Download presentation
Presentation is loading. Please wait.

1
Neural Networks and Deep Learning Slides credit: Geoffrey Hinton and Yann LeCun

2
The goals of neural computation To understand how the brain actually works –Its very big and very complicated and made of yukky stuff that dies when you poke it around To understand a new style of computation –Inspired by neurons and their adaptive connections –Very different style from sequential computation should be good for things that brains are good at (e.g. vision) Should be bad for things that brains are bad at (e.g. 23 x 71) To solve practical problems by using novel learning algorithms –Learning algorithms can be very useful even if they have nothing to do with how the brain works
 Should be bad for things that brains are bad at (e.g. 23 x 71) To solve practical problems by using novel learning algorithms –Learning algorithms can be very useful even if they have nothing to do with how the brain works.")
3
A typical cortical neuron Gross physical structure: –There is one axon that branches –There is a dendritic tree that collects input from other neurons Axons typically contact dendritic trees at synapses –A spike of activity in the axon causes charge to be injected into the post- synaptic neuron Spike generation: –There is an axon hillock that generates outgoing spikes whenever enough charge has flowed in at synapses to depolarize the cell membrane

4
Each neuron receives inputs from other neurons -Some neurons also connect to receptors -Cortical neurons use spikes to communicate -The timing of spikes is important The effect of each input line on the neuron is controlled by a synaptic weight –The weights can be positive or negative The synaptic weights adapt so that the whole network learns to perform useful computations –Recognizing objects, understanding language, making plans, controlling the body You have about 10 neurons each with about 10 weights –A huge number of weights can affect the computation in a very short time. Much better bandwidth than pentium. How the brain works 113

5
Idealized neurons To model things we have to idealize them (e.g. atoms) –Idealization removes complicated details that are not essential for understanding the main principles –Allows us to apply mathematics and to make analogies to other, familiar systems. –Once we understand the basic principles, its easy to add complexity to make the model more faithful It is often worth understanding models that are known to be wrong (but we mustn’t forget that they are wrong!) –E.g. neurons that communicate real values rather than discrete spikes of activity.
 –Idealization removes complicated details that are not essential for understanding the main principles –Allows us to apply mathematics and to make analogies to other, familiar systems. –Once we understand the basic principles, its easy to add complexity to make the model more faithful It is often worth understanding models that are known to be wrong (but we mustn’t forget that they are wrong!) –E.g. neurons that communicate real values rather than discrete spikes of activity..")
6
Linear neurons These are simple but computationally limited –If we can make them learn we may get insight into more complicated neurons output bias index over input connections i input th i weight on input 0 0 y

7
Binary threshold neurons McCulloch-Pitts (1943): influenced Von Neumann! –First compute a weighted sum of the inputs from other neurons –Then send out a fixed size spike of activity if the weighted sum exceeds a threshold. –Maybe each spike is like the truth value of a proposition and each neuron combines truth values to compute the truth value of another proposition! 1 if 0 otherwise y z 1 0 threshold

8
Linear threshold neurons 0 otherwise y z 0 threshold These have a confusing name. They compute a linear weighted sum of their inputs The output is a non-linear function of the total input

9
Sigmoid neurons These give a real-valued output that is a smooth and bounded function of their total input. –Typically they use the logistic function –They have nice derivatives which make learning easy If we treat as a probability of producing a spike, we get stochastic binary neurons. 0.5 0 0 1

10
A very simple way to recognize handwritten shapes Consider a neural network with two layers of neurons. –neurons in the top layer represent known shapes. – neurons in the bottom layer represent pixel intensities. A pixel gets to vote if it has ink on it. –Each inked pixel can vote for several different shapes. The shape that gets the most votes wins. 0 1 2 3 4 5 6 7 8 9

11
How to learn the weights Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

12
Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

13
Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

14
Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

15
Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

16
Show the network an image and increment the weights from active pixels to the correct class. Then decrement the weights from active pixels to whatever class the network guesses. The image 1 2 3 4 5 6 7 8 9 0

17
The learned weights The image 1 2 3 4 5 6 7 8 9 0

18
Why the simple system does not work A two layer network with a single winner in the top layer is equivalent to having a rigid template for each shape. –The winner is the template that has the biggest overlap with the ink. The ways in which shapes vary are much too complicated to be captured by simple template matches of whole shapes. –To capture all the allowable variations of a shape we need to learn the features that it is composed of.

