Download presentation
Presentation is loading. Please wait.

1
Michael A. Kohn, MD, MPP 10/28/2010 Chapter 7 – Prognostic Tests Chapter 8 – Combining Tests and Multivariable Decision Rules

2
Outline of Topics Prognostic Tests –Differences from diagnostic tests –Quantifying prediction: calibration and discrimination –Value of prognostic information –Comparing predictions –Example: ABCD2 Score Combining Tests/Diagnostic Models –Importance of test non-independence –Recursive Partitioning –Logistic Regression –Variable (Test) Selection –Importance of validation separate from derivation
 Selection –Importance of validation separate from derivation")
3
Prognostic Tests (Ch 7)* Differences from diagnostic tests Validation/Quantifying Accuracy (calibration and discrimination) Assessing the value of prognostic information Comparing predictions by different people or different models *Will not discuss time-to-event analysis or predicting continuous outcomes. (Covered in Chapter 7.)
.")
4
Chance determines whether you get the disease Spin the needle

5
Diagnostic Test 1) Spin needle to see if you develop disease. 2) Perform test for disease. 3) Gold standard determines true disease state. (Can calculate sensitivity, specificity, LRs.)
 Perform test for disease. 3) Gold standard determines true disease state. (Can calculate sensitivity, specificity, LRs.).")
6
Prognostic Test 1) Perform test to predict the risk of disease. 2) Spin needle to see if you develop disease. 3) How do you assess the validity of the predictions?
 Spin needle to see if you develop disease. 3) How do you assess the validity of the predictions .")
7
Example: Mastate Cancer Once developed, always fatal. Can be prevented by mastatectomy. Two oncologists separately assign each of N individuals a risk for developing mastate cancer in the next 5 years.

8
PatientID Oncologist 1's Predicted Probability Oncologist 2's Predicted Probability Mastate Cancer within 5 years 120% 0 250%20%0 335%20%0 450%20%1 535%20%0 6 0 7 0 8 0 935%20%1 1050%20%0 1150%20%1 1235%20%0

9
How do you assess the validity of the predictions?

10
Oncologist 1 assigns risk of 50% How many like this? How many get mastate cancer? Spin the needles.

11
Oncologist 1 assigns risk of 35% How many like this? How many get mastate cancer? Spin the needles.

12
Oncologist 1 assigns risk of 20% How many like this? How many get mastate cancer? Spin the needles.

13
How accurate are the predicted probabilities? Break the population into groups Compare actual and predicted probabilities for each group Calibration* *Related to Goodness-of-Fit and diagnostic model validation.

14
Calibration Oncologist 1's Predicted Risk Observed Proportion Observed - Predicted 50%5/1631.3% -18.8% 35%3/1618.8% -16.3% 20%2/1612.5% -7.5% Oncologist 2's Predicted Risk Observed Proportion Observed - Predicted 20%10/4820.8% +0.8%

15
Calibration

16
How well can the test separate subjects in the population from the mean probability to values closer to zero or 1? May be more generalizable Often measured with C-statistic (AUROC) Discrimination
 Discrimination.")
17
Oncologist 1D+ D- Risk = 50%550%1129% Risk = 35%330%1334% Risk = 20%220%1437% Total10 100% 38 100%

18
Discrimination

19
AUROC = 0.63

20
True Risk Oncologist 1: 20% Oncologist 2: 20% True Risk: 11.1% Oncologist 1: 35% Oncologist 2: 20% True Risk: 16.7% Oncologist 1: 50% Oncologist 2: 20% True Risk: 33.3%

21
True Risk -- Calibration True RiskObserved Proportion Observed - Predicted 33.3%5/1631.3% -2.1% 16.7%3/1618.8% 2.1% 11.1%2/1612.5% 1.4%

22
True Risk -- Calibration

23
True Risk -- Discrimination True RiskD+ D- 33.3%550%1129% 16.7%330%1334% 11.1%220%1437% Total10 100% 38 100%

24
True Risk -- Discrimination

25
AUROC = 0.63

26
ROC curve depends only on rankings, not calibration

27
Random event occurs AFTER prognostic test. 1) Perform test to predict the risk of disease. 2) Spin needle to see if you develop disease. Only crystal ball allows perfect prediction.
 Spin needle to see if you develop disease. Only crystal ball allows perfect prediction..")
28
True Risk: 11.1%True Risk: 16.7%True Risk: 33.3% Maximum AUROC Maximum AUROC = 0.65

