Download presentation
Presentation is loading. Please wait.

1
Information Retrieval Chapter 2 by Rajendra Akerkar, Pawan Lingras Presented by: Xxxxxx

2
Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
 is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).")
3
Process : Information Retrieval Figure 2.1 Transforming a text document to a weighted list of keywords

4
1. The first step in transforming a document is simply to list all the words in a document. 2. The second step is removal of some of the most commonly occurring words. Process : Information Retrieval

5
Data Mining has emerged as one of the most exciting and dynamic fields in computing science. The driving force for data mining is the presence of petabyte-scale online archives that potentially contain valuable bits of information hidden in them. Commercial enterprises have been quick to recognize the value of this concept; consequently, within the span of a few years, the software market itself for data mining is expected to be in excess of $10 billion. Data mining refers to a family of techniques used to detect interesting nuggets of relationships/knowledge in data. While the theoretical underpinnings of the field have been around for quite some time (in the form of pattern recognition, statistics, data analysis and machine learning), the practice and use of these techniques have been largely ad-hoc. With the availability of large databases to store, manage and assimilate data, the new thrust of data mining lies at the intersection of database systems, artificial intelligence and algorithms that efficiently analyze data. The distributed nature of several databases, their size and the high complexity of many techniques present interesting computational challenges.
, the practice and use of these techniques have been largely ad-hoc. With the availability of large databases to store, manage and assimilate data, the new thrust of data mining lies at the intersection of database systems, artificial intelligence and algorithms that efficiently analyze data. The distributed nature of several databases, their size and the high complexity of many techniques present interesting computational challenges..")
9
A given word may occur in a variety of syntactic forms ◦ plurals ◦ past tense ◦ gerund forms (a noun derived from a verb) The word connect, may appear as ◦ connector, connection, connections, connected, connecting, connects, preconnection, and postconnection. A stem is what is left after its affixes (prefixes and suffixes) are removed ◦ ed, s, or, ed, ing, and ion are suffixes ◦ pre and post are prefixes Use of stems may arguably improve retrieval performance Users rarely specify the exact forms of the word they are looking for Reasonable to retrieve documents with similar words
 are removed ◦ ed, s, or, ed, ing, and ion are suffixes ◦ pre and post are prefixes Use of stems may arguably improve retrieval performance Users rarely specify the exact forms of the word they are looking for Reasonable to retrieve documents with similar words.")
10
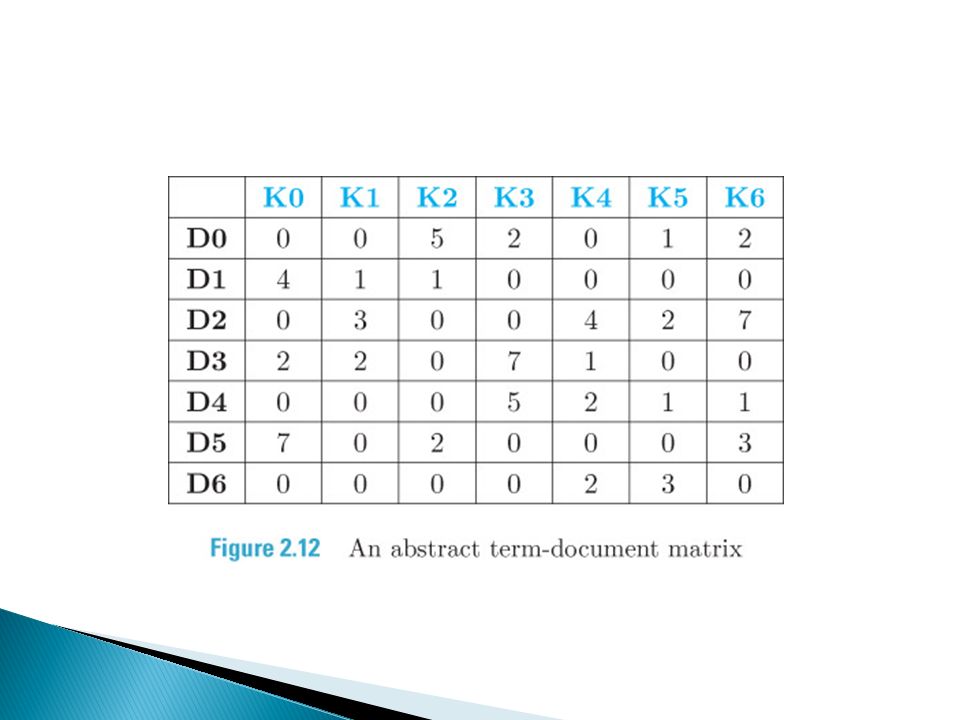
Calculating frequency of each word Term Document Matrix

11
Term-document matrix (TDM) is a two-dimensional representation of a document collection. Rows of the matrix represent various documents Columns correspond to various index terms Values in the matrix can be either the frequency or weight of the index term (identified by the column) in the document (identified by the row).
 in the document (identified by the row)..")
14
Thank You

Similar presentations




![Chapter 2 Information Retrieval Ms. Malak Bagais [textbook]: Chapter 2.](/10/2802705/big_thumb.jpg "Chapter 2 Information Retrieval Ms. Malak Bagais [textbook]: Chapter 2.>")

