19
Examples of handwritten digits that need to be recognized correctly the first time they are seen

20
Types of connectivity Feedforward networks –These compute a series of transformations –Typically, the first layer is the input and the last layer is the output. Recurrent networks –These have directed cycles in their connection graph. They can have complicated dynamics. –More biologically realistic. hidden units output units input units

21
Learning with hidden units Networks without hidden units are very limited in the input-output mappings they can model. –More layers of linear units do not help. Its still linear. –Fixed output non-linearities are not enough We need multiple layers of adaptive non-linear hidden units. This gives us a universal approximator. But how can we train such nets? –We need an efficient way of adapting all the weights, not just the last layer. This is hard. Learning the weights going into hidden units is equivalent to learning features. –Nobody is telling us directly what hidden units should do.

22
Learning by perturbing weights Randomly perturb one weight and see if it improves performance. If so, save the change. –Very inefficient. We need to do multiple forward passes on a representative set of training data just to change one weight. –Towards the end of learning, large weight perturbations will nearly always make things worse. We could randomly perturb all the weights in parallel and correlate the performance gain with the weight changes. –Not any better because we need lots of trials to “see” the effect of changing one weight through the noise created by all the others. Learning the hidden to output weights is easy. Learning the input to hidden weights is hard. hidden units output units input units

23
The idea behind backpropagation We don’t know what the hidden units ought to do, but we can compute how fast the error changes as we change a hidden activity. – Instead of using desired activities to train the hidden units, use error derivatives w.r.t. hidden activities. –Each hidden activity can affect many output units and can therefore have many separate effects on the error. These effects must be combined. –We can compute error derivatives for all the hidden units efficiently. –Once we have the error derivatives for the hidden activities, its easy to get the error derivatives for the weights going into a hidden unit.

24
A change of notation For simple networks we use the notation x for activities of input units y for activities of output units z for the summed input to an output unit For networks with multiple hidden layers: y is used for the output of a unit in any layer x is the summed input to a unit in any layer The index indicates which layer a unit is in.

25
Non-linear neurons with smooth derivatives For backpropagation, we need neurons that have well-behaved derivatives. –Typically they use the logistic function –The output is a smooth function of the inputs and the weights. 0.5 0 0 1 Its odd to express it in terms of y.

26
Sketch of the backpropagation algorithm on a single training case First convert the discrepancy between each output and its target value into an error derivative. Then compute error derivatives in each hidden layer from error derivatives in the layer above. Then use error derivatives w.r.t. activities to get error derivatives w.r.t. the weights.

27
The derivatives j i

28
Ways to use weight derivatives How often to update –after each training case? –after a full sweep through the training data? –after a “mini-batch” of training cases? How much to update –Use a fixed learning rate? –Adapt the learning rate? –Add momentum? –Don’t use steepest descent?

29
Overfitting The training data contains information about the regularities in the mapping from input to output. But it also contains noise –The target values may be unreliable. –There is sampling error. There will be accidental regularities just because of the particular training cases that were chosen. When we fit the model, it cannot tell which regularities are real and which are caused by sampling error. –So it fits both kinds of regularity. –If the model is very flexible it can model the sampling error really well. This is a disaster.

30
A simple example of overfitting Which model do you believe? –The complicated model fits the data better. –But it is not economical A model is convincing when it fits a lot of data surprisingly well. –It is not surprising that a complicated model can fit a small amount of data.