29
Diagnostic TestPrognostic Test Purpose Chance Event Occurs to Patient Study Design Test Result Maximum Obtainable AUROC Diagnostic versus Prognostic Tests Identify Prevalent Disease Predict Incident Disease/Outcome Prior to TestAfter Test Cross-SectionalCohort +/-, ordinal, continuous Risk (Probability) <1 (not clairvoyant) 1 (gold standard)
 <1 (not clairvoyant) 1 (gold standard)")
30
Value of Prognostic Information Why do you want to know risk of mastate cancer? To decide whether to do a mastatectomy.

31
Value of Prognostic Information It is 4 times worse to die of mastate gland cancer than to have a mastatectomy. C death = 4C mastatectomy Should do mastatectomy when P × C death > C mastatectomy P > C mastatectomy / C death P > 1/4 Fine Point: If it is 4 times worse to die of mastate cancer that to live AND have a mastatectomy, then the NET cost of a death is 4C – C = 3C. Threshold odds equal C:B or 1:3.

32
Oncologist 1: 20% < 25% NO Mastatectomy 11 out of 100 die of mastate cancer, no mastatectomies Oncologist 1: 35% > 25% Mastatectomy 83 out of 100 unnecessary; no mastate cancer deaths Oncologist 1: 50% > 25% Mastatectomy 67 out of 100 unnecessary; no mastate cancer deaths Value of Prognostic Information 300 patients (100 per risk group)
")
33
Oncologist 2: 20% < 25% No Mastatectomy 11 out of 100 die of mastate cancer; no mastatectomies Oncologist 2: 20% < 25% No Mastatectomy 17 out of 100 die; no mastatectomies Oncologist 2: 20% < 25% No Mastatectomy 33 out of 100 die; no mastatectomies Value of Prognostic Information 300 patients (100 per risk group)
")
34
True Risk: 11% < 25% No Mastatectomy 11 out of 100 die of mastate cancer; no mastatectomies True Risk: 17% < 25% No Mastatectomy 17 out of 100 die; no mastatectomies True Risk: 33% > 25% Mastatectomy 67 out of 100 unnecessary; no mastate cancer deaths Value of Prognostic Information 300 patients (100 per risk group)
")
35
Mastatecto mies Deaths from Mastate Cancer Mastatectomy "Equivalents" Death “Equivalents” Oncologist 120011244 61 Oncologist 2061244 61 True Risk10028 21253 Value of True Risk Estimate Relative to Oncologists 1 and 2 = 33 “mastatectomy equivalents“ and 8 “death equivalents. Value of Prognostic Information 300 patients (100 per risk group)
.")
36
Comparing Predictions Identify cohort. Obtain predictions (or information necessary for prediction) at inception. Provide uniform treatment to cohort or at least treat independent of (blinded to) prediction. Determine outcomes. Scenario: What would have happened if treatment were based on predicted risk?
 at inception. Provide uniform treatment to cohort or at least treat independent of (blinded to) prediction. Determine outcomes. Scenario: What would have happened if treatment were based on predicted risk .")
37
Doctors and patients like prognostic information But hard to assess its value Most objective approach is decision- analytic. Consider: What decision is to be made? Costs of errors? Cost of test? Value of Prognostic Information

38
Common Problems with Studies of Prognostic Tests See Chapter 7

39
Comparing Predictions Compare ROC Curves and AUROCs Reclassification Tables*, Net Reclassification Improvement (NRI), Integrated Discrimination Improvement (IDI) See Jan. 30, 2008 Issue of Statistics in Medicine* (? and EBD Edition 2 ?) *Pencina et al. Stat Med. 2008 Jan 30;27(2):157-72;
 *Pencina et al. Stat Med Jan 30;27(2):157-72;.")
40
Risk FactorPoints Age ≥ 60 years1 Blood Pressure SBP ≥ 140 or DBP ≥ 901 Clincal features of TIA Unilateral weakness (with or without speech impairment)2 Speech impairment without unilateral weakness1 Duration TIA duration ≥ 60 minutes2 TIA duration 10-59 minutes1 Diabetes Diabetes diagnosed by a physician1 Total ABCD2 Score0 – 7 ABCD2 Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92.
:")
41
ABCD2 (Calibration) Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92. Score % of TIA Patients 90-Day Stroke Risk 0-334%3.1% 4-545%9.8% 6-721%17.8%

