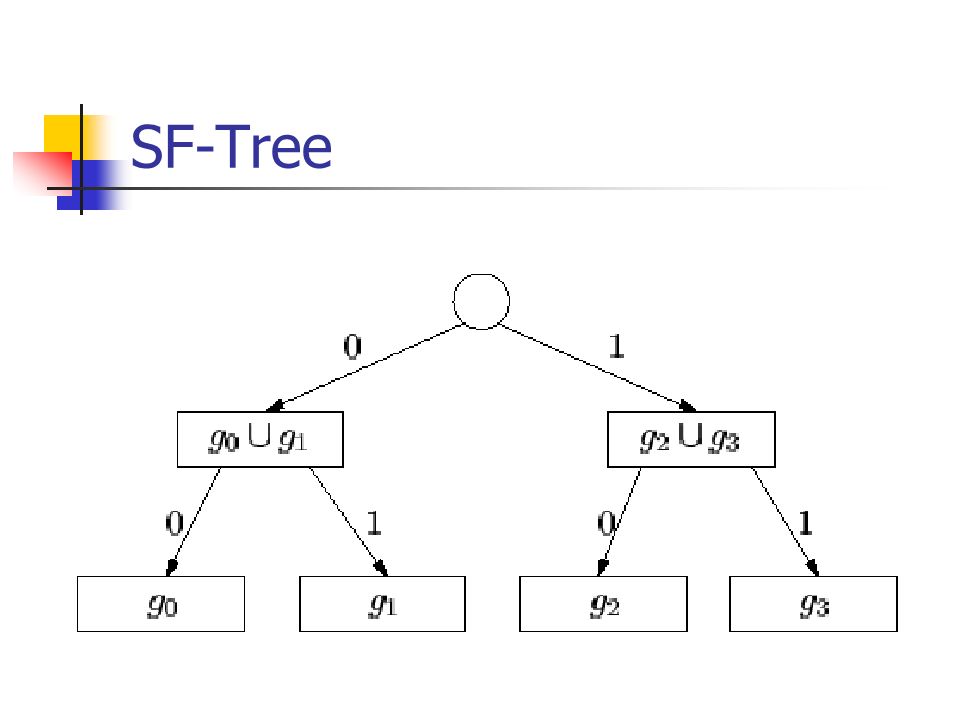
SF-Tree

25
Basic Idea: divide all possible SPEs in an XML document collection into distinct groups each SPE in a group has the same selectivity (or similar selectivity) the task of finding the selectivity of an SPE now becomes the task of finding which selectivity group this SPE belongs to
 the task of finding the selectivity of an SPE now becomes the task of finding which selectivity group this SPE belongs to")
26
SF-Tree e.g.,

27
SF-Tree e.g.,

28
SF-Tree In each group, we use a signature file to store all the paths that belong to this group This reduces the storage requirement, improves the accessing speed but induces errors to the structure

29
Signature Files A traditional technique to improve the efficiency of keyword-based information retrieval Each keyword is hashed into m bit positions of a signature file F For each keyword in the document, the corresponding m bits in F are set

30
Signature Files e.g., F has 10 bits, m = 3 //name is hashed to bits 2, 3, 8 //buyer is hashed to bits 2, 4, 9

31
Signature Files To check the existence of a query keyword k in F, k is hashed and we check whether all the m bits are set or not If any of the m bits are unset, k is not in F If all m bits are set, k is very likely to be in F

32
Signature Files e.g., (cont) if a query keyword //seller is hashed to bits 2, 8, 9, F will say //seller is in it, but it is not true bits 2, 8, 9 are in fact set by other keywords a false drop occurred
 if a query keyword //seller is hashed to bits 2, 8, 9, F will say //seller is in it, but it is not true bits 2, 8, 9 are in fact set by other keywords a false drop occurred")
33
Signature Files Previous analysis showed that in optimal case, false drop rate is (1/2) m |F | = m |D | / ln(2) where D is the set of all keywords in the document In our case, we treat an SPE in a group as a keyword and a group as a document
 m |F | = m |D | / ln(2) where D is the set of all keywords in the document In our case, we treat an SPE in a group as a keyword and a group as a document")
34
SF-Tree There are many groups for 16-bit selectivity counts, there are 2 16 groups if each group has a distinct selectivity count To get the selectivity, we need to find which group this SPE belongs to Linear scan of all groups is not feasible slow error prone

