Download presentation
Presentation is loading. Please wait.

1
Matei Zaharia Introduction to

2
Outline The big data problem Spark programming model User community Newest addition: DataFrames

3
Data is growing faster than computation speeds Growing data sources Web, mobile, scientific, … Cheap storage Doubling every 18 months Stalling CPU speeds The Big Data Problem

4
Examples Facebook’s daily logs: 60 TB 1000 genomes project: 200 TB Google web index: 10+ PB Cost of 1 TB of disk: $30 Time to read 1 TB from disk: 6 hours (50 MB/s)
")
5
The Big Data Problem Single machine can no longer process or even store all the data! Only solution is to distribute over large clusters

6
Google Datacenter How do we program this thing?

7
Message-passing between nodes Really hard to do at scale: How to divide problem across nodes? How to deal with failures? Even worse: stragglers (node is not failed, but slow) Almost nobody does this for “big data” Traditional Network Programming
 Almost nobody does this for big data Traditional Network Programming.")
8
To Make Matters Worse 1) User time is also at premium Many analyses are exploratory 2) Complexity of analysis is growing Unstructured data, machine learning, etc
 User time is also at premium Many analyses are exploratory 2) Complexity of analysis is growing Unstructured data, machine learning, etc")
9
Outline The big data problem Spark programming model User community Newest addition: DataFrames

10
What is Spark? Fast and general engine that can extends Google’s MapReduce model High-level APIs in Java, Scala, Python, R Collection of higher-level libraries

11
Spark Programming Model Part of a family of data-parallel models Other examples: MapReduce, Dryad Restricted API compared to message-passing: “here’s an operation, run it on all the data” I don’t care where it runs (you schedule that) Feel free to run it twice on different nodes
 Feel free to run it twice on different nodes")
12
Key Idea Resilient Distributed Datasets (RDDs) Immutable collections of objects that can be stored in memory or disk across a cluster Built with parallel transformations (map, filter, …) Automatically rebuilt on failure
 Immutable collections of objects that can be stored in memory or disk across a cluster Built with parallel transformations (map, filter, …) Automatically rebuilt on failure")
13
Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”) errors = lines.filter(s => s.startswith(“ERROR”)) messages = errors.map(s => s.split(‘\t’)(2)) messages.cache() Block 1 Block 2 Block 3 Worker Driver messages.filter(s => s.contains(“foo”)).count() messages.filter(s => s.contains(“bar”)).count()... tasks results Cache 1 Cache 2 Cache 3 Base RDD Transformed RDD Action Result: full-text search of Wikipedia in 1 sec (vs 40 s for on-disk data)
.")
14
Fault Tolerance file.map(record => (record.type, 1)).reduceByKey((x, y) => x + y).filter((type, count) => count > 10) filterreducemap Input file RDDs track lineage info to rebuild lost data
).reduceByKey((x, y) => x + y).filter((type, count) => count > 10) filterreducemap Input file RDDs track lineage info to rebuild lost data")
15
filterreducemap Input file Fault Tolerance file.map(record => (record.type, 1)).reduceByKey((x, y) => x + y).filter((type, count) => count > 10) RDDs track lineage info to rebuild lost data
).reduceByKey((x, y) => x + y).filter((type, count) => count > 10) RDDs track lineage info to rebuild lost data")
16
Example: Logistic Regression Goal: find best line separating two sets of points + – + + + + + + + + – – – – – – – – + target – random initial line

17
Example: Logistic Regression data = spark.textFile(...).map(readPoint).cache() w = Vector.random(D) for (i <- 1 to iterations) { gradient = data.map(p => (1 / (1 + exp(-p.y * w.dot(p.x)))) * p.y * p.x ).reduce((x, y) => x + y) w -= gradient } println(“Final w: ” + w)
.map(readPoint).cache() w = Vector.random(D) for (i <- 1 to iterations) { gradient = data.map(p => (1 / (1 + exp(-p.y * w.dot(p.x)))) * p.y * p.x ).reduce((x, y) => x + y) w -= gradient } println( Final w: + w)")
18
Logistic Regression Results 110 s / iteration first iteration 80 s further iterations 1 s