42
ABCD2 (Discrimination) Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92. Score 90-Day Stroke No 90- Day Stroke LR 6-740.6%19.0%2.14 4-547.9%44.7%1.07 0-311.5%36.3%0.32 100.0%
: Score 90-Day Stroke No 90- Day Stroke LR %19.0% %44.7% %36.3% %.")
43
ABCD2 (Discrimination) Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92.
 Johnston SC, et al. Lancet Jan 27;369(9558):")
44
ABCD2 (Discrimination) Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92.
 Johnston SC, et al. Lancet Jan 27;369(9558):")
45
Better Discrimination

46
Replace This Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92.
:")
47
With This

48
Replace This Johnston SC, et al. Lancet. 2007 Jan 27;369(9558):283-92.
:")
49
With This

50
What to with the ABCD2 score? Recommendation is to admit TIA patients with ABCD2 > 5, and consider admission for ABCD2 4-5. Could give tPA if they have a stroke. Accelerated work-up. (? evidence that accelerated work-up actually improves outcomes.)
.")
51
Importance of test non- independence Recursive Partitioning Logistic Regression Variable (Test) Selection Importance of validation separate from derivation (calibration and discrimination revisited) Combining Tests/Diagnostic Models
 Selection Importance of validation separate from derivation (calibration and discrimination revisited) Combining Tests/Diagnostic Models")
52
Combining Tests Example Prenatal sonographic Nuchal Translucency (NT) and Nasal Bone Exam as dichotomous tests for Trisomy 21* *Cicero, S., G. Rembouskos, et al. (2004). "Likelihood ratio for trisomy 21 in fetuses with absent nasal bone at the 11- 14-week scan." Ultrasound Obstet Gynecol 23(3): 218-23.
. Likelihood ratio for trisomy 21 in fetuses with absent nasal bone at the week scan. Ultrasound Obstet Gynecol 23(3):")
53
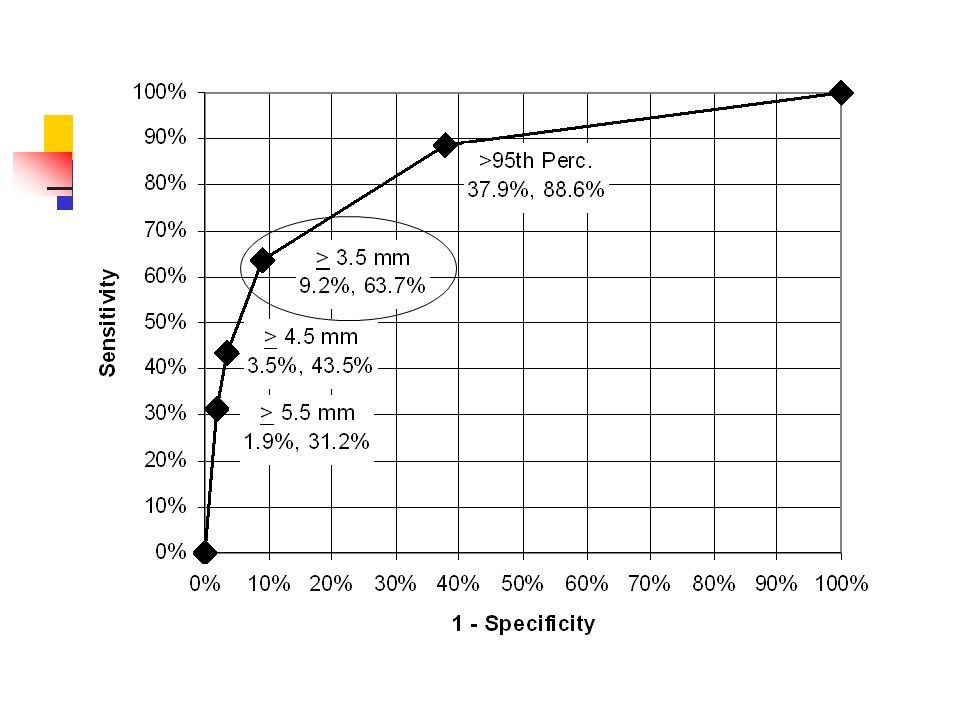
If NT ≥ 3.5 mm Positive for Trisomy 21* *What’s wrong with this definition?

