Download presentation
Presentation is loading. Please wait.

1
Debugging PGI Compilers for Heterogeneous Supercomputing

2
Common OpenACC Errors acc parallel or loop independent errors (not a parallel loop) data bounds errors (not enough data moved to the device) stale data on device or host (missing update) present error (missing data clause somewhere) roundoff error (differences in float arithmetic host vs device) roundoff error for summation (parallel accumulation) async errors (missing wait) compiler error (ask for help) other runtime error (need debugger or other help)
 data bounds errors (not enough data moved to the device) stale data on device or host (missing update) present error (missing data clause somewhere) roundoff error (differences in float arithmetic host vs device) roundoff error for summation (parallel accumulation) async errors (missing wait) compiler error (ask for help) other runtime error (need debugger or other help)")
3
DEBUGGING PGI CUDA FORTRAN AND OPENACC ON GPUS WITH ALLINEA DDT Sebastien Deldon (PGI)- Beau Paisley (Allinea)
- Beau Paisley (Allinea)")
4
TALK HIGHLIGHTS Brief CUDA Fortran overview Brief OpenACC overview CUDA Fortran/OpenACC debug info generation Allinea DDT overview and features CUDA Fortran & OpenACC live debugging demos

5
3 WAYS TO PROGRAM ACCELERATORS

6
attributes(global) subroutine mm_kernel ( A, B, C, N, M, L ) real :: A(N,M), B(M,L), C(N,L), Cij integer, value :: N, M, L integer :: i, j, kb, k, tx, ty real, shared :: Asub(16,16),Bsub(16,16) tx = threadidx%x ty = threadidx%y i = (blockidx%x-1) * 16 + tx j = (blockidx%y-1) * 16 + ty Cij = 0.0 do kb = 1, M, 16 Asub(tx,ty) = A(i,kb+tx-1) Bsub(tx,ty) = B(kb+ty-1,j) call syncthreads() do k = 1,16 Cij = Cij + Asub(tx,k) * Bsub(k,ty) enddo call syncthreads() enddo C(i,j) = Cij end subroutine mmul_kernel real, device, allocatable, dimension(:,:) :: Adev,Bdev,Cdev... allocate (Adev(N,M), Bdev(M,L), Cdev(N,L)) Adev = A(1:N,1:M) Bdev = B(1:M,1:L) call mm_kernel >> ( Adev, Bdev, Cdev, N, M, L) C(1:N,1:L) = Cdev deallocate ( Adev, Bdev, Cdev )... Host CodeDevice Code CUDA FORTRAN
, Bdev(M,L), Cdev(N,L)) Adev = A(1:N,1:M) Bdev = B(1:M,1:L) call mm_kernel >> ( Adev, Bdev, Cdev, N, M, L) C(1:N,1:L) = Cdev deallocate ( Adev, Bdev, Cdev )... Host CodeDevice Code CUDA FORTRAN.")
7
!$CUF KERNEL DIRECTIVES module madd_device_module use cudafor contains subroutine madd_dev(a,b,c,sum,n1,n2) real,dimension(:,:),device :: a,b,c real :: sum integer :: n1,n2 type(dim3) :: grid, block !$cuf kernel do (2) >> do j = 1,n2 do i = 1,n1 a(i,j) = b(i,j) + c(i,j) sum = sum + a(i,j) enddo enddo end subroutine end module module madd_device_module use cudafor implicit none contains attributes(global) subroutine madd_kernel(a,b,c,blocksum,n1,n2) real, dimension(:,:) :: a,b,c real, dimension(:) :: blocksum integer, value :: n1,n2 integer :: i,j,tindex,tneighbor,bindex real :: mysum real, shared :: bsum(256) ! Do this thread's work mysum = 0.0 do j = threadidx%y + (blockidx%y-1)*blockdim%y, n2, blockdim%y*griddim%y do i = threadidx%x + (blockidx%x-1)*blockdim%x, n1, blockdim%x*griddim%x a(i,j) = b(i,j) + c(i,j) mysum = mysum + a(i,j) ! accumulates partial sum per thread enddo enddo ! Now add up all partial sums for the whole thread block ! Compute this thread's linear index in the thread block ! We assume 256 threads in the thread block tindex = threadidx%x + (threadidx%y-1)*blockdim%x ! Store this thread's partial sum in the shared memory block bsum(tindex) = mysum call syncthreads() ! Accumulate all the partial sums for this thread block to a single value tneighbor = 128 do while( tneighbor >= 1 ) if( tindex = 1 ) if( tindex >>(a,b,c,blocksum,n1,n2) call madd_sum_kernel >>(blocksum,dsum,nb) r = cudaThreadSynchronize() ! don't deallocate too early deallocate(blocksum) end subroutine end module Equivalent hand-written CUDA kernels
*blockdim%y, n2, blockdim%y*griddim%y do i = threadidx%x + (blockidx%x-1)*blockdim%x, n1, blockdim%x*griddim%x a(i,j) = b(i,j) + c(i,j) mysum = mysum + a(i,j) . accumulates partial sum per thread enddo enddo . Now add up all partial sums for the whole thread block . Compute this thread s linear index in the thread block . We assume 256 threads in the thread block tindex = threadidx%x + (threadidx%y-1)*blockdim%x . Store this thread s partial sum in the shared memory block bsum(tindex) = mysum call syncthreads() . Accumulate all the partial sums for this thread block to a single value tneighbor = 128 do while( tneighbor >= 1 ) if( tindex = 1 ) if( tindex >>(a,b,c,blocksum,n1,n2) call madd_sum_kernel >>(blocksum,dsum,nb) r = cudaThreadSynchronize() . don t deallocate too early deallocate(blocksum) end subroutine end module Equivalent hand-written CUDA kernels.")
8
OPENACC MEMBERS