19
Demo

20
Higher-Level Libraries Spark Spark Streaming real-time Spark SQL structured data MLlib machine learning GraphX graph

21
Combining Processing Types // Load data using SQL points = ctx.sql(“select latitude, longitude from tweets”) // Train a machine learning model model = KMeans.train(points, 10) // Apply it to a stream sc.twitterStream(...).map(t => (model.predict(t.location), 1)).reduceByWindow(“5s”, (a, b) => a + b)
 // Train a machine learning model model = KMeans.train(points, 10) // Apply it to a stream sc.twitterStream(...).map(t => (model.predict(t.location), 1)).reduceByWindow( 5s , (a, b) => a + b)")
22
Performance of Composition Separate computing frameworks: … HDFS read HDFS write ETL HDFS read HDFS write train HDFS read HDFS write query HDFS write HDFS read ETL train query Spark:

23
Outline The big data problem Spark programming model User community Newest addition: DataFrames

24
Spark Users 1000+ deployments, clusters up to 8000 nodes

25
Applications Large-scale machine learning Analysis of neuroscience data Network security SQL and data clustering Trends & recommendations

26
Which Libraries Do People Use? 75% of users use 2 or more components 50% use three or more components

27
Which Languages Are Used? 2014 Languages Used2015 Languages Used

28
Community Growth Most active open source project in big data

29
Outline The big data problem Spark programming model User community Newest addition: DataFrames

30
Challenges with Functional API Looks high-level, but hides many semantics of computation from engine Functions passed in are arbitrary blocks of code Data stored is arbitrary Java/Python objects Users can mix APIs in suboptimal ways

31
Example Problem pairs = data.map(word => (word, 1)) groups = pairs.groupByKey() groups.map((k, vs) => (k, vs.sum)) Materializes all groups as lists of integers Then promptly aggregates them
) groups = pairs.groupByKey() groups.map((k, vs) => (k, vs.sum)) Materializes all groups as lists of integers Then promptly aggregates them")
32
Challenge: Data Representation Java objects often many times larger than data class User(name: String, friends: Array[Int]) User(“Bobby”, Array(1, 2)) User0x… String 3 0 12 Bobby 5 0x… int[] char[] 5
![Challenge: Data Representation Java objects often many times larger than data class User(name: String, friends: Array[Int]) User( Bobby , Array(1, 2)) User0x… String Bobby 5 0x… int[] char[] 5](http://images.slideplayer.com/27/8996484/slides/slide_32.jpg "Challenge: Data Representation Java objects often many times larger than data class User(name: String, friends: Array[Int]) User( Bobby , Array(1, 2)) User0x… String Bobby 5 0x… int[] char[] 5")
33
DataFrames / Spark SQL Efficient library for working with structured data Two interfaces: SQL for data analysts and external apps, DataFrames for complex programs Optimized computation and storage underneath Spark SQL added in 2014, DataFrames in 2015

34
Spark SQL Architecture Logical Plan Physical Plan Catalog Optimizer RDDs … Data Source API SQL Data Frames Data Frames Code Generator

35
DataFrame API DataFrames hold rows with a known schema and offer relational operations through a DSL c = HiveContext() users = c.sql(“select * from users”) ma_users = users[users.state == “MA”] ma_users.count() ma_users.groupBy(“name”).avg(“age”) ma_users.map(lambda row: row.user.toUpper()) Expression AST
![DataFrame API DataFrames hold rows with a known schema and offer relational operations through a DSL c = HiveContext() users = c.sql( select * from users ) ma_users = users[users.state == MA ] ma_users.count() ma_users.groupBy( name ).avg( age ) ma_users.map(lambda row: row.user.toUpper()) Expression AST](http://images.slideplayer.com/27/8996484/slides/slide_35.jpg "DataFrame API DataFrames hold rows with a known schema and offer relational operations through a DSL c = HiveContext() users = c.sql( select * from users ) ma_users = users[users.state == MA ] ma_users.count() ma_users.groupBy( name ).avg( age ) ma_users.map(lambda row: row.user.toUpper()) Expression AST")
36
API Details Based on data frame concept in R, Python Spark is the first to make this declarative Integrated with the rest of Spark ML library takes DataFrames as input & output Easily convert RDDs ↔ DataFrames Google trends for “data frame”