55
In general, don’t make multi-level tests like NT into dichotomous tests by choosing a fixed cutoff I did it here to make the discussion of multiple tests easier I arbitrarily chose to call ≥ 3.5 mm positive

56
One Dichotomous Test Trisomy 21 Nuchal D+ D- LR Translucency ≥ 3.5 mm212 4787.0 < 3.5 mm12147450.4 Total3335223 Do you see that this is (212/333)/(478/5223)? Review of Chapter 3: What are the sensitivity, specificity, PPV, and NPV of this test? (Be careful.)
.")
57
Nuchal Translucency Sensitivity = 212/333 = 64% Specificity = 4745/5223 = 91% Prevalence = 333/(333+5223) = 6% (Study population: pregnant women about to undergo CVS, so high prevalence of Trisomy 21) PPV = 212/(212 + 478) = 31% NPV = 4745/(121 + 4745) = 97.5%* * Not that great; prior to test P(D-) = 94%
 = 6% (Study population: pregnant women about to undergo CVS, so high prevalence of Trisomy 21) PPV = 212/( ) = 31% NPV = 4745/( ) = 97.5%* * Not that great; prior to test P(D-) = 94%")
58
Clinical Scenario – One Test Pre-Test Probability of Down’s = 6% NT Positive Pre-test prob: 0.06 Pre-test odds: 0.06/0.94 = 0.064 LR(+) = 7.0 Post-Test Odds = Pre-Test Odds x LR(+) = 0.064 x 7.0 = 0.44 Post-Test prob = 0.44/(0.44 + 1) = 0.31
 = 7.0 Post-Test Odds = Pre-Test Odds x LR(+) = x 7.0 = 0.44 Post-Test prob = 0.44/( ) = 0.31")
59
NT Positive Pre-test Prob = 0.06 P(Result|Trisomy 21) = 0.64 P(Result|No Trisomy 21) = 0.09 Post-Test Prob = ? http://www.quesgen.com/PostProbofDisease.php Slide Rule

60
Nasal Bone Seen NBA=“No” Neg for Trisomy 21 Nasal Bone Absent NBA=“Yes” Pos for Trisomy 21

61
Second Dichotomous Test Nasal Bone Tri21+ Tri21-LR Absent Yes 229 12927.8 No10450940.32 Total3335223 Do you see that this is (229/333)/(129/5223)?
/(129/5223)")
62
Pre-Test Probability of Trisomy 21 = 6% NT Positive for Trisomy 21 (≥ 3.5 mm) Post-NT Probability of Trisomy 21 = 31% Nasal Bone Absent Post-NBA Probability of Trisomy 21 = ? Clinical Scenario –Two Tests Using Probabilities

63
Clinical Scenario – Two Tests Pre-Test Odds of Tri21 = 0.064 NT Positive (LR = 7.0) Post-Test Odds of Tri21 = 0.44 Nasal Bone Absent (LR = 27.8?) Post-Test Odds of Tri21 =.44 x 27.8? = 12.4? (P = 12.4/(1+12.4) = 92.5%?) Using Odds
 = 92.5% ) Using Odds.")
64
Clinical Scenario – Two Tests Pre-Test Probability of Trisomy 21 = 6% NT ≥ 3.5 mm AND Nasal Bone Absent

65
Question Can we use the post-test odds after a positive Nuchal Translucency as the pre-test odds for the positive Nasal Bone Examination? i.e., can we combine the positive results by multiplying their LRs? LR(NT+, NBE +) = LR(NT +) x LR(NBE +) ? = 7.0 x 27.8 ? = 194 ?
 = LR(NT +) x LR(NBE +) . = 7.0 x =")
66
Answer = No NTNBE Trisomy 21 +% Trisomy 21 -%LR Pos 15847%360.7% 69 PosNeg5416%4428.5% 1.9 NegPos7121%931.8% 12 Neg 5015%465289% 0.2 Total 333100%5223100% Not 194 158/(158 + 36) = 81%, not 92.5%
 = 81%, not 92.5%")
67
Non-Independence Absence of the nasal bone does not tell you as much if you already know that the nuchal translucency is ≥ 3.5 mm.

