Download presentation
Presentation is loading. Please wait.

1
Multi-core Acceleration of NWP John Michalakes, NCAR John Linford, Virginia Tech Manish Vachharajani, University of Colorado Adrian Sandu, Virginia Tech HPC Users Forum, September 10, 2009

2
Outline WRF and multi-core overview Cost breakdown and kernel repository Two cases Path forward

3
WRF Overview Large collaborative effort to develop community weather model –10000+ registered users –Applications Numerical Weather Prediction High resolution climate Air quality research/prediction Wildfire Atmospheric Research Software designed for HPC –Ported to and in use on virtually all types of system in the Top500 –2007 Gordon Bell finalist Why acceleration? –Exploit fine-grained parallelism –Cost performance ($ and e - ) –Need for strong scaling 5 day global WRF forecast at 20km horizontal resolution
 –Need for strong scaling 5 day global WRF forecast at 20km horizontal resolution.")
4
WRF Overview Large collaborative effort to develop community weather model –10000+ registered users –Applications Numerical Weather Prediction High resolution climate Air quality research/prediction Wildfire Atmospheric Research Software designed for HPC –Ported to and in use on virtually all types of system in the Top500 –2007 Gordon Bell finalist Why acceleration? –Exploit fine-grained parallelism –Cost performance ($ and e - ) –Need for strong scaling courtesy Peter Johnsen, Cray
 –Need for strong scaling courtesy Peter Johnsen, Cray.")
5
Multi-/Many-core Graphics Processing Units –NVIDIA GTX280, AMD –High-end versions of commodity graphics cards –O(100) physical SIMD cores supporting O(1000) way concurrent threads –Separate co-processor to host CPU, PCIe connection –Large register files, fast (but very small) shared memory –Programmed using special purpose threading languages: CUDA, OpenCL –Higher-level language support in development (e.g. PGI 9) “Traditional” multi-core –Xeon 5500, Opteron Istanbul, Power 6/7 –Much improved memory b/w (5x on Stream * ) –Hyperthreading/SMT –Includes heterogeneity in the form of SIMD units & instructions –x86 instruction set; Native C, Fortran, OpenMP,... Cell Broadband Engine –PowerXCell 8i –PowerPC with 8 co-processors on a chip –No shared memory but relatively large local stores per core –Cores separately programmed; all computation and data movement programmer controlled * http://www.advancedclustering.com/company-blog/stream-benchmarking.html
 Traditional multi-core –Xeon 5500, Opteron Istanbul, Power 6/7 –Much improved memory b/w (5x on Stream * ) –Hyperthreading/SMT –Includes heterogeneity in the form of SIMD units & instructions –x86 instruction set; Native C, Fortran, OpenMP,... Cell Broadband Engine –PowerXCell 8i –PowerPC with 8 co-processors on a chip –No shared memory but relatively large local stores per core –Cores separately programmed; all computation and data movement programmer controlled *")
6
Percentages of total run time (single processor profile) WRF Cost Breakdown and Kernel Repository www.mmm.ucar.edu/wrf/WG2/GPU
 WRF Cost Breakdown and Kernel Repository")
7
WSM5 Microphysics WRF Single Moment 5-Tracer (WSM5) * scheme Represents condensation, precipitation, and thermodynamic effects of latent heat release Operates independently up each column of 3D WRF domain Expensive and relatively computationally intense (~2 ops per word) * Hong, S., J. Dudhia, and S. Chen (2004). Monthly Weather Review, 132(1):103-120.
. Monthly Weather Review, 132(1):")
8
WSM5 Microphysics contributed by Roman Dubtsov, Intel

9
WSM5 Microphysics CUDA version distributed with WRFV3 Users have seen 1.2-1.3x improvement –Case/system dependent –Makes other parts of code run faster (!) PGI has implemented with 9.0 acceleration directives and seen comparable speedups and overheads from transfer cost WRF CONUS 12km benchmark Courtesy Brent Leback and Craig Toepfer, PGI total seconds microphysics
 PGI has implemented with 9.0 acceleration directives and seen comparable speedups and overheads from transfer cost WRF CONUS 12km benchmark Courtesy Brent Leback and Craig Toepfer, PGI total seconds microphysics")
10
Kernel: WRF-Chem WRF model coupled to atmospheric chemistry for air quality research and air pollution forecasting –Time evolution and advection of tens to hundreds of chemical species being produced and consumed at varying rates in networks of reactions –Many times cost of core meteorology; seemingly ideal for acceleration * Grell et al., WRF Chem Version 3.0 User’s Guide, http://ruc.fsl.noaa.gov/wrf/WG11 ** Hairer E. and G. Wanner. Solving ODEs II: Stiff and Differential-Algebraic Problems, Springer 1996. *** Damian, et al. (2002). Computers & Chemical Engineering 26, 1567-1579.
. Computers & Chemical Engineering 26,")
11
Kernel: WRF-Chem Rosenbrock solver for stiff system of ODEs at each cell –Rosenbrock ** solver for stiff system of ODEs at each cell –Computation at each cell independent – perfectly parallel –Solver itself is not parallelizable –600K fp ops per cell (compare to 5K ops/cell for meteorology) –1-million load-stores per cell –Very large footprint: 15KB state at each cell
 –1-million load-stores per cell –Very large footprint: 15KB state at each cell")
12
! OMP PARALLEL DO J = 1,... DO K = 1,... DO I = 1,... Kernel: WRF-Chem KPP generates Fortran solver called at each grid-cell in 3D domain Multi-core implementation –Insert OpenMP directives and multithread loop over grid cells