37
What DataFrames Enable 1.Compact binary representation Columnar, compressed cache; rows for processing 2.Optimization across operators (join reordering, predicate pushdown, etc) 3.Runtime code generation
 3.Runtime code generation")
38
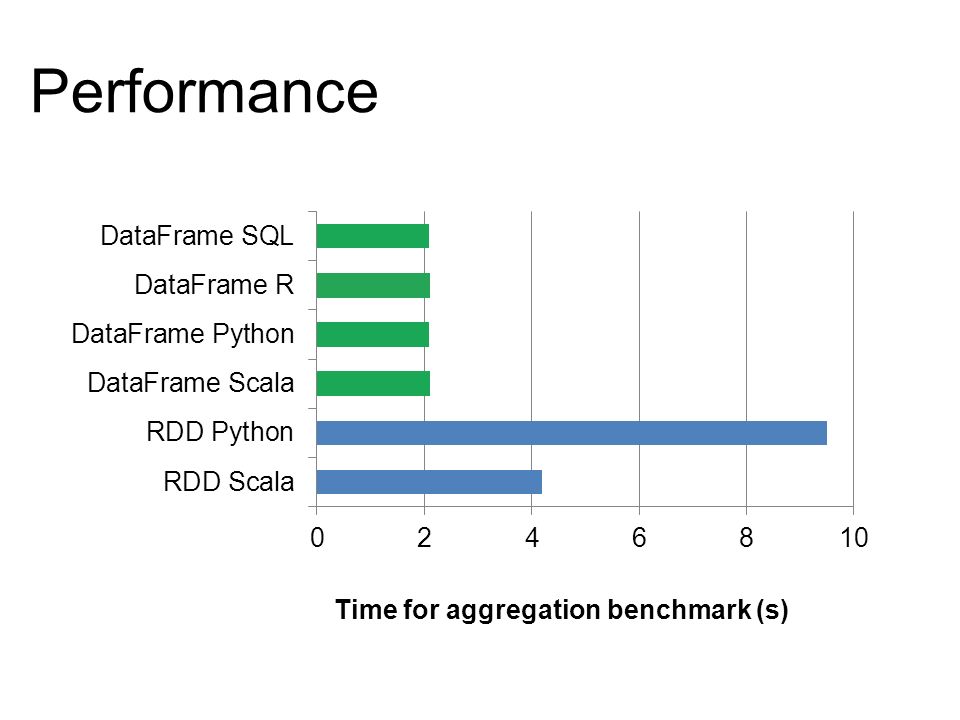
Performance

40
Data Sources Uniform way to access structured data Apps can migrate across Hive, Cassandra, JSON, … Rich semantics allows query pushdown into data sources Spark SQL users[users.age > 20] select * from users
![Data Sources Uniform way to access structured data Apps can migrate across Hive, Cassandra, JSON, … Rich semantics allows query pushdown into data sources Spark SQL users[users.age > 20] select * from users](http://images.slideplayer.com/27/8996484/slides/slide_40.jpg "Data Sources Uniform way to access structured data Apps can migrate across Hive, Cassandra, JSON, … Rich semantics allows query pushdown into data sources Spark SQL users[users.age > 20] select * from users")
41
Examples JSON: JDBC: Together: select user.id, text from tweets { “text”: “hi”, “user”: { “name”: “bob”, “id”: 15 } } tweets.json select age from users where lang = “en” select t.text, u.age from tweets t, users u where t.user.id = u.id and u.lang = “en” Spark SQL {JSON} select id, age from users where lang=“en”

42
To Learn More Get Spark at spark.apache.orgspark.apache.org You can run it on your laptop in local mode Tutorials, MOOCs and news: sparkhub.databricks.com sparkhub.databricks.com Use cases: spark-summit.orgspark-summit.org

Similar presentations














>")




