Download presentation
Presentation is loading. Please wait.

1
BlinkDB: Queries with Bounded Errors and Bounded Response Times on Very Large Data ACM EuroSys 2013 (Best Paper Award)
")
2
Motivation Support interactive SQL-like aggregate queries over massive sets of data

3
Feature Most queries focus on global message of the whole table. blinkdb> SELECT AVG(jobtime) FROM very_big_log AVG, COUNT, SUM, STDEV, PERCENTILE etc.
 FROM very_big_log AVG, COUNT, SUM, STDEV, PERCENTILE etc..")
4
Where and group semantics focus on limited clauses. blinkdb> SELECT AVG(jobtime) FROM very_big_log WHERE src = ‘hadoop’ FILTERS, GROUP BY clauses Feature
 FROM very_big_log WHERE src = ‘hadoop’ FILTERS, GROUP BY clauses Feature.")
5
Hard Disks ½ - 1 Hour1 - 5 Minutes1 second ? Memory 100 TB on 1000 machines Query Execution on Samples

6
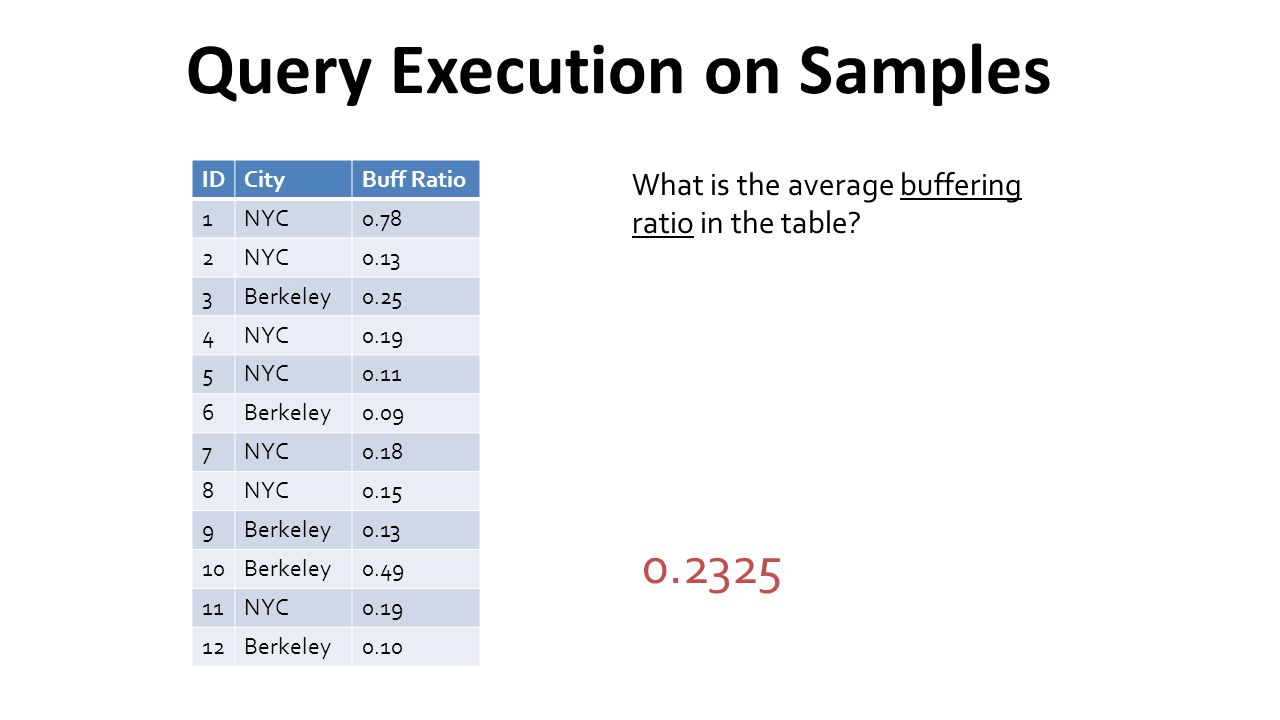
IDCityBuff Ratio 1NYC0.78 2NYC0.13 3Berkeley0.25 4NYC0.19 5NYC0.11 6Berkeley0.09 7NYC0.18 8NYC0.15 9Berkeley0.13 10Berkeley0.49 11NYC0.19 12Berkeley0.10 Query Execution on Samples What is the average buffering ratio in the table? 0.2325
7
IDCityBuff Ratio 1NYC0.78 2NYC0.13 3Berkeley0.25 4NYC0.19 5NYC0.11 6Berkeley0.09 7NYC0.18 8NYC0.15 9Berkeley0.13 10Berkeley0.49 11NYC0.19 12Berkeley0.10 Query Execution on Samples What is the average buffering ratio in the table? IDCityBuff RatioSampling Rate 2NYC0.131/4 6Berkeley0.251/4 8NYC0.191/4 Uniform Sample 0.19 0.2325