68
Clinical Scenario Pre-Test Odds of Tri21 = 0.064 NT+/NBE + (LR =68.8) Post-Test Odds = 0.064 x 68.8 = 4.40 (P = 4.40/(1+4.40) = 81%, not 92.5%) Using Odds
 Post-Test Odds = x 68.8 = 4.40 (P = 4.40/(1+4.40) = 81%, not 92.5%) Using Odds")
69
Non-Independence

70
Non-Independence of NT and NBA Apparently, even in chromosomally normal fetuses, enlarged NT and absence of the nasal bone are associated. A false positive on the NT makes a false positive on the NBE more likely. Of normal (D-) fetuses with NT < 3.5 mm only 2.0% had nasal bone absent. Of normal (D-) fetuses with NT ≥ 3.5 mm, 7.5% had nasal bone absent. Some (but not all) of this may have to do with ethnicity. In this London study, chromosomally normal fetuses of “Afro-Caribbean” ethnicity had both larger NTs and more frequent absence of the nasal bone. In Trisomy 21 (D+) fetuses, normal NT was associated with the presence of the nasal bone, so a false negative on the NT was associated with a false negative on the NBE.
 fetuses with NT < 3.5 mm only 2.0% had nasal bone absent. Of normal (D-) fetuses with NT ≥ 3.5 mm, 7.5% had nasal bone absent. Some (but not all) of this may have to do with ethnicity. In this London study, chromosomally normal fetuses of Afro-Caribbean ethnicity had both larger NTs and more frequent absence of the nasal bone. In Trisomy 21 (D+) fetuses, normal NT was associated with the presence of the nasal bone, so a false negative on the NT was associated with a false negative on the NBE..")
71
Non-Independence Instead of looking for the nasal bone, what if the second test were just a repeat measurement of the nuchal translucency? A second positive NT would do little to increase your certainty of Trisomy 21. If it was false positive the first time around, it is likely to be false positive the second time.

72
Reasons for Non- Independence Tests measure the same aspect of disease. One aspect of Down’s syndrome is slower fetal development; the NT decreases more slowly and the nasal bone ossifies later. Chromosomally NORMAL fetuses that develop slowly will tend to have false positives on BOTH the NT Exam and the Nasal Bone Exam.

73
Reasons for Non- Independence Heterogeneity of Disease (e.g. spectrum of severity)*. Heterogeneity of Non-Disease. (See EBD page 158.) *In this example, Down’s syndrome is the only chromosomal abnormality considered, so disease is fairly homogeneous
*. Heterogeneity of Non-Disease. (See EBD page 158.) *In this example, Down’s syndrome is the only chromosomal abnormality considered, so disease is fairly homogeneous.")
74
Unless tests are independent, we can’t combine results by multiplying LRs

75
Ways to Combine Multiple Tests On a group of patients (derivation set), perform the multiple tests and (independently*) determine true disease status (apply the gold standard) Measure LR for each possible combination of results Recursive Partitioning Logistic Regression *Beware of incorporation bias
, perform the multiple tests and (independently*) determine true disease status (apply the gold standard) Measure LR for each possible combination of results Recursive Partitioning Logistic Regression *Beware of incorporation bias")
76
Determine LR for Each Result Combination NTNBATri21+%Tri21-%LR Post Test Prob* Pos 15847%360.7%6981% PosNeg5416%4428.5%1.911% NegPos7121%931.8%1243% Neg 5015%465289.1% 0.21% Total 333100%5223100% *Assumes pre-test prob = 6%

