Download presentation
Presentation is loading. Please wait.

1
Biology 4900 Biocomputing

2
Chapter 4 BLAST

3
BLAST BLAST allows user to search a sequence (the query) against millions of sequences in the NCBI database (the target). Global alignments (e.g., Needleman-Wunsch) would be time consuming and computationally intensive for this amount of data. BLAST is designed for local alignment, not global alignment. Allows for faster searches, can match subsets of proteins (e.g., domains). C-terminal domain of CaM (from 3cln.pdb)
 would be time consuming and computationally intensive for this amount of data. BLAST is designed for local alignment, not global alignment. Allows for faster searches, can match subsets of proteins (e.g., domains). C-terminal domain of CaM (from 3cln.pdb)")
4
Other BLAST Programs Blastx: Compares nucleotide query sequence translated in all reading frames (3 possible proteins for each DNA strand) against a protein sequence DB. Tblastn: Compares protein query sequence against a nucleotide sequence DB. Tblastx: Compares the 6-frame translations of a nucleotide query sequence against the 6-frame translations of a nucleotide sequence database. 5’ CAT CAA 5’ ATC AAC 5’ TCA ACT 5’ CATCAACTACAACTCCAAAGACACCCTTACACATCAACAAACCTACCCAC 3’ 3’ GTAGTTGATGTTGAGGTTTCTGTGGGAATGTGTAGTTGTTTGGATGGGTG 5’ 5’ GTG GGT 5’ TGG GTA 5’ GGG TAG Pevsner, Bioinformatics and Functional Genomics, 2009
 against a protein sequence DB. Tblastn: Compares protein query sequence against a nucleotide sequence DB. Tblastx: Compares the 6-frame translations of a nucleotide query sequence against the 6-frame translations of a nucleotide sequence database. 5’ CAT CAA. 5’ ATC AAC. 5’ TCA ACT. 5’ CATCAACTACAACTCCAAAGACACCCTTACACATCAACAAACCTACCCAC 3’ 3’ GTAGTTGATGTTGAGGTTTCTGTGGGAATGTGTAGTTGTTTGGATGGGTG 5’ 5’ GTG GGT. 5’ TGG GTA. 5’ GGG TAG. Pevsner, Bioinformatics and Functional Genomics,")
5
Choose the BLAST program
Program Input Database 1 blastn DNA DNA blastp protein protein 6 blastx DNA protein tblastn protein DNA 36 tblastx DNA DNA