13
Kernel: WRF-Chem Cell BE implementation –PPU acts as master, invoking SPEs cell-by-cell –SPUs round robin through domain, triple buffering –Enhancement: SPUs process cells in blocks of four Cell-index innermost in blocks, utilize SIMD

14
Kernel: WRF-Chem GPU implementation –Host CPU controls outer loop over steps in Rosenbrock algorithm –Each step implemented as kernel over all cells in domain –Thread-shared memory utilized where possible (but not much) –Cells are masked out of the computation as they reach convergence –Cell index (thread index) innermost for coalesced access to device memory kernel invocation GPU CPU kernel invocation
 –Cells are masked out of the computation as they reach convergence –Cell index (thread index) innermost for coalesced access to device memory kernel invocation GPU CPU kernel invocation")
15
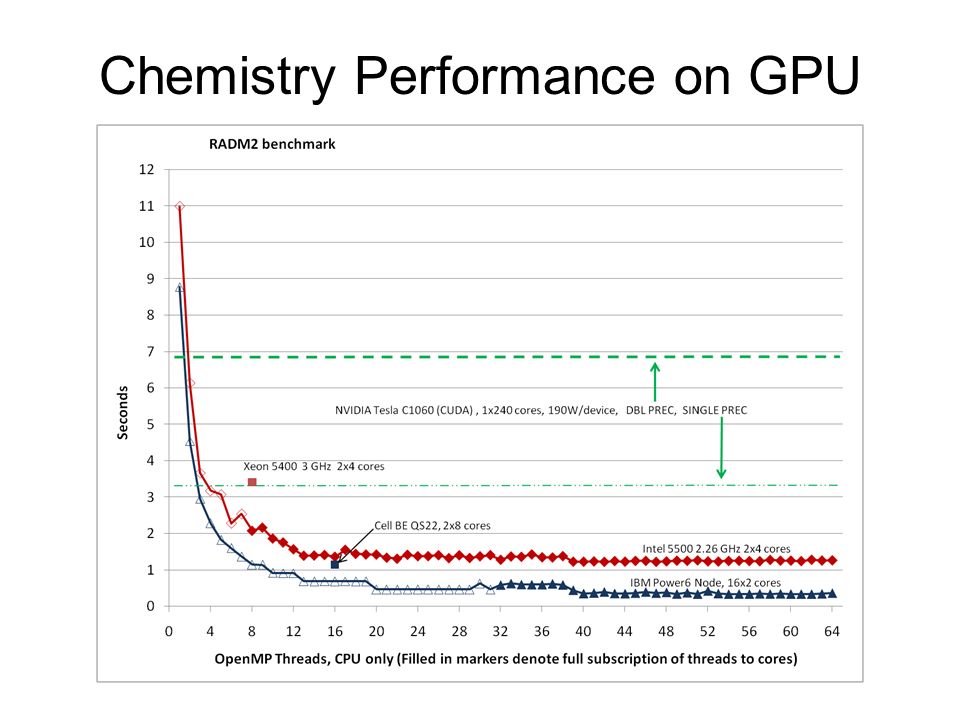
Chemistry Performance on GPU

17
Some preliminary conclusions Chemistry kinetics –Very expensive but not computationally intense, so data movement costs are high and memory footprint is very large (15K bytes per cell) –Each Cell BE core has local store large enough to allow effective overlap of computation and communication –Today’s GPUs have ample device memory bandwidth, but there is not enough fast local memory for working set –Xeon 5500, Power6 have sufficient cache, concurrency, and bandwidth WRF Microphysics –More computationally intense so GPU has an edge, but Xeon is closing –PCIe transfer costs tip balance to the Xeon but this can be addressed –Haven’t tried on Cell In all cases, conventional multi-core CPU easier to program, debug, and optimize Garcia, J. R. Kelly, and T. Voran. Computing Spectropolarimetric Signals on Accelerator Hardware Comparing the Cell BE and NVIDIA GPUs. Proceedings of 2009 LCI Conference. 10-12 March 2009. Boulder CO.

18
Accelerators for Weather and Climate? Considerable conversion effort and maintenance issues, esp. for large legacy codes. What speedup justifies? What limits speedups? –Fast, close, and large enough memory resources –Distance from host processor –Baseline moving: CPUs getting faster Can newer generations of accelerators address? –Technically: probable –Business case: ???

Similar presentations








 Felice Pantaleo PH-CMG-CO (University.>")
 UNCLASSIFIED: 08/03/2012.>")









