Download presentation
Presentation is loading. Please wait.

1
NETE4631: Network Information System Capacity Planning (2) Suronapee Phoomvuthisarn, Ph.D. Email: suronape@mut.ac.th / Q307suronape@mut.ac.th

2
Lecture Outline Solution to last lecture’s question (open system) Markov Chain of close system Example: Database server Example: Data center reliability
 Markov Chain of close system Example: Database server Example: Data center reliability")
3
Question1 Part (a): Calculate the resulting mean response time for each for the three alternatives This aim of this question is to compare 3 different ways to upgrade an existing system. Let us first calculate the response time of the existing system. The assumptions mean that the queue is an M/M/1 queue with arrival rate λ = 9 and mean service time (= 1/ μ ) = 0.1. This gives an utilisation ρ = λ / μ = 9 * 0.1 = 0.9. Plugging these numbers into the mean response time T for M/M/1 = 1/( μ (1- ρ )), we have T = 1s.
 = 0.1. This gives an utilisation ρ = λ / μ = 9 * 0.1 = 0.9. Plugging these numbers into the mean response time T for M/M/1 = 1/( μ (1- ρ )), we have T = 1s..")
4
Utilization Law Consider Utilisation U = B / T Mean service time per completion S = B / C Output rate X = C / T Utilisation law U = S X

5
Alternative 1 We upgrade the CPU to one twice as fast and since the service time is inversely proportional to the speed, the new mean service time = 0.05. The system is an M/M/1 queue with λ = 9 and = 1/ μ = 0.05. The utilisation ρ = λ / μ = 9 * 0.05 = 0.45. Using the M/M/1 mean response time formula gives T = 0.0909

6
Alternative 2 (Configuration 3) We use 2 existing systems and each system maintains its own queue. The arrival rateat each queue is half of the system arrival rate. Effectively, we have two M/M/1 queue with with λ = 4.5 and 1/ μ = 0.1. The utilisation ρ = λ / μ = 4.5 * 0.1 = 0.45. Using the M/M/1 mean response time formula gives T = 0.1818.

7
Alternative 3 (Configuration 2) This alternative is effectively an M/M/2 queue with λ = 9 and 1/ μ = 0.1. The utilisation ρ = λ / μ / 2= 9 * 0.1 / 2 = 0.45. Using the M/M/2 mean response time formula gives = 0.1254

8
Curve of how the response time changes with the arrival rate. Part (b): Plot a graph of arrival rates against the mean response time.
: Plot a graph of arrival rates against the mean response time..")
9
Queueing networks for close systems Closed queueing networks Have no external arrivals nor departures ( Known #customers ) Throughput depends on # customers Example: Database server A database server has a CPU and 2 disks (Disk1 and Disk2) The response time is 10s for each query. How can we improve it? Change the CPU? To what speed? Add a CPU? What speed? Add a new disk? What to move there?

10
DB server example 1 CPU, 1 fast disk, 1 slow disk. Peak demand = 2 users in the system all the time. Transactions alternate between CPU and disks. The transactions will equally likely find files on either disk Service time are exponentially distributed with mean showed in parentheses.

11
Typical capacity planning questions What response time can a typical user expect? What is the utilisation of each of the system resources? How will performance parameters change if number of users are doubled? If fast disk fails and all files are moved to slow disk, what will be the new response time?