6
For sequence…FSGTWYA… A list of words (w=3) is: FSG SGT GTW TWY WYA
BLAST (Altschul 1990) Blast uses a pre-indexed database of ‘words’ for all proteins in the database (Similar to FASTA). A word is defined as a short sequence of letters. For Blastp, the default word (W) size is 3 letters. For Blastn, the default word (W) size is 11 letters. For MegaBLAST (nucleotide), the default word (W) size is 28 letters. When you run a query, BLAST breaks your query sequence into a series of words, and generates neighborhood words, as in the following example: For sequence…FSGTWYA… A list of words (w=3) is: FSG SGT GTW TWY WYA YSG TGT ATW SWY WFA FTG SVT GSW TWF WYS Words Neighborhood Words
 Blast uses a pre-indexed database of ‘words’ for all proteins in the database (Similar to FASTA). A word is defined as a short sequence of letters. For Blastp, the default word (W) size is 3 letters. For Blastn, the default word (W) size is 11 letters. For MegaBLAST (nucleotide), the default word (W) size is 28 letters. When you run a query, BLAST breaks your query sequence into a series of words, and generates neighborhood words, as in the following example: For sequence…FSGTWYA… A list of words (w=3) is: FSG SGT GTW TWY WYA. YSG TGT ATW SWY WFA. FTG SVT GSW TWF WYS. Words. Neighborhood Words.")
7
Why use BLAST? BLAST searching is fundamental to understanding the relatedness of any favorite query sequence to other known proteins or DNA sequences. Applications include identifying orthologs and paralogs discovering new genes or proteins discovering variants of genes or proteins investigating expressed sequence tags (ESTs) exploring protein structure and function
 exploring protein structure and function.")
8
Four steps to becoming a Master BLASTer
(1) Choose the sequence (query) (2) Select the BLAST program (3) Choose the database to search (4) Choose optional parameters (may leave as default params the first time) Then click “BLAST”
 Choose the sequence (query) (2) Select the BLAST program. (3) Choose the database to search. (4) Choose optional parameters (may leave as default params the first time) Then click BLAST")
10
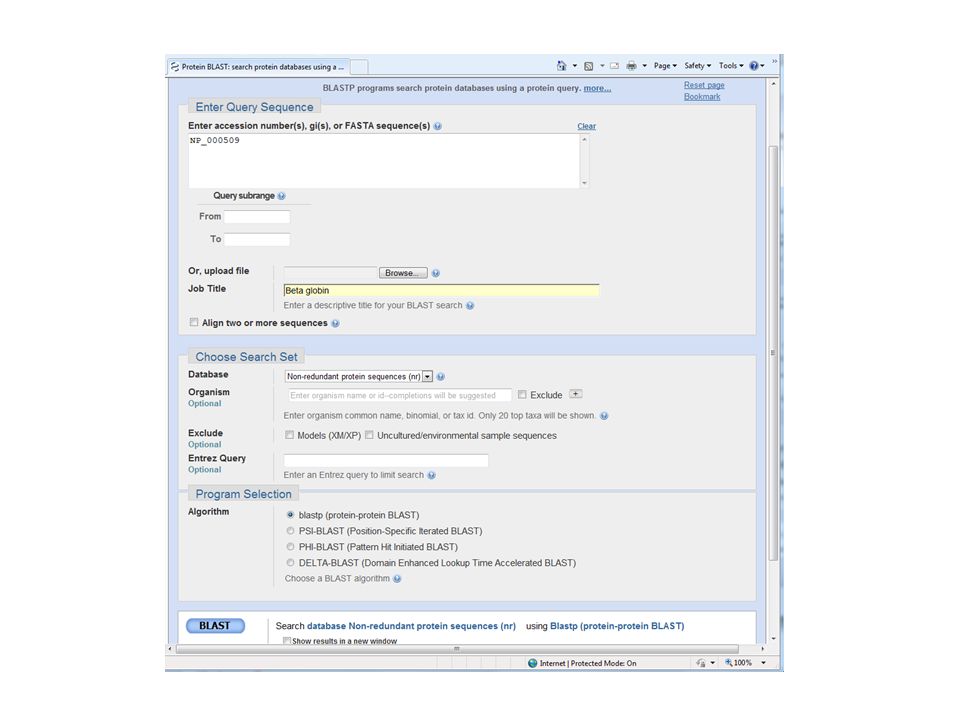
Step 1: Choose your sequence
Sequence can be input in FASTA format as text or by file upload, or as accession number

11
Example of the FASTA format for a BLAST query
Note link here

12
Step 2: Choose the BLAST program
Blastn and blastp are the main programs you will want to use

13
Step 3: choose the database to search
nr = non-redundant (most general database) dbest = database of expressed sequence tags dbsts = database of sequence tag sites gss = genomic survey sequences protein databases nucleotide databases
 dbest = database of expressed sequence tags. dbsts = database of sequence tag sites. gss = genomic survey sequences. protein databases. nucleotide databases.")
14
Step 4a: Select optional search parameters
organism Entrez! algorithm

15
Step 4a: optional blastp search parameters
Expect Word size Right. So, what are these? Scoring matrix Filter, mask

16
Step 4a: optional blastn search parameters
Expect Word size Match/mismatch scores Filter, mask

17
Algorithm Parameters: Expect
This setting specifies the statistical significance threshold for reporting matches against database sequences. The default value (10) means that 10 such matches are expected to be found merely by chance, according to the stochastic model of Karlin and Altschul (1990). If the statistical significance ascribed to a match is greater than the EXPECT threshold, the match will not be reported. Lower EXPECT thresholds (e.g., set expect to 6) are more stringent, leading to fewer chance matches being reported.
 means that 10 such matches are expected to be found merely by chance, according to the stochastic model of Karlin and Altschul (1990). If the statistical significance ascribed to a match is greater than the EXPECT threshold, the match will not be reported. Lower EXPECT thresholds (e.g., set expect to 6) are more stringent, leading to fewer chance matches being reported.")
18
Algorithm Parameters: Word Size
BLAST is a heuristic algorithm (makes approximations) that works by finding word-matches between the query and database sequences. This process finds "hot-spots" that BLAST can then potentiallyextend into full-blown alignments. For nucleotide-nucleotide searches (i.e., "blastn") an exact match of the entire word is required before an extension is initiated, so that one normally regulates the sensitivity and speed of the search by increasing or decreasing the word-size. For other BLAST searches non-exact word matches are taken into account based upon the similarity between words. The amount of similarity can be varied so one normally uses just the word-sizes 2 and 3 for these searches. KENFDKARFSGTWYAMAKKDPEG 50 RBP (query) MKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin (hit) extend extend Hit!
 that works by finding word-matches between the query and database sequences. This process finds hot-spots that BLAST can then potentiallyextend into full-blown alignments. For nucleotide-nucleotide searches (i.e., blastn ) an exact match of the entire word is required before an extension is initiated, so that one normally regulates the sensitivity and speed of the search by increasing or decreasing the word-size. For other BLAST searches non-exact word matches are taken into account based upon the similarity between words. The amount of similarity can be varied so one normally uses just the word-sizes 2 and 3 for these searches. KENFDKARFSGTWYAMAKKDPEG 50 RBP (query) MKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin (hit) extend. extend. Hit!")
19
Algorithm Parameters: Filters
The Low-complexity filter option masks part of query sequence that may represent very common, non-complex subsets of sequence. May not be very useful. The Species-repeats repeats for: filter option is designed to ignore species-specific genomic repeats in very long sequences.