8
IDCityBuff Ratio 1NYC0.78 2NYC0.13 3Berkeley0.25 4NYC0.19 5NYC0.11 6Berkeley0.09 7NYC0.18 8NYC0.15 9Berkeley0.13 10Berkeley0.49 11NYC0.19 12Berkeley0.10 Query Execution on Samples What is the average buffering ratio in the table? IDCityBuff RatioSampling Rate 2NYC0.131/4 6Berkeley0.251/4 8NYC0.191/4 Uniform Sample 0.19 +/- 0.05 0.2325

9
IDCityBuff Ratio 1NYC0.78 2NYC0.13 3Berkeley0.25 4NYC0.19 5NYC0.11 6Berkeley0.09 7NYC0.18 8NYC0.15 9Berkeley0.13 10Berkeley0.49 11NYC0.19 12Berkeley0.10 Query Execution on Samples What is the average buffering ratio in the table? IDCityBuff RatioSampling Rate 2NYC0.131/2 3Berkeley0.251/2 5NYC0.191/2 6Berkeley0.091/2 8NYC0.181/2 12Berkeley0.491/2 Uniform Sample $0.22 +/- 0.02 0.2325 0.19 +/- 0.05

10
Speed/Accuracy Trade-off Error 30 mins Time to Execute on Entire Dataset Interactive Queries 2 sec Execution Time (Sample Size)
")
11
Error 30 mins Time to Execute on Entire Dataset Interactive Queries 2 sec Speed/Accuracy Trade-off Pre-Existing Noise Execution Time (Sample Size)
")
12
Sampling Vs. No Sampling 1 10 -1 10 -2 10 -3 10 -4 10 -5 Fraction of full data Query Response Time (Seconds) 103 1020 1813 108 10x as response time is dominated by I/O 10x as response time is dominated by I/O
 x as response time is dominated by I/O 10x as response time is dominated by I/O.")
13
Sampling Vs. No Sampling 1 10 -1 10 -2 10 -3 10 -4 10 -5 Fraction of full data Query Response Time (Seconds) 103 1020 1813 108 (0.02%) (0.07%)(1.1%)(3.4%) (11%) Error Bars
 (0.02%) (0.07%)(1.1%)(3.4%) (11%) Error Bars.")
14
What is BlinkDB? A framework built on Shark and Spark that … -creates and maintains a variety of uniform and stratified samples from underlying data -returns fast, approximate answers with error bars by executing queries on samples of data -verifies the correctness of the error bars that it returns at runtime

15
BlinkDB Background System Overview Sample Creation BlinkDB Runtime Inplementation & Evaluation

16
Background One common assumption is that future queries will be similar to historical queries. The meaning of “similarity” can differ. This choice of model of past workloads is one of the key differences between BlinkDB and prior work

17
Workload Taxonomy

19
System overview BlinkDB extends the Apache Hive frame work by adding two major components to it: (1)an offline sampling module that creates and maintains samples over time (2) a run-time sample selection module that creates an Error-Latency Profile(ELP) for queries
an offline sampling module that creates and maintains samples over time (2) a run-time sample selection module that creates an Error-Latency Profile(ELP) for queries")
20
Supported queries standard SQL aggregate queries involving COUNT, AVG, SUM and QUANTILE. Queries involving these operations can be annotated with either an error bound, or a time constraint. Nested or joines queries not supported yet, but not a hindrance

21
It would also be straight forward to extend BlinkDB to deal with foreign keyjoins between two sampled tables (or a self join on one sampled table) where both tables have a stratified sample on the set of columns used for joins.
 where both tables have a stratified sample on the set of columns used for joins.")
22
Sample Creation Why Stratified samples are useful? Samples carry storage costs, so we can only build a limited number of them.