12
Markov chain solution to the DB server problem We use a 3-tuple (X,Y,Z) as the state X is # users at CPU Y is # users at fast disk Z is # users at slow disk Examples (2,0,0): both users at CPU (1,0,1): one user at CPU and one user at slow disk Six possible states (2,0,0) (1,1,0) (1,0,1) (0,2,0) (0,1,1) (0,0,2)
 as the state X is # users at CPU Y is # users at fast disk Z is # users at slow disk Examples (2,0,0): both users at CPU (1,0,1): one user at CPU and one user at slow disk Six possible states (2,0,0) (1,1,0) (1,0,1) (0,2,0) (0,1,1) (0,0,2)")
13
Identifying state transitions (1) A state is: (#users at CPU, #users at fast disk, #users at slow disk) What is the rate of moving from State (2,0,0) to State (1,1,0)? This is caused by a job finishing at the CPU and move to fast disk Jobs complete at CPU at a rate of 6 transactions/minute Half of the jobs go to the fast disk Transition rate from (2,0,0) -> (1,1,0) = 3 transaction/minute Similarly, transition rate from (2,0,0) -> (1,0,1) = 3 transaction/minute
 -> (1,1,0) = 3 transaction/minute Similarly, transition rate from (2,0,0) -> (1,0,1) = 3 transaction/minute.")
14
Identifying state transitions (2) From (1,1,0) there are 3 possible transitions Fast disk user goes back to CPU (2,0,0) CPU user goes to the fast disk (0,2,0), or CPU user goes to the slow disk (0,1,1) Question: What are the transition rates in number of transactions per minute?
 From (1,1,0) there are 3 possible transitions Fast disk user goes back to CPU (2,0,0) CPU user goes to the fast disk (0,2,0), or CPU user goes to the slow disk (0,1,1) Question: What are the transition rates in number of transactions per minute")
15
Markov model for the database server with 2 users

16
Flow balance equations

17
Steady State Probability You can find the steady state probabilities from 6 equations It’s easier to solve the equations by a software packages, e.g Matlab, Scilab, Octave, Excel etc. The solutions are: P(2,0,0) = 0.1391 P(1,1,0) = 0.1043 P(1,0,1) = 0.2087 P(0,2,0) = 0.0783 P(0,1,1) = 0.1565 P(0,0,2) = 0.3131 How can we use these results for capacity planning?
 = P(1,1,0) = P(1,0,1) = P(0,2,0) = P(0,1,1) = P(0,0,2) = How can we use these results for capacity planning .")
18
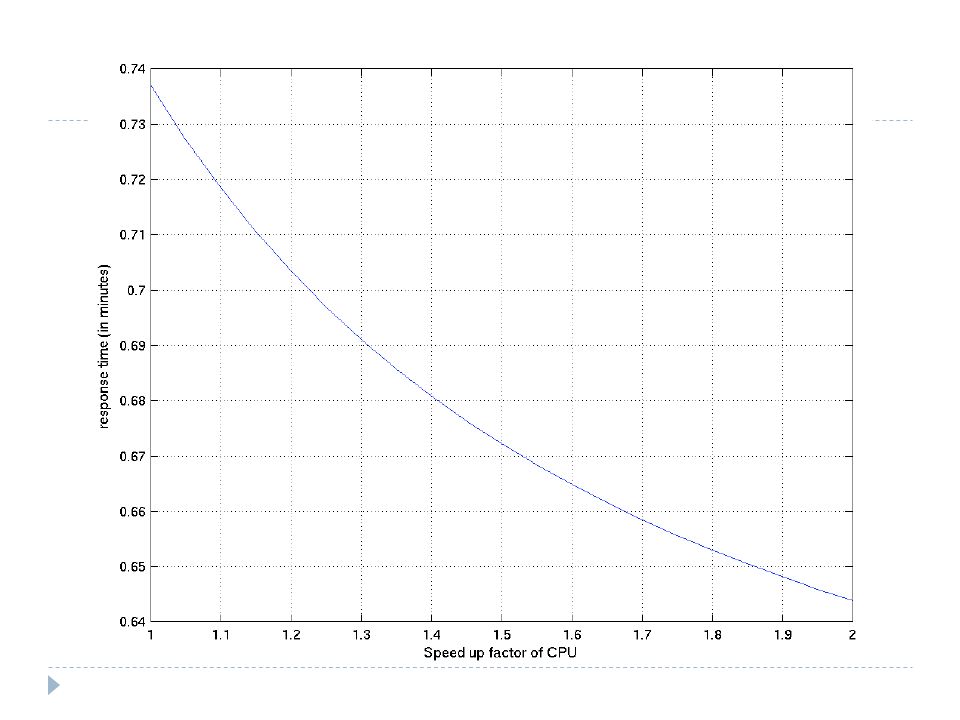
Model interpretation Response time of each transaction Use Little’s Law T = N/X with N = 2 System throughput = CPU Throughput Throughput = Utilisation x Service rate CPU utilisation (using states where there is a job at CPU): P(2,0,0)+ P(1,1,0)+P(1,0,1)= 0.4522 Throughput = 0.4521 x 6 = 2.7130 transactions / minute Response time (with 2 users) = 2 /2.7126 = 0.7372 minutes per transaction When there are a large number of users, the burden to build a Markov chain model is large If we have 4 users ->15 states need to solve 15 equations in 15 unknowns We can use Mean Value Analysis (not cover in this lecture)
: P(2,0,0)+ P(1,1,0)+P(1,0,1)= Throughput = x 6 = transactions / minute Response time (with 2 users) = 2 / = minutes per transaction When there are a large number of users, the burden to build a Markov chain model is large If we have 4 users ->15 states need to solve 15 equations in 15 unknowns We can use Mean Value Analysis (not cover in this lecture)")
19
Another Example In the previous example, we find that with the current workload and hardware specifications of the system, the response time is 0.7372 minutes per transaction. The engineer in charge of the system would like to improve the response time of the system by using a faster CPU. Assuming: The workload remains the same as before. There are always 2 users in the system. The service time for the disks remains as before. The service time for the CPU is inversely proportional to the speed of the CPU. If the engineer would like to achieve a mean response time of 0.65 minutes per transactions, by how many times must the engineer speed up the CPU? Is speeding up the CPU a good choice? Explain.