9
... #pragma acc data copy(b[0:n][0:m]) \ create(a[0:n][0:m]) { for (iter = 1; iter <= p; ++iter){ #pragma acc kernels { for (i = 1; i < n-1; ++i){ for (j = 1; j < m-1; ++j){ a[i][j]=w0*b[i][j]+ w1*(b[i-1][j]+b[i+1][j]+ b[i][j-1]+b[i][j+1])+ w2*(b[i-1][j-1]+b[i-1][j+1]+ b[i+1][j-1]+b[i+1][j+1]); } } for( i = 1; i < n-1; ++i ) for( j = 1; j < m-1; ++j ) b[i][j] = a[i][j]; }... S 2 (B) S 1 (B) S 2 (B) OPENACC Host Memory Accelerator Memory AA BB S 1 (B) S p (B)
 \ create(a[0:n][0:m]) { for (iter = 1; iter <= p; ++iter){ #pragma acc kernels { for (i = 1; i < n-1; ++i){ for (j = 1; j < m-1; ++j){ a[i][j]=w0*b[i][j]+ w1*(b[i-1][j]+b[i+1][j]+ b[i][j-1]+b[i][j+1])+ w2*(b[i-1][j-1]+b[i-1][j+1]+ b[i+1][j-1]+b[i+1][j+1]); } } for( i = 1; i < n-1; ++i ) for( j = 1; j < m-1; ++j ) b[i][j] = a[i][j]; }... S 2 (B) S 1 (B) S 2 (B) OPENACC Host Memory Accelerator Memory AA BB S 1 (B) S p (B).")
10
HOW DOES THE PGI ACCELERATOR COMPILER WORK? Unified CPU/GPU binary C/C++/Fortran OpenACC Cuda Fortran Code compile PGI Accelerator compiler Device X86 ASM CUDA C NVIDIA SDK nvcc GPU ASM PGI Accelerator linker link Host