35
SF-Tree organize the groups into a tree form called an SF-Tree (stands for Signature File Tree) Rationale: create representative groups over several groups, and if an SPE is not in a representative group, it will never be in any of descendant groups of this representative group.
 Rationale: create representative groups over several groups, and if an SPE is not in a representative group, it will never be in any of descendant groups of this representative group.")
36
SF-Tree

38
Basic selectivity retrieval algorithm: 1. start from the root, 2. check which child contains the SPE p 3. descend to that child, repeat step 2, 3 until a leaf is reached 4. return the selectivity associated with that leaf

39
Perfect Binary SF-Tree A very straightforward way to build representative nodes is to build the nodes according to the most significant bits of the selectivity count i.e., all the descendants has the same m.s.b. in their selectivity counts A perfect binary SF-Tree is thus formed

40
Perfect Binary SF-Tree advantage: easy to build easy to analyze disadvantage: less flexible cannot tackle FAQ not that space efficient

41
Perfect Binary SF-Tree properties: (proofs are skipped) low error rate: let d be depth of the SF-Tree, a be the depth difference between the false drop leaf, correct leaf and their least common ancestor for negative queries, false drop rate is: R neg (d) < 1/2 d(m-1) for positive queries, max error size = 2 a, R pos (d, a) < 1/2 ma-a+1
 low error rate: let d be depth of the SF-Tree, a be the depth difference between the false drop leaf, correct leaf and their least common ancestor for negative queries, false drop rate is: R neg (d) < 1/2 d(m-1) for positive queries, max error size = 2 a, R pos (d, a) < 1/2 ma-a+1")
42
Perfect Binary SF-Tree high accessing speed: assuming no false drop, T neg (d) = 2 signatures T pos (d) = 2d signatures it doesn’t depend on the complexity of the XML documents
 = 2 signatures T pos (d) = 2d signatures it doesn’t depend on the complexity of the XML documents")
43
Perfect Binary SF-Tree each false drop induces at most 2 more signature checks expected number of signatures to be checked for positive query: C < 2d + (2d+2)(d+2)/2 m
(d+2)/2 m")
44
Perfect Binary SF-Tree storage: each SPE must appear at one leaf and all the ancestors of that leaf each SPE contributes m/ln2 bits to each signature that contains it space requirement = (m/ln2) v (|v|d v ) where v is a leaf node
 v (|v|d v ) where v is a leaf node")
45
Perfect Binary SF-Tree properties -- summary: negligible error rate (if m = 10, d = 16, error rate for a negative query is 1/2 144 !) error rate decreases as error size increases for positive queries error rate and accessing time are independent of the complexity of the XML documents
 error rate decreases as error size increases for positive queries error rate and accessing time are independent of the complexity of the XML documents")
46
Variations of SF-Tree

47
drawbacks of a perfect binary SF-Tree: every SPE has the same depth in SF-Tree, cannot optimize for FAQ too many layers, we can tolerate a higher error rate for smaller space requirement

48
Variations of SF-Tree Huffman SF-Tree Shannon-Fano SF-Tree Cropped SF-Tree

49
Huffman SF-Tree build a Huffman tree on the groups of selectivity the weight of each group can be: A. the number of SPEs in that group B. the probability of a random query will fall into that group

50
Huffman SF-Tree

51
advantage: optimal in space required over all binary SF-Trees if the weight is (A). optimal in expected number of signatures to be checked if the weight is (B). disadvantage: error rate is independent of error size
. disadvantage: error rate is independent of error size.")
52
Shannon-Fano SF-Tree build a Shannon-Fano tree over the selectivity groups the order of the leaves are not changed similar depth as in Huffman tree error rate now decreases as error size increases

53
Shannon-Fano SF-Tree We observed that the distribution of SPE over all selectivity is very skewed: most of the SPE has a very small selectivity the distribution is similar to a GP with ratio smaller than 1. The use of Huffman or Shannon-Fano tree much reduces the depth of SF-Tree

54
Shannon-Fano SF-Tree

55
Cropped SF-Tree Cropped SF-Tree is an easy trade-off between access time, space and accuracy two types of cropped SF-Tree: head-cropped SF-Tree (the top h levels of an SF-Tree is removed) tail-cropped SF-Tree (the bottom t levels of an SF-Tree is removed)
 tail-cropped SF-Tree (the bottom t levels of an SF-Tree is removed)")
56
Cropped SF-Tree original SF-Tree

57
Head-cropped SF-Tree height of the SF-Tree decreases space required is smaller accessing time increases because we have to check all the children of the root in the first step accuracy decreases a little bit because the maximum possible value of a decreases.