20
Solving the model

22
What if we have 3 users instead? What if we have 3 users in the database example instead of only 2 users? We continue to use (X,Y,Z) as the state X is the # users at CPU Y is the # users at the fast disk Z is the # users at the slow disk There are 10 states: (3,0,0), (2,1,0),(2,0,1) (1,2,0),(1,1,1),(1,0,2) (0,3,0),(0,2,1),(0,1,2),(0,0,3)
 as the state X is the # users at CPU Y is the # users at the fast disk Z is the # users at the slow disk There are 10 states: (3,0,0), (2,1,0),(2,0,1) (1,2,0),(1,1,1),(1,0,2) (0,3,0),(0,2,1),(0,1,2),(0,0,3).")
23
What if there are n users? You can show that if there are n users in the database server, the number of states m required will be For n = 100, m (= #states) ~ 50000 The Markov model for a practical system will require many states due to Large number of users Large number of components
 ~ The Markov model for a practical system will require many states due to Large number of users Large number of components.")
24
Example: Internet data centre availability Distributed data centers Availability problem: Each data center may go down Mean time between going down is 90 days Mean repair time is 6 hours Can I maintain 99.9999% availability for 3 out of 4 centres Technique: Markov Chain

25
Reliability problem using Markov chain Consider the working-repair cycle of a machine “Failure” is an arrival to the repair workshop “Repair” time is the service time at the repair workshop Let us assume “Time-to-next-failure” and “Repair time” are exponentially distributed