11
NATIVE LLVM CODE GENERATION TO ENABLE DEBUGGING Unified CPU/GPU binary C/C++/Fortran OpenACC Cuda Fortran Code compile PGI Accelerator compiler Device X86 ASM NVVM IR NVIDIA SDK libnvvm GPU ASM PGI Accelerator linker link Host

12
ENABLING DEVICE-SIDE DEBUGGING PGI Accelerator native NVVM IR/libnvvm code generator Generate debug info using NVVM IR debug metadata —Source line correlation —Global/local variables Debug info for CUDA predefined variables (threadIdx, …) Debug info for Fortran-specific features
 Debug info for Fortran-specific features")
13
CUDA FORTRAN DEBUGGING STATUS CUDA Fortran debugging features in PGI 14.1 and later One-to-one mapping for source line correlation Set and run to breakpoints in CUDA Fortran kernels Step through kernel code Examine kernel local variables, global variables in device/shared memories, predefined variables

14
CUDA FORTRAN DEBUGGING LIMITATIONS Lower optimization level when invoking libnvvm – code generation may chang Array bounds debug information only for constant !$CUF directive support available with PGI 14.4

15
OpenACC debug challenges void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mmul % ddt … extern "C" __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code
![OpenACC debug challenges void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mmul % ddt … extern C __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code](http://images.slideplayer.com/26/8870304/slides/slide_15.jpg "OpenACC debug challenges void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mmul % ddt … extern C __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code")
16
OPENACC DEBUG CHALLENGE Source line correlation Variable correlation Variable not referenced anymore Do we expose compiler-created variables ? How to deal with significantly restructured loops ? extern "C" __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Simplified Pseudo Kernel Code
 void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Simplified Pseudo Kernel Code.")
17
OPENACC DEBUG STATUS Available in PGI 14.4 Source line correlation Debug support for variables turned into kernel parameters !$CUF directives debug support

18
OPENACC DEBUG LIMITATIONS Same as for CUDA Fortran debugging No support for source variables that are not referenced by generated kernel No support for generated for common block variable passed as parameters Limited support for acc routines

19
ABOUT ALLINEA DDT Graphical debugger designed for: —C/C++, Fortran, UPC, CUDA, CUDA Fortran —Multithreaded code Single address space —Multiprocess code Interdependent or independent processes —Accelerated codes GPUs, Intel Xeon Phi Any mix of the above Slash your time to debug : —Reproduces and triggers your bugs instantly —Helps you easily understand where issues come from quickly —Helps you to fix them as swiftly as possible