20
Algorithm Parameters: Masks
The Mask for lookup table only option masks only for purposes of constructing the lookup table used by BLAST so that no hits are found based upon low-complexity sequence or repeats (if repeat filter is checked). The BLAST extensions are performed without masking and so they can be extended through low-complexity sequence. The Mask lower case letters option lets you cut and paste a FASTA sequence in upper case characters and denote areas you would like filtered with lower case. This allows you to customize what is filtered from the sequence during the comparison to the BLAST databases. These parts of sequence in LC letters masked, or ignored Ex. agvgpADEEWGYilmaagDDEEE
. The BLAST extensions are performed without masking and so they can be extended through low-complexity sequence. The Mask lower case letters option lets you cut and paste a FASTA sequence in upper case characters and denote areas you would like filtered with lower case. This allows you to customize what is filtered from the sequence during the comparison to the BLAST databases. These parts of sequence in LC letters masked, or ignored. Ex. agvgpADEEWGYilmaagDDEEE.")
21
Algorithm Parameters: Match/Mismatch Scores
Many nucleotide searches use a simple scoring system that consists of a "reward" for a match and a "penalty" for a mismatch. The (absolute) reward/penalty ratio should be increased as one looks at more divergent sequences. A ratio of 0.33 (1/-3) is appropriate for sequences that are about 99% conserved A ratio of 0.5 (1/-2) is best for sequences that are 95% conserved A ratio of about one (1/-1) is best for sequences that are 75% conserved States DJ, Gish W, and Altschul SF (1991)
 reward/penalty ratio should be increased as one looks at more divergent sequences. A ratio of 0.33 (1/-3) is appropriate for sequences that are about 99% conserved. A ratio of 0.5 (1/-2) is best for sequences that are 95% conserved. A ratio of about one (1/-1) is best for sequences that are 75% conserved. States DJ, Gish W, and Altschul SF (1991)")
22
Algorithm Parameters: Matrices
A key element in evaluating the quality of a pairwise sequence alignment is the "substitution matrix", which assigns a score for aligning any possible pair of residues. Some matrices are good for comparing sequences that diverge very little, while other matrices are good for comparing sequences that diverge a lot. The BLOSUM-62 matrix is among the best for detecting most weak protein similarities. The BLOSUM-45 matrix may be better for particularly long and weak alignments. The older PAM matrices may be better for short alignments, as these need to have a higher percentage of matching residues to exceed background noise (be detectable beyond random chance).
.")
23
Calculate the score in BLOSUM-62 for a gap with 7 residues…
Matrices and Gap Costs The raw score of an alignment is the sum of the scores for aligning pairs of residues and the scores for gaps. Gapped BLAST and PSI-BLAST use "affine gap costs" which charge the score -a for the existence of a gap, and the score -b for each residue in the gap. Thus a gap of k residues receives a total score of -(a+bk); specifically, a gap of length 1 receives the score -(a+b). Your total raw score for the alignment is reduced when you introduce gaps into the query sequence. Calculate the score in BLOSUM-62 for a gap with 7 residues…
; specifically, a gap of length 1 receives the score -(a+b). Your total raw score for the alignment is reduced when you introduce gaps into the query sequence. Calculate the score in BLOSUM-62 for a gap with 7 residues…")
24
BLAST (Altschul 1990) Neighborhood words are similar to constructed words from query, with one or more mismatched symbols. These are given scores based on the matrix that you are using (for BLAST, the default matrix is BLOSUM62). Neighborhood words that score above a user-defined threshold are also searched. Word Letter score Total score GTW 6,5,11 22 GSW 6,1,11 18 ATW 0,5,11 16 NTW 0,5,11 16 GTY 6,5,2 13 ANT 1,0, Neighborhood word hit > threshold (T) (T=11) Neighborhood word hit < threshold (T)
. Neighborhood words that score above a user-defined threshold are also searched. Word. Letter score. Total score. GTW 6,5, GSW 6,1, ATW 0,5, NTW 0,5, GTY 6,5,2 13. ANT 1,0, Neighborhood word hit > threshold (T) (T=11) Neighborhood word hit < threshold (T)")
25
extend extend Hit! BLAST (Altschul 1990)
Blast then searches the entire database for the search words and neighborhood words. Once a match is found, BLAST then extends the search in both directions of the sequence, scoring each subsequent match, until the score drops below some cutoff value. KENFDKARFSGTWYAMAKKDPEG 50 RBP (query) MKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin (hit) extend extend Hit!
 MKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin (hit) extend. extend. Hit!")
26
BLAST (1997) In a 1997 refinement of BLAST, two independent hits are required. The hits must occur in close proximity to each other. With this modification, only 1/7 as many extensions occur, greatly speeding the time required for a search.