77
Sort by LR (Descending) NTNBATri21+%Tri21-%LR Pos 15847%360.70%69 NegPos7121%931.80%12 PosNeg5416%4428.50%1.9 Neg 5015%465289.10%0.2
 NTNBATri21+%Tri21-%LR Pos 15847%360.70%69 NegPos7121%931.80%12 PosNeg5416% %1.9 Neg 5015% %0.2")
78
Apply Chapter 4 – Multilevel Tests Now you have a multilevel test (In this case, 4 levels.) Have LR for each test result Can create ROC curve and calculate AUROC Given pre-test probability and treatment threshold probability (C/(B+C)), can find optimal cutoff.
 Have LR for each test result Can create ROC curve and calculate AUROC Given pre-test probability and treatment threshold probability (C/(B+C)), can find optimal cutoff.")
79
Create ROC Table NTNBETri21+Sens Tri2 1-1 - SpecLR 0% Pos 15847%360.70%69 NegPos7168%933%12 PosNeg5484%44211%1.9 Neg 50100%4652100%0.2

80
AUROC = 0.896

81
Optimal Cutoff NTNBELR Post-Test Prob Pos 690.81 NegPos120.43 PosNeg1.90.11 Neg 0.20.01 Assume Pre-test probability = 6% Threshold for CVS is 2%

82
Determine LR for Each Result Combination 2 dichotomous tests: 4 combinations 3 dichotomous tests: 8 combinations 4 dichotomous tests: 16 combinations Etc. 2 3-level tests: 9 combinations 3 3-level tests: 27 combinations Etc.

83
Determine LR for Each Result Combination How do you handle continuous tests? Not always practical for groups of tests.

84
Recursive Partitioning Measure NT First

85
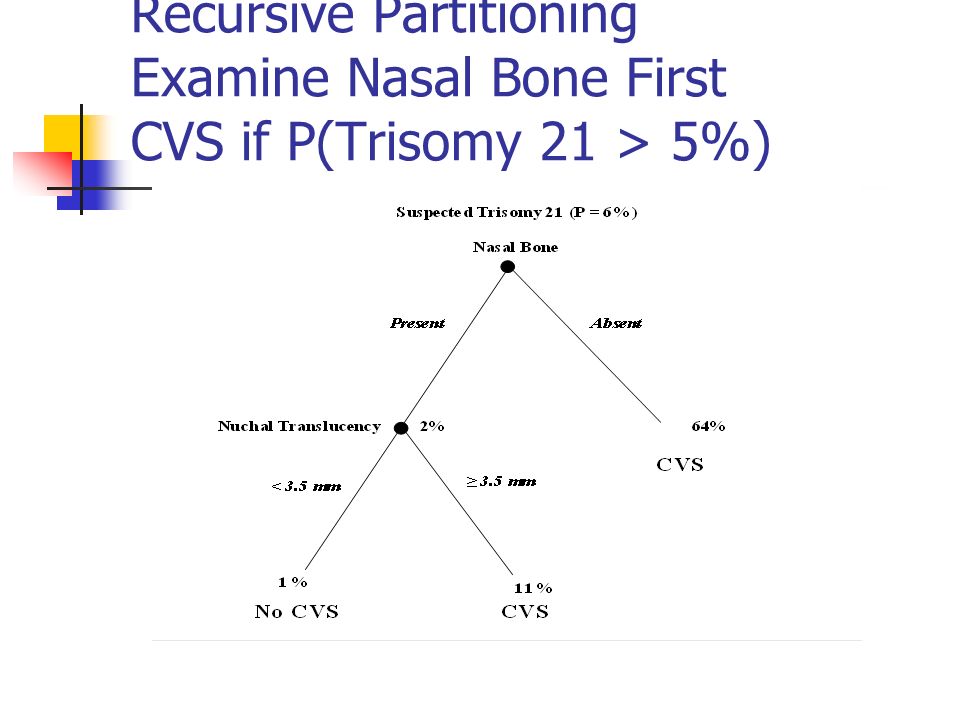
Recursive Partitioning Examine Nasal Bone First

86
Do Nasal Bone Exam First Better separates Trisomy 21 from chromosomally normal fetuses If your threshold for CVS is between 11% and 43%, you can stop after the nasal bone exam If your threshold is between 1% and 11%, you should do the NT exam only if the NBE is normal.