20
LET’S SEE DDT IN ACTION

21
idata Global Memory CUDA FORTRAN DEBUG DEMO attributes(global) subroutine transposeNoBankConflicts(odata, idata) implicit none real, intent(out) :: odata(ny,nx) real, intent(in) :: idata(nx,ny) real, shared :: tile(TILE_DIM+1, TILE_DIM) integer :: x, y, j x = (blockIdx%x-1) * TILE_DIM + threadIdx%x y = (blockIdx%y-1) * TILE_DIM + threadIdx%y do j = 0, TILE_DIM-1, BLOCK_ROWS tile(threadIdx%x, threadIdx%y+j) = idata(x,y+j) end do call syncthreads() x = (blockIdx%y-1) * TILE_DIM + threadIdx%x y = (blockIdx%x-1) * TILE_DIM + threadIdx%y do j = 0, TILE_DIM-1, BLOCK_ROWS odata(x,y+j) = tile(threadIdx%y+j, threadIdx%x) end do end subroutine transposeNoBankConflicts http:// devblogs.nvidia.com/parallelforall/efficient-matrix-transpose-cuda-fortran / % pgfortran –g –O0 –Mcuda mtrans.cuf –o mtrans % ddt … tile Shared Memory odata Global Memory
 subroutine transposeNoBankConflicts(odata, idata) implicit none real, intent(out) :: odata(ny,nx) real, intent(in) :: idata(nx,ny) real, shared :: tile(TILE_DIM+1, TILE_DIM) integer :: x, y, j x = (blockIdx%x-1) * TILE_DIM + threadIdx%x y = (blockIdx%y-1) * TILE_DIM + threadIdx%y do j = 0, TILE_DIM-1, BLOCK_ROWS tile(threadIdx%x, threadIdx%y+j) = idata(x,y+j) end do call syncthreads() x = (blockIdx%y-1) * TILE_DIM + threadIdx%x y = (blockIdx%x-1) * TILE_DIM + threadIdx%y do j = 0, TILE_DIM-1, BLOCK_ROWS odata(x,y+j) = tile(threadIdx%y+j, threadIdx%x) end do end subroutine transposeNoBankConflicts devblogs.nvidia.com/parallelforall/efficient-matrix-transpose-cuda-fortran / % pgfortran –g –O0 –Mcuda mtrans.cuf –o mtrans % ddt … tile Shared Memory odata Global Memory")
22
OpenACC debug demo void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mm % ddt … extern "C" __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code
![OpenACC debug demo void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mm % ddt … extern C __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code](http://images.slideplayer.com/26/8870304/slides/slide_22.jpg "OpenACC debug demo void MatrixMultiplication( float * restrict a, float * restrict b, float * restrict c, int m, int n, int p) { int i, j, k ; #pragma acc data copy(a[0:(m*n)]), copyin(b[0:(m*p)],c[0:(p*n)]) { #pragma acc kernels loop independent, gang, vector(8) for (i=0; i<m; i++){ #pragma acc loop gang, vector (8) for (j=0; j<n; j++) { #pragma acc loop seq for (k=0; k<p; k++) a[i*n+j] += b[i*p+k]*c[k*n+j] ; } % pgcc –g –O0 –ta=nvidia –acc mmul.c –o mm % ddt … extern C __global__ __launch_bounds__(64) void MatrixMultiplication_20_gpu( float* const __restrict _c ; float* const __restrict _b, float* _a, int _n, int _p) { int _i, _j, _k ; _i = threadIdx.y + blockIdx.y*8 ; _j = threadIdx.x + blockIdx.x*8 ; for (_k=0; _k<_p; _k++) _a [_i*_n+_j] += _b[_i*_p+_k]*_c [_k*_n+_j] ; } Original Source Code Simplified Pseudo Kernel Code")
23
COPYRIGHT NOTICE © Contents copyright 2014, NVIDIA Corporation. This material may not be reproduced in any manner without the expressed written permission of NVIDIA. PGFORTRAN, PGF95, PGI Accelerator and PGI Unified Binary are trademarks, and PGI, PGCC, PGC++, PGI Visual Fortran, PVF, PGI CDK, Cluster Development Kit, PGPROF, PGDBG, and The Portland Group are registered trademarks of NVIDIA Corporation. Other brands and names are the property of their respective owners.