26
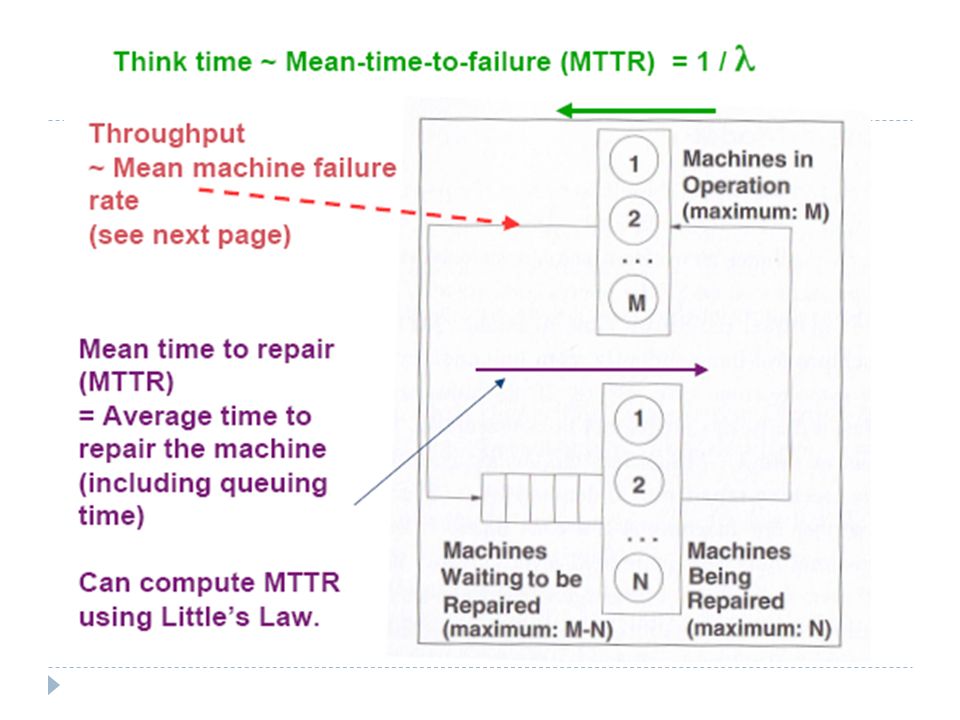
Data centre reliability problem Example: A data centre has 10 machines Each machine may go down Time-to-next-failure is exponentially distributed with mean 90 days Repair time is exponentially distributed with mean 6 hours Capacity planning question: Can I make sure that at least 8 machines are available 99.9999% of the time? What is the probability that at least 6 machines are available? How many repair staff are required to guarantee that at least k machines are available with a given probability? What is the mean time to repair (MTTR) a machine? Note: Mean-time-to-repair includes waiting time at the repair queue.
 a machine. Note: Mean-time-to-repair includes waiting time at the repair queue..")
27
Data centre reliability - general problem Data centre has M machines N staff maintain and repair machine Assumption: M > N Automatic diagnostic system Check “heartbeat” by “ping” (Failure detection) Staff are informed if failure is detected Repair work If a machine fails, any one of the idle repair staff (if there is one) will attend to it. If all repair staff are busy, a failed machine will need to wait until a repair staff has finished its work This is a queueing problem solvable by Markov chain!!! Let us denote λ = 1 / Mean-time-to-failure μ = 1/ Mean repair time

28
Queueing model for data centre example

29
Markov model for the repair queue State k represents k machines have failed Part of the state transition diagram is showed below

30
Markov Model for the repair queue (2)
")
31
Solving the model

32
Using the model Probability that exactly k machines are available = P(M-k) Probability that at least k machines are available = P(0) + P(1) … + P(M-k) But expression for P(k) are so complicated, need numerical software Example: M = 120 Mean-time-to-failure = 500 minutes Mean repair time = 20 minutes N = 2, 5 or 10 The results are showed in the graphs in the next page
 Probability that at least k machines are available = P(0) + P(1) … + P(M-k) But expression for P(k) are so complicated, need numerical software Example: M = 120 Mean-time-to-failure = 500 minutes Mean repair time = 20 minutes N = 2, 5 or 10 The results are showed in the graphs in the next page")
33
Probability that at least k machines operate

35
Mean machine failure rate

36
Continuous-time Markov chain Useful for analysing queues when the inter-arrival or service time distribution are exponential The procedure is fairly standard for obtaining the steady state probability distribution Identify the state Find the state transition rates Set up the balance equations Solve the steady state probability We can use the steady state probability to obtain other performance metrics: throughput, response time etc. May need Little’s Law etc. Continuous-time Markov chain is only applicable when the underlying probability distribution is exponential but the operations laws (e.g. Little’s Law) are applicable no matter what the underlying probability distributions are.
 are applicable no matter what the underlying probability distributions are..")
37
Simulation You had learnt how to solve a number of queues analytically (= mathematically) given their Inter-arrival time probability distribution Service time probability distribution Unfortunately, many queueing problems are still analytically intractable! We will learn discrete event simulation for queueing problems Simulation is an imitation of the operation of real-life system over time

38
References Most of the slides have been modified from COMP9334 Capacity Planning of Computer Systems and Networks Week 1-7: Introduction to Capacity Planning, Chou, C. T., 2008 Recommended reading from Chou The database server example is taken from Menasce et al., “Performance by design”, Chapter 10 The data centre example is taken from Mensace et al, “Performance by desing”, Chapter 7, Sections 1-4 For a more in-depth, and mathematical discussion of continuous-time Markov chain, see Alberto Leon-Gracia, “Probabilities and random processes for Electrical Engineering”, Chapter 8. Leonard Kleinrock, “Queueing Systems”, Volume 1

Similar presentations
 Basics of Markov.>")








- Private Cloud Lecture 11 Suronapee Phoomvuthisarn, Ph.D. />")









