Download presentation
Presentation is loading. Please wait.

1
Computational Biology Clustering Parts taken from Introduction to Data Mining by Tan, Steinbach, Kumar Lecture Slides Week 9

2
Clustering A clustering is a set of clusters Important distinction between hierarchical and partitional sets of clusters Partitional Clustering –A division data objects into non-overlapping subsets (clusters) such that each data object is in exactly one subset Hierarchical clustering –A set of nested clusters organized as a hierarchical tree
 such that each data object is in exactly one subset Hierarchical clustering –A set of nested clusters organized as a hierarchical tree")
3
Partitional Clustering Original Points A Partitional Clustering

4
Hierarchical Clustering Traditional Hierarchical Clustering Non-traditional Hierarchical ClusteringNon-traditional Dendrogram Traditional Dendrogram

5
Notion of a Cluster can be Ambiguous How many clusters? Four ClustersTwo Clusters Six Clusters

6
What is Cluster Analysis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups Inter-cluster distances are maximized Intra-cluster distances are minimized
 to one another and different from (or unrelated to) the objects in other groups Inter-cluster distances are maximized Intra-cluster distances are minimized.")
7
10 Clusters Example Starting with two initial centroids in one cluster of each pair of clusters

8
10 Clusters Example Starting with two initial centroids in one cluster of each pair of clusters

9
10 Clusters Example Starting with some pairs of clusters having three initial centroids, while other have only one.

10
10 Clusters Example Starting with some pairs of clusters having three initial centroids, while other have only one.

11
Limitations of K-means: Differing Sizes Original Points K-means (3 Clusters)
")
12
Limitations of K-means: Differing Density Original Points K-means (3 Clusters)
")
13
Limitations of K-means: Non-globular Shapes Original Points K-means (2 Clusters)
")
14
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram –A tree like diagram that records the sequences of merges or splits

15
Starting Situation Start with clusters of individual points and a proximity matrix p1 p3 p5 p4 p2 p1p2p3p4p5......... Proximity Matrix

16
Intermediate Situation After some merging steps, we have some clusters C1 C4 C2 C5 C3 C2C1 C3 C5 C4 C2 C3C4C5 Proximity Matrix

17
Intermediate Situation We want to merge the two closest clusters (C2 and C5) and update the proximity matrix. C1 C4 C2 C5 C3 C2C1 C3 C5 C4 C2 C3C4C5 Proximity Matrix

18
After Merging The question is “How do we update the proximity matrix?” C1 C4 C2 U C5 C3 ? ? ? ? ? C2 U C5 C1 C3 C4 C2 U C5 C3C4 Proximity Matrix

19
How to Define Inter-Cluster Similarity p1 p3 p5 p4 p2 p1p2p3p4p5......... Similarity? MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function –Ward’s Method uses squared error Proximity Matrix

20
How to Define Inter-Cluster Similarity p1 p3 p5 p4 p2 p1p2p3p4p5......... Proximity Matrix MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function –Ward’s Method uses squared error

21
How to Define Inter-Cluster Similarity p1 p3 p5 p4 p2 p1p2p3p4p5......... Proximity Matrix MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function –Ward’s Method uses squared error

22
How to Define Inter-Cluster Similarity p1 p3 p5 p4 p2 p1p2p3p4p5......... Proximity Matrix MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function –Ward’s Method uses squared error

23
How to Define Inter-Cluster Similarity p1 p3 p5 p4 p2 p1p2p3p4p5......... Proximity Matrix MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function –Ward’s Method uses squared error

