Download presentation
Presentation is loading. Please wait.

1
Performance Comparison of Speaker and Emotion Recognition

2
Abstract This research paper mainly focus on the Hidden Markov Model tool kit (HTK) which recognizes the speech , speaker and emotional speeches using the MFCC. HTK based technique gives the good result when compared to other techniques for the voice recognition, emotional speech recognition and also evaluates the the noisy test speech.
 which recognizes the speech , speaker and emotional speeches using the MFCC. HTK based technique gives the good result when compared to other techniques for the voice recognition, emotional speech recognition and also evaluates the the noisy test speech.")
3
The speech signal mainly focuses on the information like age, gender, social status, accent and emotional state of the speaker. The main challenging task is to recognize the speaker , speech and the emotion from the speeches. If the user experiences the negative emotion the system has to adjust itself the need for the user or pass the control for the human agents for alternate convenient reply from the user.

4
Introduction The emotion of the speech focuses on the use of MFCC and HTK modelling technique for recognising the speech, speaker and emotion by the speech database. In this research paper volvo , white and f16 noises are considered for the work to evaluate the emotion of independent and speaker noisy emotional speech recognition system.

5
we can get better results through the implementation of the additional pre processing techniques using the adaptive technique of the RLS filters prior to the conventional pre processing stages. noisy data are evaluated through the combination of the short time energy and zero crossing rate parameters for developing a technique which reduces the effects of the noise speech

6
Features based on CEPSTRUM
The short-time speech spectrum for voiced speech sound which has two components: 1) harmonic peaks due to the periodicity of voiced speech 2) glottal pulse shape. The excitation source decides the periodicity of voiced speech. It reflects the characteristics of speaker. The spectral envelope is shaped by formants which reflect the resonances of vocal tract.
 harmonic peaks due to the periodicity of voiced speech 2) glottal pulse shape. The excitation source decides the periodicity of voiced speech. It reflects the characteristics of speaker. The spectral envelope is shaped by formants which reflect the resonances of vocal tract.")
7
This represents the source characteristics of speech signal and based on the known variation of the human ear's. critical bandwidth with frequencies, filters spaced linearly at low frequencies and logarithmically at high frequencies preferred to extract phonetically important characteristics of speech.

8
Characteristics of Emotional speech
The structural part of the speech contains linguistic information which reveals the characteristics of the pronunciation of the utterances based on the rules of the language. Paralinguistic information refers to the internal structure messages such as emotional state of the speaker. Speeches of the emotions such as anger, fear and happy are displaying the psychological behavior of the speaker such as high blood pressure and high heart rate.

9
Speech signals are converted into frames and frequency analysis is done on the frames.
Frequencies are calculated on the basis of choosing the frequency bin which has high spectral energy. It is indicated that emotions such as anger, fear and happy have more number of frames with high frequency energy and the emotion sadness has very few frames with high frequency energy

10
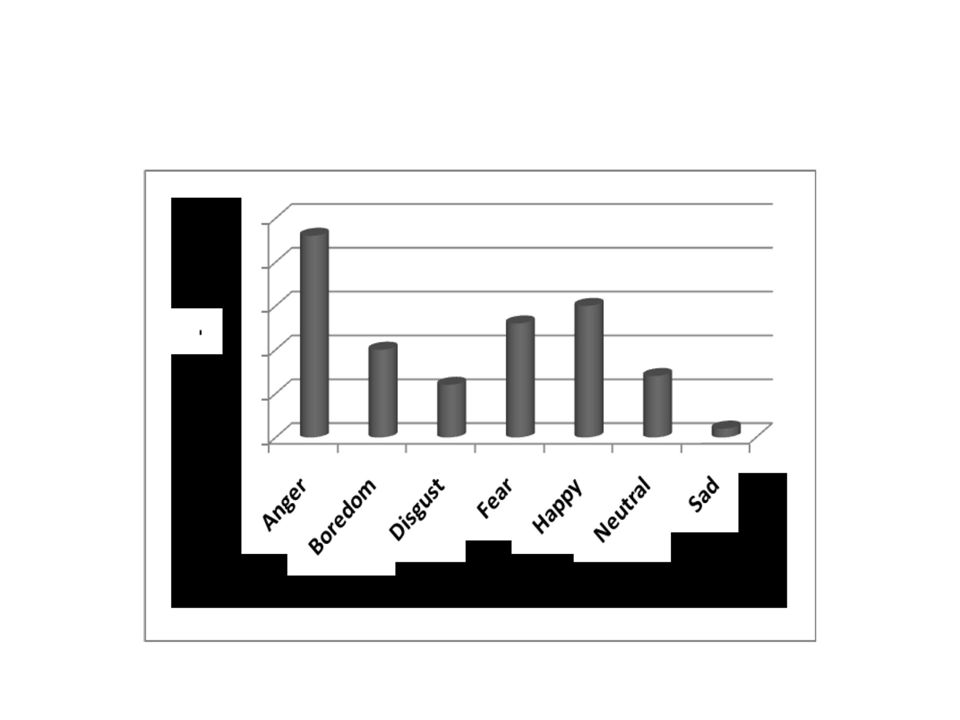
Frequency distribution of speech in different emotions.