27
Changing BLAST Input Parameters
Increasing W or T will increase speed, but will result in loss of sensitivity (i.e., you will miss some matches) The expect value(E-value) can be changed in order to limit the number of hits to the most significant ones. Lower E-value = better hit. E-value is dependent on length of query sequence and size of database. Example: an alignment obtaining an E-value of 0.05 means that there is a 5 in 100 chance of occurring by chance alone.
 The expect value(E-value) can be changed in order to limit the number of hits to the most significant ones. Lower E-value = better hit. E-value is dependent on length of query sequence and size of database. Example: an alignment obtaining an E-value of 0.05 means that there is a 5 in 100 chance of occurring by chance alone.")
28
BLAST Output from DB Search
Graphic Summary includes conserved domains, when applicable.

29
BLAST Output from DB Search
Graphic Summary includes distribution of blast hits. Color coded by bit Score. Higher score related to higher sequence identity.

30
BLAST search output: tabular output
High scores low E values

31
BLAST search output: alignment output

32
Blast Output include evolutionary tree view
Run 3cln to observe tree view options

33
Pairwise Alignment with Dot Plots
3CLN 1EXR >lcl| CLN:A|PDBID|CHAIN|SEQUENCE Length=148 Score = 268 bits (684), Expect = 3e-97, Method: Compositional matrix adjust. Identities = 130/148 (88%), Positives = 143/148 (97%), Gaps = 0/148 (0%) Query AEQLTEEQIAEFKEAFALFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN 60 A+QLTEEQIAEFKEAF+LFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN Sbjct ADQLTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN 60 Query GTIDFPEFLSLMARKMKEQDSEEELIEAFKVFDRDGNGLISAAELRHVMTNLGEKLTDDE 120 GTIDFPEFL++MARKMK+ DSEEE+ EAF+VFD+DGNG ISAAELRHVMTNLGEKLTD+E Sbjct GTIDFPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNLGEKLTDEE 120 Query VDEMIREADIDGDGHINYEEFVRMMVSK 148 VDEMIREA+IDGDG +NYEEFV+MM +K Sbjct VDEMIREANIDGDGQVNYEEFVQMMTAK 148
, Expect = 3e-97, Method: Compositional matrix adjust. Identities = 130/148 (88%), Positives = 143/148 (97%), Gaps = 0/148 (0%) Query 1 AEQLTEEQIAEFKEAFALFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN 60. A+QLTEEQIAEFKEAF+LFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN. Sbjct 1 ADQLTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGN 60. Query 61 GTIDFPEFLSLMARKMKEQDSEEELIEAFKVFDRDGNGLISAAELRHVMTNLGEKLTDDE 120. GTIDFPEFL++MARKMK+ DSEEE+ EAF+VFD+DGNG ISAAELRHVMTNLGEKLTD+E. Sbjct 61 GTIDFPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNLGEKLTDEE 120. Query 121 VDEMIREADIDGDGHINYEEFVRMMVSK 148. VDEMIREA+IDGDG +NYEEFV+MM +K. Sbjct 121 VDEMIREANIDGDGQVNYEEFVQMMTAK 148.")
34
Pairwise Alignment with Dot Plots
1RTP 3CLN Score = 30.0 bits (66), Expect = 1e-06, Method: Compositional matrix adjust. Identities = 14/51 (27%), Positives = 26/51 (51%), Gaps = 3/51 (6%) Query TIDFPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNL 112 + D +F M+ K K D F + DKD +G+I EL ++ Sbjct SFDHKKFFQMVGLKKKSAD---DVKKVFHILDKDKSGFIEEDELGSILKGF 70 Score = 25.8 bits (55), Expect = 3e-05, Method: Compositional matrix adjust. Identities = 11/40 (28%), Positives = 21/40 (53%), Gaps = 0/40 (0%) Query 4 LTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNP 43 L K+ F + DKD G I ELG Sbjct 35 LKKKSADDVKKVFHILDKDKSGFIEEDELGSILKGFSSDA 74 3CLN 1RTP
, Expect = 1e-06, Method: Compositional matrix adjust. Identities = 14/51 (27%), Positives = 26/51 (51%), Gaps = 3/51 (6%) Query 62 TIDFPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNL D +F M+ K K D ++++ F + DKD +G+I EL ++ Sbjct 23 SFDHKKFFQMVGLKKKSAD---DVKKVFHILDKDKSGFIEEDELGSILKGF 70. Score = 25.8 bits (55), Expect = 3e-05, Method: Compositional matrix adjust. Identities = 11/40 (28%), Positives = 21/40 (53%), Gaps = 0/40 (0%) Query 4 LTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNP 43. L ++ + K+ F + DKD G I ELG Sbjct 35 LKKKSADDVKKVFHILDKDKSGFIEEDELGSILKGFSSDA 74. 3CLN. 1RTP.")
35
Statistics of Local Alignments