58
Tail-cropped SF-Tree height of the SF-Tree decreases space required is smaller accessing time is shorter (we can traverse fewer levels) accuracy is lowered (a leaf now represents a range of selectivity, i.e., the quantization step size of selectivity is larger)
 accuracy is lowered (a leaf now represents a range of selectivity, i.e., the quantization step size of selectivity is larger)")
59
Experiments

60
Data Sets

61
Experiments Query Workloads positive SPEs: randomly pick 2000 SPEs from all the SPEs in the XML document collection. Each SPE has equal probability of being picked negative SPEs: randomly concatenate tags in the XML document collection, and then remove those with non-zero selectivity until 2000 SPEs are generated

62
Experiments

63
Comparison to Competitors

64
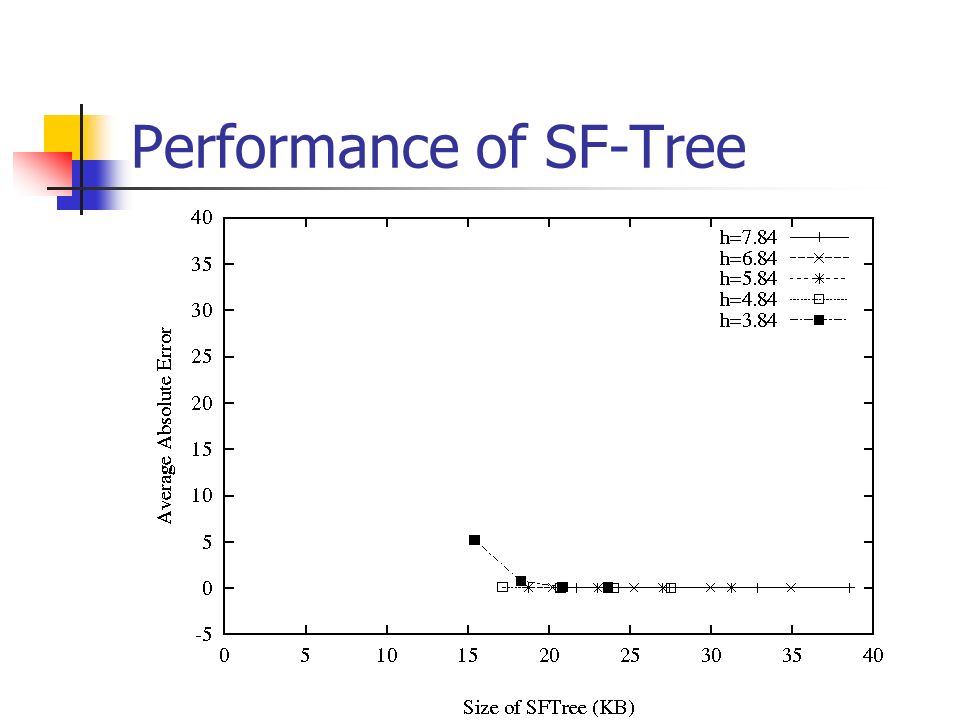
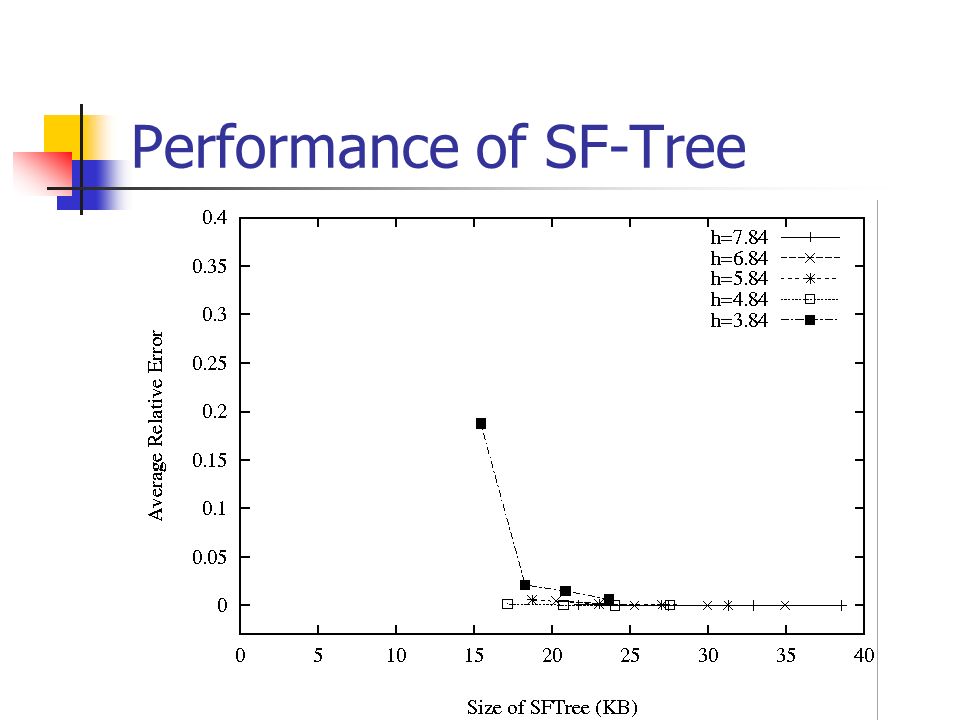
Performance of SF-Tree