12
SPEECH RECOGNITION USING HTK
Utterances are chosen from 10 different actors and ten different texts. Ten emotional utterances are collected from five male and Female speakers respectively in the age ranging from 21 to 35 years. They are required to utter ten different utterances in Berlin in seven different emotions such as anger, boredom, disgust, fear, happy, neutral and sad. Speech recognition system generally involves the realization of speech signal as the message encoded as the sequence of one or more symbols.

13
Then the MFCC features are extracted
Then the MFCC features are extracted. For each training model corresponding to continuous speeches, training set of K utterances are used, where each utterance constitutes an observation sequence of some appropriate spectral or temporal representation.

16
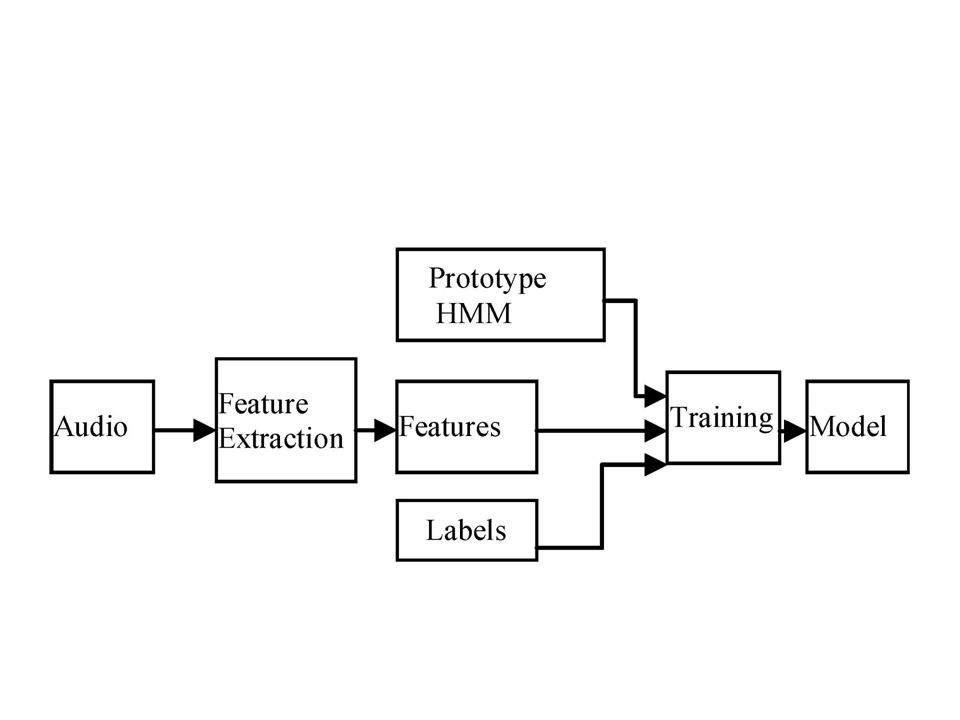
HCopy is the HTK tool used for MFCC extraction.
HCompV is a tool for computing overall mean and variance and generating proto type HMM. HInit is a tool used to read all the bootstrapped training data for initializing a single Hidden markov model using a segmental K-means algorithm.

