Download presentation
Presentation is loading. Please wait.

1
Deep Questions without Deep Understanding
Paper Presentation

2
Abstract Develop an approach to generate deep comprehension question from novel text without creating a full semantic representation of text.

3
Deep questions Open ended problems that require deep thinking and recall It requires significant amounts of content rather than a single sentence. Why deep questions? Helps in understanding the text at its fullest and provides greatest educational value Key assessment mechanism for online educational options including MOOCs

4
Approach This paper introduced an ontology-crowd-relevance workflow to generate high level questions. This involves: Decomposing the original text into low dimensional ontology Obtaining high-level question templates from the crowd Retrieving subset of collected templates for a target text segment based on its ontological categories and ranking these questions

5
Example question template
“Who were the key influences on <Person> in their childhood?” is a question template for category: Person and section: Early life

6
Category-section ontology
Freebase “notable type” for each Wikipedia article is used to find the high-level categories. Took 300 most common categories across Wikipedia and then merged these categories into eight broad categories to reduce crowdsourcing effort: Person, Location, Event, Organization, Art, Science, Health, and Religion. These 8 categories cover 78% of Wikipedia articles. Category-section pairs for an article about Albert Einstein contains (Person, Early life), (Person, Awards), and (Person, Political views)
, (Person, Awards), and (Person, Political views)")
7
Crowdsourcing Methodology
Designed a two-stage crowdsourcing pipeline Question generation task: to create question templates that are targeted to set of category-section pairs Question relevance rating task: to obtain binary relevance judgments for the generated question templates in relation to a set of article segments that match in category-section labels. Rating for each question is done on 3 dimensions: relevance, quality and scope.

8
Model Category/section inference
Trained individual logistic regression classifiers for the eight categories and the 50 top section types using the default L2 regularization parameter in LIBLINEAR. Obtained an accuracy of 83% for category and 95% for section.

9
Model Relevance Classification
Used a vector of the component-wise Euclidean distances between individual features of the question and article segment fi=(qi−ai)^2 where qi and ai are the components of the question and article feature vectors. The paper then augmented the vector by concatenating additional distance features between the target article segment and one specific instance of an entire article for which the question applied. Resulting feature vector include first k distances between question tem-plate and the target segment, and the next 𝑘 were between the augmenting article and the target segment. Trained the relevance classifier, a single logistic regression model using LIBLINEAR with default L2 regularization
^2. where qi and ai are the components of the question and article feature vectors. The paper then augmented the vector by concatenating additional distance features between the target article segment and one specific instance of an entire article for which the question applied. Resulting feature vector include first k distances between question tem-plate and the target segment, and the next 𝑘 were between the augmenting article and the target segment. Trained the relevance classifier, a single logistic regression model using LIBLINEAR with default L2 regularization.")
10
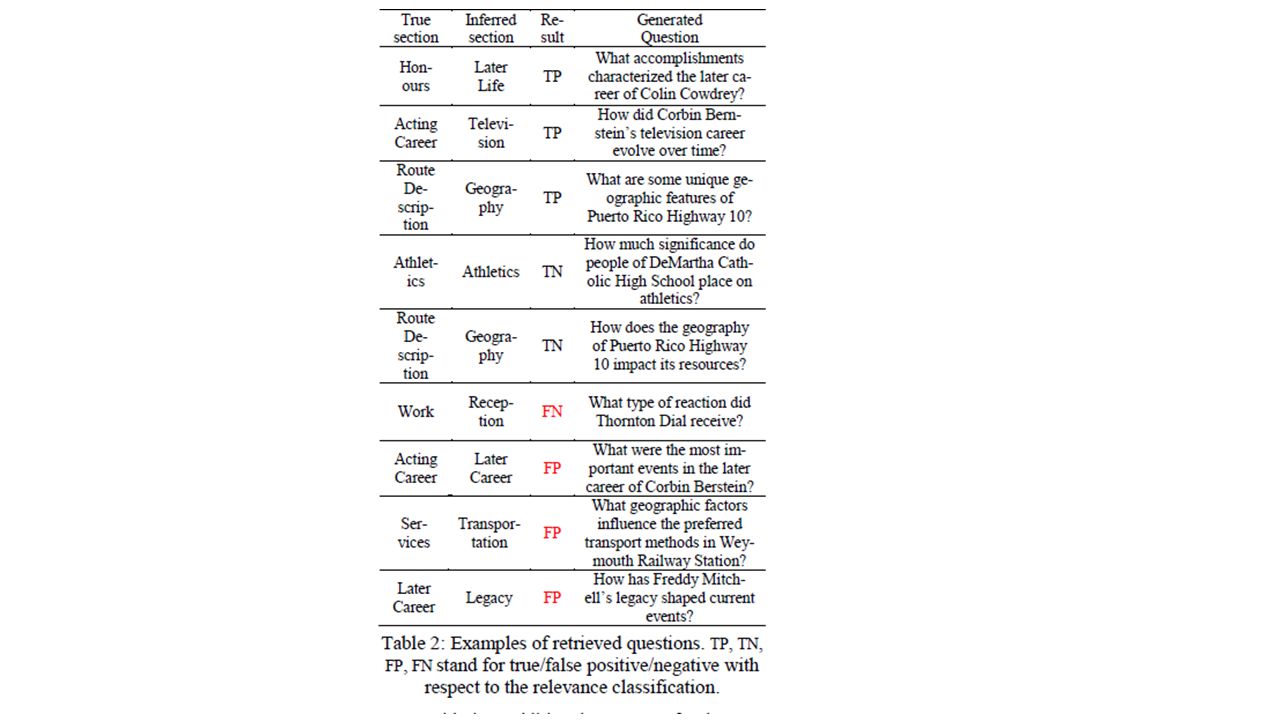
Results

12
The slides are part of paper review for course CS671 This presentation, in no way, claims ownership of any contents in the slides

Similar presentations
>")


