24
BACKUP SLIDES

25
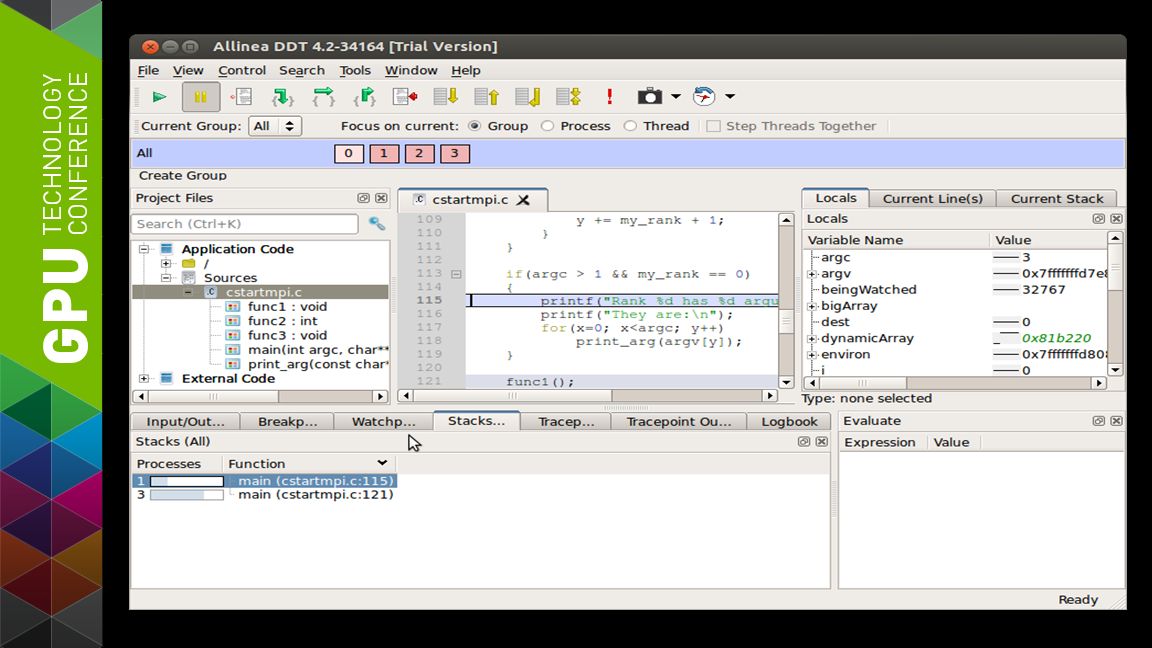
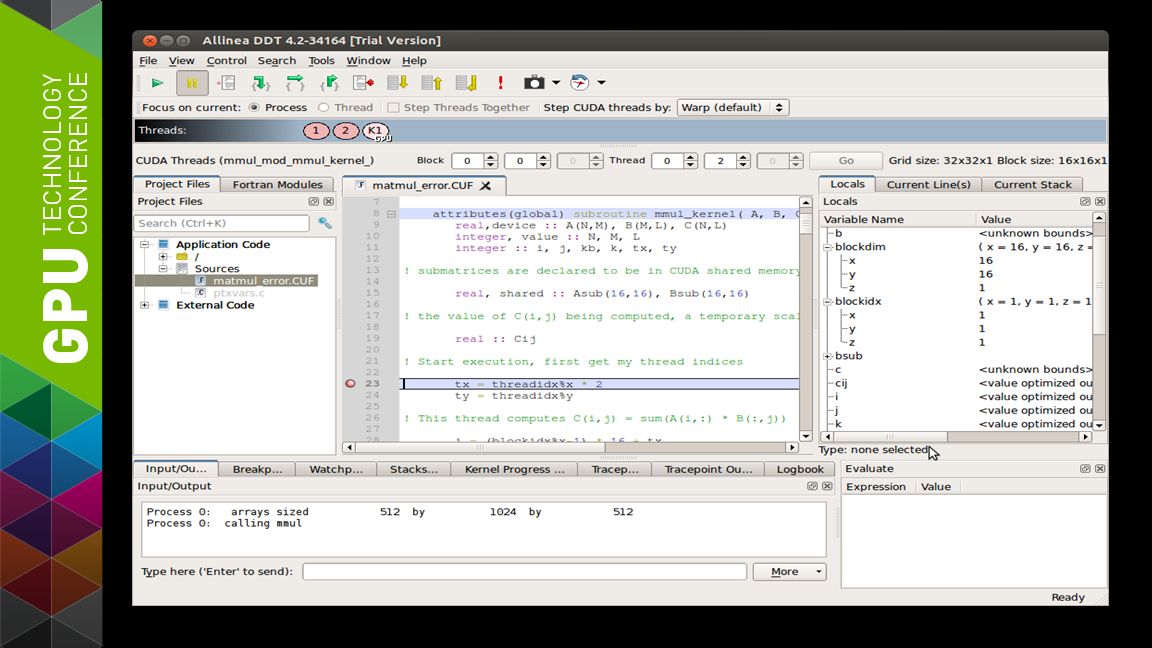
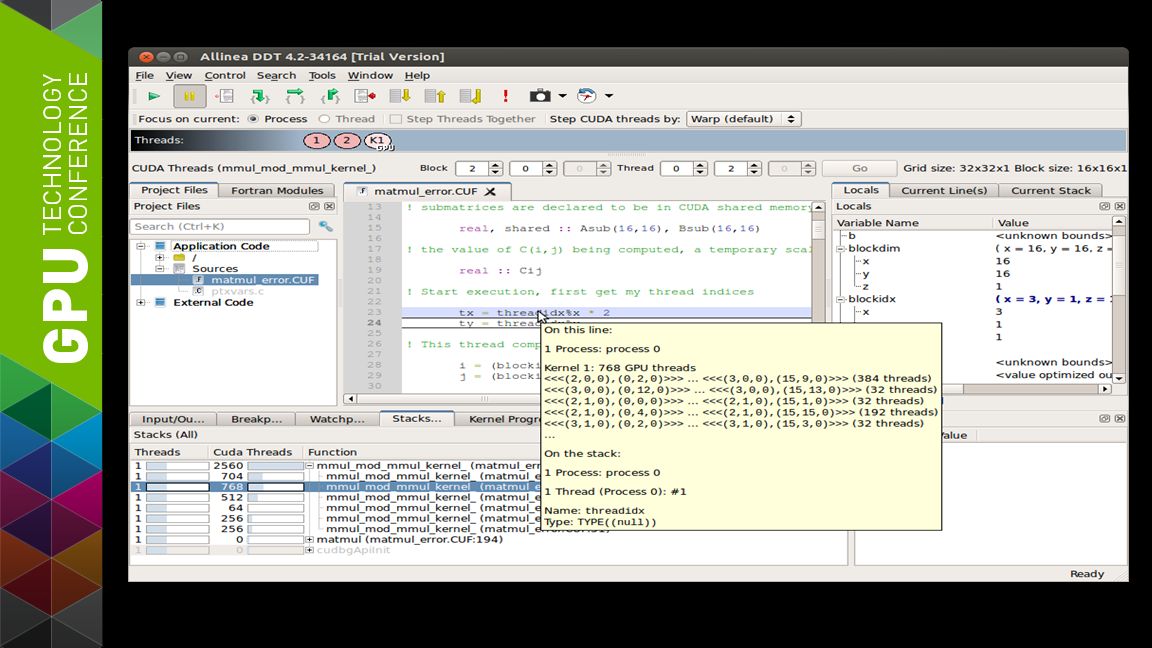
25 Debugging CUDA Fortran with Allinea DDT Set and run to breakpoints in CUDA Fortran kernels View CUDA Fortran kernels source code Drill into CUDA thread-blocks to examine local variables Evaluate data in device shared/global memories Track execution stacks for CUDA threads/blocks

26
26 View arrays in device shred/global memory

27
27 Inspect values in CUDA Fortran multidimensional arrays

28
28 Vizualize values in CUDA Fortran multidimensional arrays

29
29 View C source code Track CUDA thread/blocks execution stack in OpenACC kernel Set and run to breakpoints in OpenACC parallel region Examine OpenACC kernel local variables in device memory

30
30 Inspect values in OpenACC multidimensional arrays

37
TRAP ERROR WHERE IT OCCURRED

Similar presentations





 real :: x(:), y(:), a integer :: n, i $!acc kernels do i=1,n y(i) = a*x(i)+y(i) enddo.>")






 Supercomputing for the Masses by Peter Zalutski.>")
. Code executed on GPU.>")

 1 A short introduction to nVidia‘s CUDA Alexander Heinecke Technical University of Munich>")






