Download presentation
Presentation is loading. Please wait.

1
EECS 274 Computer Vision Model Fitting

2
Fitting Choose a parametric object/some objects to represent a set of points Three main questions: –what object represents this set of points best? –which of several objects gets which points? –how many objects are there? (you could read line for object here, or circle, or ellipse or...) Reading: FP Chapter 15
 Reading: FP Chapter 15.")
3
Fitting and the Hough transform Purports to answer all three questions –in practice, answer isn’t usually all that much help We do for lines only A line is the set of points (x, y) such that Different choices of , d>0 give different lines For any (x, y) there is a one parameter family of lines through this point, given by Each point gets to vote for each line in the family; if there is a line that has lots of votes, that should be the line passing through the points
 such that Different choices of , d>0 give different lines For any (x, y) there is a one parameter family of lines through this point, given by Each point gets to vote for each line in the family; if there is a line that has lots of votes, that should be the line passing through the points")
4
tokens votes 20 points 200 bins in each direction # of votes is indicated by the pixel brightness Maximum votes is 20 Note that most points in the vote array are very dark, because they get only one vote.

5
Hough transform Construct an array representing , r For each point, render the curve ( , r) into this array, adding one at each cell Difficulties –Quantization error: how big should the cells be? (too big, and we cannot distinguish between quite different lines; too small, and noise causes lines to be missed) –Difficulty with noise How many lines? –count the peaks in the Hough array Who belongs to which line? –tag the votes Hardly ever satisfactory in practice, because problems with noise and cell size defeat it
 –Difficulty with noise How many lines. –count the peaks in the Hough array Who belongs to which line. –tag the votes Hardly ever satisfactory in practice, because problems with noise and cell size defeat it.")
6
points votes Add random noise ([0,0.05]) to each point. Maximum vote is now 6
![points votes Add random noise ([0,0.05]) to each point. Maximum vote is now 6](http://images.slideplayer.com/26/8770965/slides/slide_6.jpg "points votes Add random noise ([0,0.05]) to each point. Maximum vote is now 6")
7
points votes

8
As noise increases, # of max votes decreases difficult to use Hough transform less robustly

9
As noise increase, # of max votes in the right bucket goes down, and it is more likely to obtain a large spurious vote in the accumulator Can be quite difficult to find a line out of noise with Hough transform as the # of votes for the line may be comparable with the # of vote for a spurious line

10
Choice of model Least squares but assumes error appears only in yTotal least squares

11
Who came from which line? Assume we know how many lines there are - but which lines are they? –easy, if we know who came from which line Three strategies –Incremental line fitting –K-means –Probabilistic (later!)
.")
14
Fitting curves other than lines In principle, an easy generalisation –The probability of obtaining a point, given a curve, is given by a negative exponential of distance squared In practice, rather hard –It is generally difficult to compute the distance between a point and a curve

15
Implicit curves (u,v) on curve, i.e., ϕ (u,v)=0 s=(dx,dy)-(u,v) is normal to the curve
 on curve, i.e., ϕ (u,v)=0 s=(dx,dy)-(u,v) is normal to the curve")
16
Robustness As we have seen, squared error can be a source of bias in the presence of noise points –One fix is EM - we’ll do this shortly –Another is an M-estimator Square nearby, threshold far away –A third is RANSAC Search for good points

17
Missing data So far we assume we know which points belong to the line In practice, we may have a set of measured points –some of which from a line, –and others of which are noise Missing data (or label)
")
18
Least squares fits the data well

19
Single outlier (x-coordinate is corrupted) affects the least-squares result
 affects the least-squares result")
20
Single outlier (y-coordinate is corrupted) affects the least-squares result
 affects the least-squares result")
21
Bad fit

22
Heavy tail, light tail The red line represents a frequency curve of a long tailed distribution. The blue line represents a frequency curve of a short tailed distribution. The black line is the standard bell curve..

23
M-estimators Often used in robust statistics A point that is several away from the fitted curve will have no effect on the coefficients

24
Other M-estimators Defined by influence function Nonlinear function, solved iteratively Iterative strategy –Draw a subset of samples randomly –Fit the subset using least squares –Use the remaining points to see fitness Need to pick a sensible σ, which is referred as scale Estimate scale at each iteration

25
Appropriate σ

26
small σ

27
large σ

28
Matching features What do we do about the “bad” matches? Szeliski

29
RAndom SAmple Consensus Select one match, count inliers

30
RAndom SAmple Consensus Select one match, count inliers

31
Least squares fit Find “average” translation vector

32
RANSAC Random Sample Consensus Choose a small subset uniformly at random Fit to that Anything that is close to result is signal; all others are noise Refit Do this many times and choose the best Issues –How many times? Often enough that we are likely to have a good line –How big a subset? Smallest possible –What does close mean? Depends on the problem –What is a good line? One where the number of nearby points is so big it is unlikely to be all outliers

34
Richard Szeliski Image Stitching34 Descriptor Vector Orientation = blurred gradient Similarity Invariant Frame –Scale-space position (x, y, s) + orientation ( )
 + orientation ( )")
35
RANSAC for Homography

38
Probabilistic model for verification

39
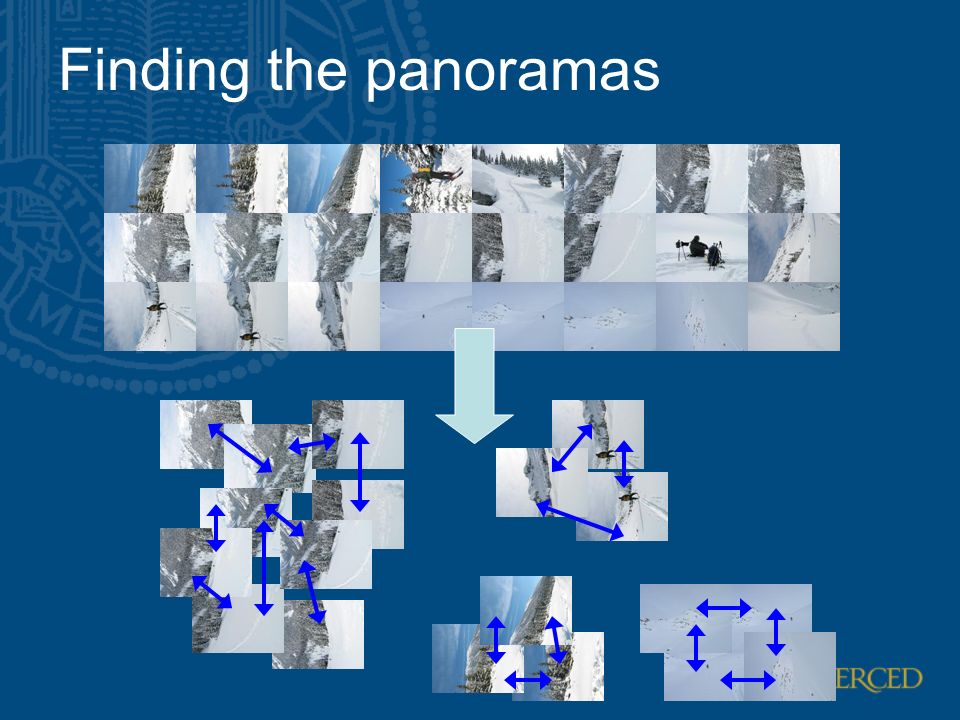
Finding the panoramas

42
Results

Similar presentations









>")














 15-463: Computational Photography Alexei Efros, CMU, Fall 2006 with a lot of slides stolen from Steve Seitz and.>")