24
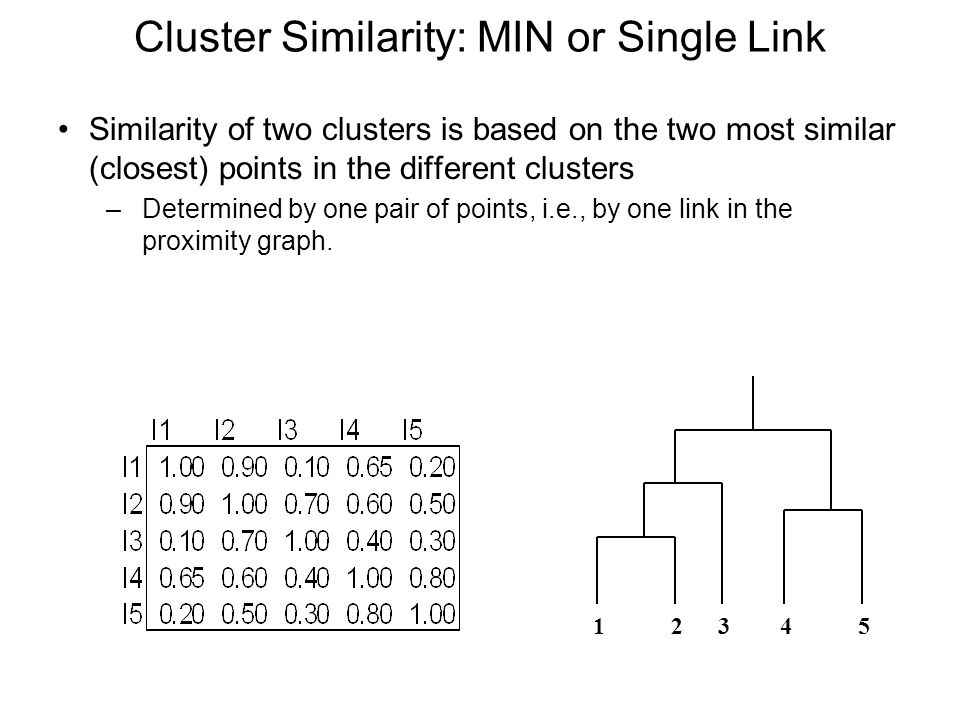
Cluster Similarity: MIN or Single Link Similarity of two clusters is based on the two most similar (closest) points in the different clusters –Determined by one pair of points, i.e., by one link in the proximity graph. 12345
25
Hierarchical Clustering: MIN Nested ClustersDendrogram 1 2 3 4 5 6 1 2 3 4 5

26
Two matrices –Proximity Matrix –“Incidence” Matrix One row and one column for each data point An entry is 1 if the associated pair of points belong to the same cluster An entry is 0 if the associated pair of points belongs to different clusters Compute the correlation between the two matrices –Since the matrices are symmetric, only the correlation between n(n-1) / 2 entries needs to be calculated. High correlation indicates that points that belong to the same cluster are close to each other. Not a good measure for some density or contiguity based clusters. Measuring Cluster Validity Via Correlation

27
Correlation of incidence and proximity matrices for the K- means clusterings of the following two data sets. Corr = -0.9235Corr = -0.5810

28
Order the similarity matrix with respect to cluster labels and inspect visually. Using Similarity Matrix for Cluster Validation

29
End Theory I 5 min mindmapping 10 min break

30
Practice I

31
Clustering Dataset We will use the same datasets as last week Have fun clustering with Orange –Try K-means clustering, hierachial clustering, MDS –Analyze differences in results

32
K? What is the k in k-means again? How many clusters are in my dataset? Solution: iterate over a reasonable number of ks Do that and try to find out how many clusters there are in your data

33
End Practice I 15 min break

34
Theory II

35
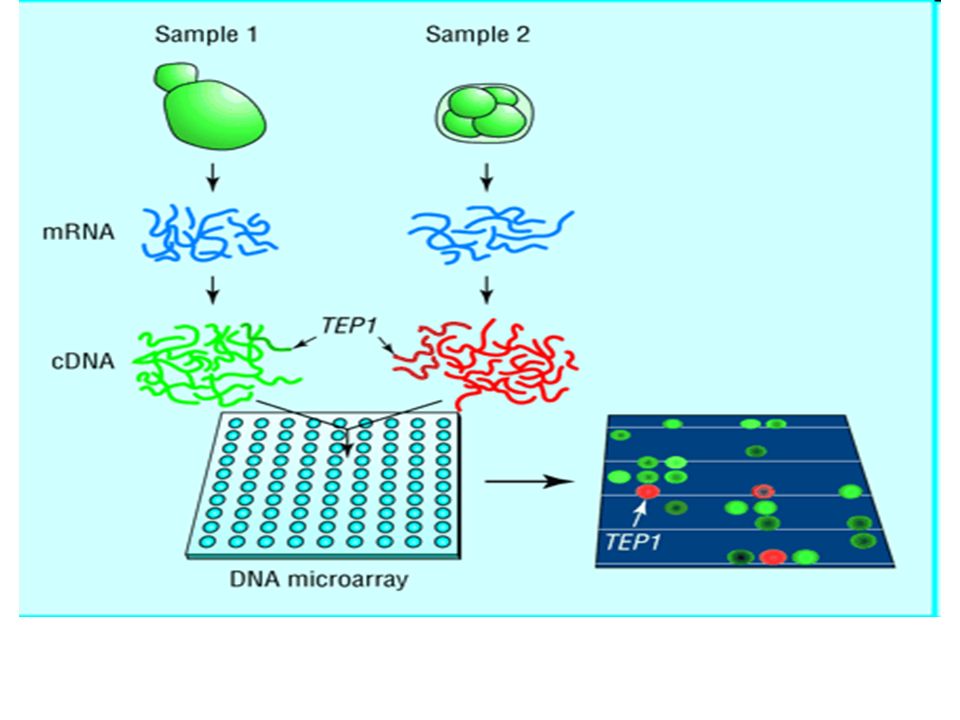
Microarrays Gene Expression: –We see difference between cels because of differential gene expression, –Gene is expressed by transcribing DNA intosingle-stranded mRNA, –mRNA is later translated into a protein, –Microarrays measure the level of mRNA expression