For local pairwise alignments, best approach to determining statistical significance is to estimate an expect value (E value). The expect value E is the number of alignments with scores greater than or equal to score S (your score) that are expected to occur by chance in a database search. A score with an associated E value of 10-3 means that this particular score may occur 1 time out of 1000 alignments by chance. An E value is related to a probability value p. The key equation describing an E value is: E = Kmn e-lS Pevsner, Bioinformatics and Functional Genomics, 2009
. The expect value E is the number of alignments with scores greater than or equal to score S (your score) that are expected to occur by chance in a database search. A score with an associated E value of 10-3 means that this particular score may occur 1 time out of 1000 alignments by chance. An E value is related to a probability value p. The key equation describing an E value is: E = Kmn e-lS. Pevsner, Bioinformatics and Functional Genomics,")
36
E = Kmn e-lS This equation is derived from a description of the extreme value distribution S = the score E = the expect value = the number of high-scoring segment pairs (HSPs) expected to occur with a score of at least S m, n = the length of two sequences l, K = Karlin Altschul statistics
 expected to occur with a score of at least S. m, n = the length of two sequences. l, K = Karlin Altschul statistics.")
37
Some properties of the equation E = Kmn e-lS
The value of E decreases exponentially with increasing S (higher S values correspond to better alignments). Very high scores correspond to very low E values. The E value for aligning a pair of random sequences must be negative! Otherwise, long random alignments would acquire great scores Parameter K describes the search space (database). For E=1, one match with a similar score is expected to occur by chance. For a very much larger or smaller database, you would expect E to vary accordingly
. Very. high scores correspond to very low E values. The E value for aligning a pair of random sequences must. be negative! Otherwise, long random alignments would. acquire great scores. Parameter K describes the search space (database). For E=1, one match with a similar score is expected to. occur by chance. For a very much larger or smaller. database, you would expect E to vary accordingly.")
38
From raw scores to bit scores
There are two kinds of scores: raw scores (calculated from a substitution matrix) and bit scores (normalized scores) Bit scores are comparable between different searches because they are normalized to account for the use of different scoring matrices and different database sizes S’ = bit score = (lS - lnK) / ln2 The E value corresponding to a given bit score is: E = mn 2 -S’ Bit scores allow you to compare results between different database searches, even using different scoring matrices.
 and. bit scores (normalized scores) Bit scores are comparable between different searches. because they are normalized to account for the use. of different scoring matrices and different database sizes. S’ = bit score = (lS - lnK) / ln2. The E value corresponding to a given bit score is: E = mn 2 -S’ Bit scores allow you to compare results between different. database searches, even using different scoring matrices.")
39
How to interpret BLAST: E values and p values
The expect value E is the number of alignments with scores greater than or equal to score S that are expected to occur by chance in a database search. A p value is a different way of representing the significance of an alignment. p = 1 - e-E

40
How to interpret BLAST: E values and p values
Very small E values are very similar to p values. E values of about 1 to 10 are far easier to interpret than corresponding p values. E p (about 0.1) (about 0.05) (about 0.001)
 (about 0.05) (about 0.001)")
Similar presentations







 allows rapid sequence comparison of a query sequence [[רצף.>")





 The Mechanics of Alignments.>")


 allows rapid sequence comparison of a query sequence [[רצף.>")