87
Recursive Partitioning Examine Nasal Bone First CVS if P(Trisomy 21 > 5%)
")
89
Recursive Partitioning Same as Classification and Regression Trees (CART) Don’t have to work out probabilities (or LRs) for all possible combinations of tests, because of “tree pruning”
 Don’t have to work out probabilities (or LRs) for all possible combinations of tests, because of tree pruning")
90
Recursive Partitioning Does not deal well with continuous test results* *when there is a monotonic relationship between the test result and the probability of disease

91
Logistic Regression Ln(Odds(D+)) = a + b NT NT+ b NBA NBA + b interact (NT)(NBA) “+” = 1 “-” = 0 More on this later in ATCR!
) = a + b NT NT+ b NBA NBA + b interact (NT)(NBA) + = 1 - = 0 More on this later in ATCR!")
92
Why does logistic regression model log-odds instead of probability? Related to why the LR Slide Rule’s log-odds scale helps us visualize combining test results.

93
Probability of Trisomy 21 vs. Maternal Age

94
Ln(Odds) of Trisomy 21 vs. Maternal Age
 of Trisomy 21 vs. Maternal Age")
95
Combining 2 Continuous Tests > 1% Probability of Trisomy 21 < 1% Probability of Trisomy 21

96
Choosing Which Tests to Include in the Decision Rule Have focused on how to combine results of two or more tests, not on which of several tests to include in a decision rule. Variable Selection Options include: Recursive partitioning Automated stepwise logistic regression Choice of variables in derivation data set requires confirmation in a separate validation data set.

97
Variable Selection Especially susceptible to overfitting

98
Need for Validation: Example* Study of clinical predictors of bacterial diarrhea. Evaluated 34 historical items and 16 physical examination questions. 3 questions (abrupt onset, > 4 stools/day, and absence of vomiting) best predicted a positive stool culture (sensitivity 86%; specificity 60% for all 3). Would these 3 be the best predictors in a new dataset? Would they have the same sensitivity and specificity? *DeWitt TG, Humphrey KF, McCarthy P. Clinical predictors of acute bacterial diarrhea in young children. Pediatrics. Oct 1985;76(4):551- 556.
 best predicted a positive stool culture (sensitivity 86%; specificity 60% for all 3). Would these 3 be the best predictors in a new dataset. Would they have the same sensitivity and specificity. *DeWitt TG, Humphrey KF, McCarthy P. Clinical predictors of acute bacterial diarrhea in young children. Pediatrics. Oct 1985;76(4):")
99
Need for Validation Develop prediction rule by choosing a few tests and findings from a large number of candidates. Takes advantage of chance variations* in the data. Predictive ability of rule will probably disappear when you try to validate on a new dataset. Can be referred to as “overfitting.” e.g., low serum calcium in 12 children with hemolytic uremic syndrome and bad outcomes

100
VALIDATION No matter what technique (CART or logistic regression) is used, the tests included in a model and the way in which their results are combined must be tested on a data set different from the one used to derive the rule. Beware of studies that use a “validation set” to tweak the model. This is really just a second derivation step.

101
Prognostic Tests and Multivariable Diagnostic Models Commonly express results in terms of a probability --risk of the outcome by a fixed time point (prognostic test) --posterior probability of disease (diagnostic model) Need to assess both calibration and discrimination.
 --posterior probability of disease (diagnostic model) Need to assess both calibration and discrimination.")
102
Validation Dataset Measure all the variables needed for the model. Determine disease status (D+ or D-) on all subjects.
 on all subjects..")
103
VALIDATION Calibration -- Divide dataset into probability groups (deciles, quintiles, …) based on the model (no tweaking allowed). -- In each group, compare actual D+ proportion to model-predicted probability in each group.

104
VALIDATION Discrimination Discrimination -- Test result is model-predicted probability of disease. -- Use “Walking Man” to draw ROC curve and calculate AUROC.

105
Outline of Topics Prognostic Tests –Differences from diagnostic tests –Quantifying prediction: calibration and discrimination –Comparing predictions –Value of prognostic information –Example: ABCD2 Combining Tests/Diagnostic Models –Importance of test non-independence –Recursive Partitioning –Logistic Regression –Variable (Test) Selection –Importance of validation separate from derivation
 Selection –Importance of validation separate from derivation")
Similar presentations



 and Continuous Tests ROC curves and Likelihood Ratios for results other than “+” or “-” Michael A. Kohn,>")
 Curves>")













 URVASHI VAID MD, MS AUG 2012.>")