31
Ways to use weight derivatives How often to update –after each training case? –after a full sweep through the training data? –after a “mini-batch” of training cases? How much to update –Use a fixed learning rate? –Adapt the learning rate? –Add momentum? –Don’t use steepest descent?

32
The invariance problem Our perceptual systems are very good at dealing with invariances –translation, rotation, scaling –deformation, contrast, lighting, rate We are so good at this that its hard to appreciate how difficult it is. –Its one of the main difficulties in making computers perceive. –We still don’t have generally accepted solutions.

33
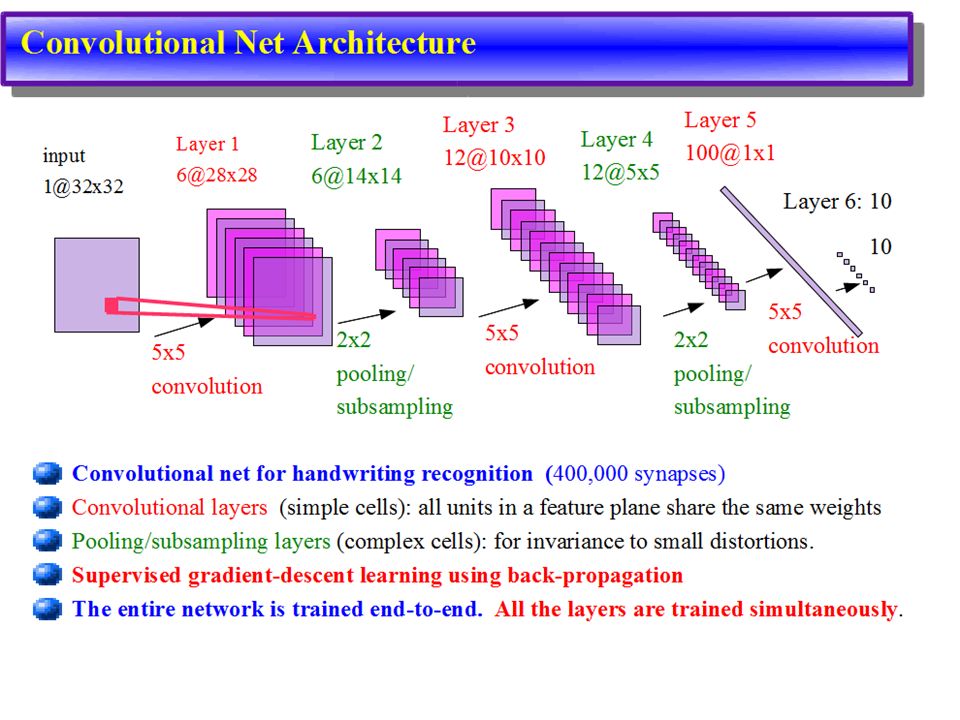
Convolutional networks

34
The replicated feature approach Use many different copies of the same feature detector. –The copies all have slightly different positions. –Could also replicate across scale and orientation. Tricky and expensive –Replication reduces the number of free parameters to be learned. Use several different feature types, each with its own replicated pool of detectors. –Allows each patch of image to be represented in several ways. The red connections all have the same weight.

35
Backpropagation with weight constraints It is easy to modify the backpropagation algorithm to incorporate linear constraints between the weights. We compute the gradients as usual, and then modify the gradients so that they satisfy the constraints. –So if the weights started off satisfying the constraints, they will continue to satisfy them.

37
Invariance to shift

38
The 82 errors made by LeNet5 Notice that most of the errors are cases that people find quite easy. The human error rate is probably 20 to 30 errors

42
LUSH and EBLearn http://eblearn.sourceforge.net http://lush.sourceforge.net

Similar presentations







>")







 l Biological Neurons l Artificial Neurons l Perceptrons l Multilayer Neural Networks l Backpropagation.>")