17
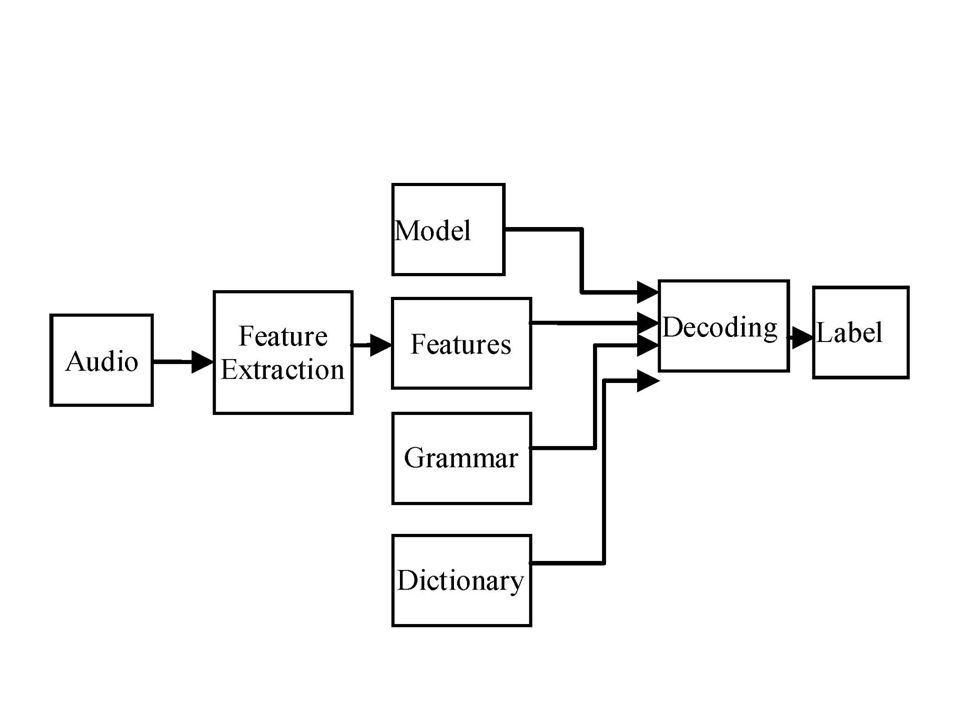
HVite is a general purpose speech recognizer
HVite is a general purpose speech recognizer. It matches the speech file against a network of HMMs and output a transcription for each speech. The HTK recognizer actually requires a network to be defined using a HTK lattice format in which word to word transcription is done.

18
HResuIt is HTK performance analysis tool which reads the set of label files and compares them with the corresponding reference transcription.

19
Noise Characteristics
White noise signal Frequency distribution of white noise

20
Emotion independent speaker recognition

21
NOISY SPEECH RECOGNITION
Noisy speech recognition in this paper is such that performance of the noisy speech recognition system, noises such as volvo, white and F16 are taken from "Noisex-92" database. The noise reduced speech closely resembling the clean test speech is obtained. Then, conventional preprocessing techniques are applied on the noise reduced speeches and features are extracted.

22
RESULTS AND DISCUSSION
Hear in this paper, the performance of emotion independent speech recognition is evaluated by considering the ten utterances spoken by ten actors. Overall accuracy for emotion independent speech recognition and speaker independent speech recognition are 91 % and 87% respectively for F16 noise added to the test speeches.

23
CONCLUSION The performance of speech and speaker recognition systems is found to be good and is slightly low for emotion recognition. This is probably due to the usage of same set of speech of same set of speakers in different emotions. The variance of the noise reduced speech is almost same as that of the clean speech. Features extracted from the noise-reduced speeches are applied to models of the clean data and performance is measured in terms of recognition accuracy.

24
Thank you..!

Similar presentations

 Gunjan Gupta Gunjan Gupta (10bec112)>")
,>")


 signal using different mathematical models in Matlab to predict.>")