67
Conclusions

68
A new structure, SF-Tree, is introduced SF-Tree is much quicker and path indices like path trees and uses much less space than suffix trie SF-Tree provides means to make a trade-off between space, time and accuracy

69
Conclusions Although SF-Tree returns only estimated selectivity, but accuracy is guaranteed Neg queries: false drop rate = 1/2 d(m-1), Pos queries: false drop rate = 1/2 ma-a+1 max error size = 1/2 a
, Pos queries: false drop rate = 1/2 ma-a+1 max error size = 1/2 a")
70
Discussions SF-Tree is a new approach to approximate some "string-to-number" structures It may be applicable to other aspects such as approximating a multi- dimensional histogram

71
Questions?

72
References A. Aboulnaga, A. R. Alameldeen, and J. F. Naughton. Estimating the selectivity of XML path expressions for internet scale applications. In VLDB, 591--600, 2001. C. Faloutsos and S. Christodoulakis. Signature files: An access method for documents and its analytical performance evaluation. ACM TOIS, 2(4):267--288, 1984. R. Goldman and J. Widom. Data Guides: Enabling query formulation and optimization in semistructured databases. In VLDB, pp. 436--445, 1997. L. Lim, M. wang, S. Padmanabhan, J. S. Vitter, and R.Parr. XPathLearner: an on-line self-tuning markov histogram for XML path selectivity estimation. In VLDB 2002. T. Milo, D. Suciu. Index structures for path expressions. In ICDT, 1999. N. Polyzotis and M. Garofalakis. Statistical synopses for graph- structured XML databases. In SIGMOD, 2002.
: , R. Goldman and J. Widom. Data Guides: Enabling query formulation and optimization in semistructured databases. In VLDB, pp , L. Lim, M. wang, S. Padmanabhan, J. S. Vitter, and R.Parr. XPathLearner: an on-line self-tuning markov histogram for XML path selectivity estimation. In VLDB T. Milo, D. Suciu. Index structures for path expressions. In ICDT, N. Polyzotis and M. Garofalakis. Statistical synopses for graph- structured XML databases. In SIGMOD,")
73
References N. Polyzotis and M. Garofalakis. Structure and value synopses for XML data graphs. In VLDB, 2002. W3C. Extensible markup language (XML) 1.0. http://www.w3.org/TR/1998/REC-xml-19980210
")
Similar presentations
 Masatoshi Yoshikawa.>")




 What is a B+ tree? Why B+ trees? Searching a B+ tree>")


>")




1 LEARNING OBJECTIVES Problems with simple indexing. Multilevel indexing: B-Tree. –B-Tree creation: insertion and deletion of nodes.>")


 Lecture 20 COMP171 Fall 2006.>")
. Motivation AVL tree with N nodes is an excellent data structure for searching, indexing, etc. –The Big-Oh analysis shows most operations.>")
 COMP171. Slide 2 Main and secondary memories Secondary storage device is much, much slower than the main RAM Pages and blocks.>")