36
Microarrays Gene Expression: –mRNA expression represents dynamic aspects of cell, –mRNA is isolated and labeled using a fluorescent material, –mRNA is hybridized to the target; level of hybridization corresponds to light emission which is measured with a laser

37
Microarrays

40
Processing Microarray Data Differentiating gene expression: –R = G not differentiated –R > G up-regulated –R < G down regulated

41
Processing Microarray Data Problems: –Extract data from microarrays, –Analyze the meaning of the multiple arrays.

42
Processing Microarray Data

43
Problems: –Extract data from microarrays, –Analyze the meaning of the multiple arrays.

44
Processing Microarray Data Microarray data:

45
Processing Microarray Data Clustering: –Find classes in the data, –Identify new classes, –Identify gene correlations, –Methods: K-means clustering, Hierarchical clustering, Self Organizing Maps (SOM)
")
46
Processing Microarray Data Distance Measures: –Euclidean Distance: –Manhattan Distance:

47
Processing Microarray Data K-means Clustering: –Break the data into K clusters, –Start with random partitioning, –Improve it by iterating.

48
Processing Microarray Data Agglomerative Hierarchical Clustering:

49
Processing Microarray Data Self-Organizing Feature Maps: –by Teuvo Kohonen, –a data visualization technique which helps to understand high dimensional data by reducing the dimensions of data to a map.

50
Processing Microarray Data Self-Organizing Feature Maps: –humans simply cannot visualize high dimensional data as is, –SOM help us understand this high dimensional data.

51
Processing Microarray Data Self-Organizing Feature Maps: –Based on competitive learning, –SOM helps us by producing a map of usually 1 or 2 dimensions, –SOM plot the similarities of the data by grouping –similar data items together.

52
Processing Microarray Data Self-Organizing Feature Maps:

53
Processing Microarray Data Self-Organizing Feature Maps: Input vector, synaptic weight vector x = [x 1, x 2, …, x m ] T w j =[w j1, w j2, …, w jm ] T, j = 1, 2,3, l Best matching, winning neuron i(x) = arg min ||x-w j ||, j =1,2,3,..,l Weights w i are updated.
![Processing Microarray Data Self-Organizing Feature Maps: Input vector, synaptic weight vector x = [x 1, x 2, …, x m ] T w j =[w j1, w j2, …, w jm ] T, j = 1, 2,3, l Best matching, winning neuron i(x) = arg min ||x-w j ||, j =1,2,3,..,l Weights w i are updated.](http://images.slideplayer.com/27/9063394/slides/slide_53.jpg "Processing Microarray Data Self-Organizing Feature Maps: Input vector, synaptic weight vector x = [x 1, x 2, …, x m ] T w j =[w j1, w j2, …, w jm ] T, j = 1, 2,3, l Best matching, winning neuron i(x) = arg min ||x-w j ||, j =1,2,3,..,l Weights w i are updated.")
54
Figure 2. Output map containing the distributions of genes from the alpha30 database. Chavez-Alvarez R, Chavoya A, Mendez-Vazquez A (2014) Discovery of Possible Gene Relationships through the Application of Self-Organizing Maps to DNA Microarray Databases. PLoS ONE 9(4): e93233. doi:10.1371/journal.pone.0093233 http://www.plosone.org/article/info:doi/10.1371/journal.pone.0093233
 Discovery of Possible Gene Relationships through the Application of Self-Organizing Maps to DNA Microarray Databases. PLoS ONE 9(4): e doi: /journal.pone")
55
Figure 5. Color-coded output maps representing the final weight of neurons from the samples of the alpha30 database. Chavez-Alvarez R, Chavoya A, Mendez-Vazquez A (2014) Discovery of Possible Gene Relationships through the Application of Self-Organizing Maps to DNA Microarray Databases. PLoS ONE 9(4): e93233. doi:10.1371/journal.pone.0093233 http://www.plosone.org/article/info:doi/10.1371/journal.pone.0093233
 Discovery of Possible Gene Relationships through the Application of Self-Organizing Maps to DNA Microarray Databases. PLoS ONE 9(4): e doi: /journal.pone")
56
End Theory II 5 min mindmapping 10 min break

57
Practice II

58
Microarray http://www.biolab.si/supp/bi- visprog/dicty/dictyExample.htmhttp://www.biolab.si/supp/bi- visprog/dicty/dictyExample.htm Use the data as described on the page

Similar presentations