23
Stratified Samples when uniform sample is useful? when uniform sample is useful A uniform sample may not contain any members of the subset at all, leading to a missing row in the final output of the query.

24
Stratified Samples for a single query

25
This problem has been studied before. Briefly, since error decreases at a decreasing rate as sample size increases, the best choices imply assigns equal sample size to each groups. In addition, the assignment of sample sizes is deterministic.

26
[16] S. Lohr. Sampling: design and analysis. Thomson, 2009. K=
![[16] S. Lohr. Sampling: design and analysis. Thomson, K=](http://images.slideplayer.com/26/8781482/slides/slide_26.jpg "[16] S. Lohr. Sampling: design and analysis. Thomson, K=")
27
Optimizing a set of stratified samples for all queries sharing a QCS n will change through queries.

28
Columns selection optimization In practice, we set M=K=100000

29
can also be useful by partially covering q j

30
The size of this optimization problem increases exponentially with the number of columns in T, which looks worrying. However, it is possible to solve these problems in practice by applying some simple optimizations, like considering only column sets that actually occurred in the past queries, or eliminating column sets that are unrealistically large.

31
BlinkDB Runtime

32
Predict mainly based on: 1. For all standard SQL aggregates, the variance is proportional to ∼ 1/n, and thus the standard deviation (or the statistical error) is proportional to ∼ 1/√n 2. BlinkDB simply predicts n by assuming that latency scales linearly with input size, as is commonly observed with a majority of I/O bounded queries in parallel distributed execution environments.
 is proportional to ∼ 1/√n 2. BlinkDB simply predicts n by assuming that latency scales linearly with input size, as is commonly observed with a majority of I/O bounded queries in parallel distributed execution environments..")
33
Bias correction use stratified sample to simulate a normal sample by trace the sample rate of every group.

34
Inplementation Enables queries with response time and error bounds Creates or updates the set of random and multi-dimensional samples re-writes the query and iteratively assigns it an appropriately sized uniform or stratified sample Modify all pre-existing aggregation functions with statistical closed forms to return errors bars and confidence intervals in addition to there result.

35
Sample refresh inaccuracies in analysis based on multiple queries. Multiple queries on unchanged biased sample will not help to convergence. periodically( typically, daily) samples from the original data to avoid correlation among the answers to queries which use the same sample.
 samples from the original data to avoid correlation among the answers to queries which use the same sample..")
36
IDCityBuff Ratio 1NYC0.78 2NYC0.13 3Berkeley0.25 4NYC0.19 5NYC0.11 6Berkeley0.09 7NYC0.18 8NYC0.15 9Berkeley0.13 10Berkeley0.49 11NYC0.19 12Berkeley0.10 Query Execution on Samples IDCityBuff RatioSampling Rate 2NYC0.131/4 6Berkeley0.251/4 8NYC0.191/4 Uniform Sample 0.19 0.2325

37
Time cost for sample uniform samples are generally created in a few hundred seconds. creating stratified samples on a set of columns takes anywhere between a 5− 30 minutes depending on the number of unique values to stratify on, which decides the number of reducers and the amount of data shuffled.

38
Evaluation workloads and sample storage cost QCS choices change through the storage budget

39
Response time improvement by sample

40
Error by different samples

41
Error Convergence

42
Time and error bound

43
Scaling Up Highly selective queries Those queries that only operate on a small fraction of input data consist of one or more highly selective WHERE clauses those queries that are intended to crunch huge amounts of data Average among x=2 Average among all the data

44
Conclusion BlinkDB, a parallel, sampling-based approximate query engine that provides support for ad-hoc queries with error and response time constraints two key ideas: (i) a multi-dimensional sampling strategy that builds and maintains a variety of samples. (ii) a run-time dynamic sample selection strategy that uses parts of a sample to estimate query selectivity and chooses the best samples for satisfying query constraints. Answer a “range” of queries within 2 seconds on 17 TB of data with 90-98% accuracy.
 a run-time dynamic sample selection strategy that uses parts of a sample to estimate query selectivity and chooses the best samples for satisfying query constraints. Answer a range of queries within 2 seconds on 17 TB of data with 90-98% accuracy..")
Similar presentations




















