Download presentation
Presentation is loading. Please wait.

1
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound

2
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann What is Sound ? Acoustics is the study of sound. Physical - sound as a disturbance in the air Psychophysical - sound as perceived by the ear Sound as stimulus (physical event) & sound as a sensation. Pressures changes (in band from 20 Hz to 20 kHz) Physical terms Amplitude Frequency Spectrum
 & sound as a sensation. Pressures changes (in band from 20 Hz to 20 kHz) Physical terms Amplitude Frequency Spectrum.")
3
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound Waves In a free field, an ideal source of acoustical energy sends out sound of uniform intensity in all directions. => Sound is propagating as a spherical wave. Intensity of sound is inversely proportional to the square of the distance (Inverse distance law). 6 dB decrease of sound pressure level per doubling the distance.
. 6 dB decrease of sound pressure level per doubling the distance..")
4
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound Waves

5
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann What is Sound

6
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann How we hear –Ear connected to the brain left brain: speech right brain: music Ear's sensitivty to frequency is logarithmic Varying frequency response Dynamic range is about 120 dB (at 3-4 kHz) Frequency discrimination 2 Hz (at 1 kHz) Intensity change of 1 dB can be detected.
 Frequency discrimination 2 Hz (at 1 kHz) Intensity change of 1 dB can be detected..")
7
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Digitizing Sound

8
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Digitally Sampling

9
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Undersampling

10
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Clipping

11
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Quantization

12
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Digital Sampling Sampling is dictated by the Nyquist sampling theorem which states how quickly samples must be taken to ensure an accurate representation of the analog signal.Sampling is dictated by the Nyquist sampling theorem which states how quickly samples must be taken to ensure an accurate representation of the analog signal. The Nyquist sampling theorem states that the sampling frequency must be greater than the highest frequency in the original analog signal.The Nyquist sampling theorem states that the sampling frequency must be greater than the highest frequency in the original analog signal.

13
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound Sampling Basics Common Sampling Rates Common Sampling Rates 8KHz (Phone) or 8.012820513kHz (Phone, NeXT) 8KHz (Phone) or 8.012820513kHz (Phone, NeXT) 11.025kHz (1/4 CD std) 11.025kHz (1/4 CD std) 16kHz (G.722 std) 16kHz (G.722 std) 22.05kHz (1/2 CD std) 22.05kHz (1/2 CD std) 44.1kHz (CD, DAT) 44.1kHz (CD, DAT) 48kHz (DAT) 48kHz (DAT) Bits per Sample Bits per Sample 8 or 16 8 or 16 Number of Channels Number of Channels mono/stereo/quad/ etc. mono/stereo/quad/ etc.
 or kHz (Phone, NeXT) 8KHz (Phone) or kHz (Phone, NeXT) kHz (1/4 CD std) kHz (1/4 CD std) 16kHz (G.722 std) 16kHz (G.722 std) 22.05kHz (1/2 CD std) 22.05kHz (1/2 CD std) 44.1kHz (CD, DAT) 44.1kHz (CD, DAT) 48kHz (DAT) 48kHz (DAT) Bits per Sample Bits per Sample 8 or 16 8 or 16 Number of Channels Number of Channels mono/stereo/quad/ etc. mono/stereo/quad/ etc..")
14
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Space Requirements Storage Requirements for One Minute of Sound

15
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Common Sound File Formats Mulaw (Sun, NeXT).au Mulaw (Sun, NeXT).au RIFF Wave (MS WAV).wav RIFF Wave (MS WAV).wav MPEG Audio Layer (MPEG).mpa.mp3 MPEG Audio Layer (MPEG).mpa.mp3 AIFC (Apple, SGI).aiff.aif AIFC (Apple, SGI).aiff.aif HCOM (Mac).hcom HCOM (Mac).hcom SND (Sun, NeXT).snd SND (Sun, NeXT).snd VOC (Soundblaster card proprietary standard).voc VOC (Soundblaster card proprietary standard).voc AND MANY OTHERS! AND MANY OTHERS!
.au Mulaw (Sun, NeXT).au RIFF Wave (MS WAV).wav RIFF Wave (MS WAV).wav MPEG Audio Layer (MPEG).mpa.mp3 MPEG Audio Layer (MPEG).mpa.mp3 AIFC (Apple, SGI).aiff.aif AIFC (Apple, SGI).aiff.aif HCOM (Mac).hcom HCOM (Mac).hcom SND (Sun, NeXT).snd SND (Sun, NeXT).snd VOC (Soundblaster card proprietary standard).voc VOC (Soundblaster card proprietary standard).voc AND MANY OTHERS. AND MANY OTHERS!.")
16
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Mu-Law u-LAW (or mu-LAW) is sgn(x) y= -------- ln( 1+ u |x|) ln(1+u) u=100 or 255
 is sgn(x) y= ln( 1+ u |x|) ln(1+u) u=100 or 255.")
17
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann What’s in a Sound File Format Header Information Header Information Magic Cookie Magic Cookie Sampling Rate Sampling Rate Bits/Sample Bits/Sample Channels Channels Byte Order Byte Order Endian Endian Compression type Compression type Data Data

18
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Example File Format (NIST SPHERE) NIST_1A 1024 sample_rate -i 16000 channel_count -i 1 sample_n_bytes -i 2 sample_byte_format -s2 10 sample_sig_bits -i 16 sample_count -i 594400 sample_coding -s3 pcm sample_checksum -i 20129 end_head
 NIST_1A 1024 sample_rate -i channel_count -i 1 sample_n_bytes -i 2 sample_byte_format -s2 10 sample_sig_bits -i 16 sample_count -i sample_coding -s3 pcm sample_checksum -i end_head.")
19
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann WAVe file format (Microsoft) RIFF A collection of data chunks. Each chunk has a 32-bit Id followed by a 32-bit chunk length followed by the chunk data. 0x00 chunk id 'RIFF' 0x00 chunk id 'RIFF' 0x04 chunk size (32-bits) 0x04 chunk size (32-bits) 0x08 wave chunk id 'WAVE' 0x08 wave chunk id 'WAVE' 0x0C format chunk id 'fmt ' 0x0C format chunk id 'fmt ' 0x10 format chunk size (32-bits) 0x10 format chunk size (32-bits) 0x14 format tag (currently pcm) 0x14 format tag (currently pcm) 0x16 number of channels 1=mono, 2=stereo 0x16 number of channels 1=mono, 2=stereo 0x18 sample rate in hz 0x18 sample rate in hz 0x1C average bytes per second 0x1C average bytes per second 0x20 number of bytes per sample 0x20 number of bytes per sample 1 = 8-bit mono 1 = 8-bit mono 2 = 8-bit stereo or 2 = 8-bit stereo or 16-bit mono 16-bit mono 4 = 16-bit stereo 4 = 16-bit stereo 0x22 number of bits in a sample 0x22 number of bits in a sample 0x24 data chunk id 'data' 0x24 data chunk id 'data' 0x28 length of data chunk (32-bits) 0x28 length of data chunk (32-bits) 0x2C Sample data 0x2C Sample data
 RIFF A collection of data chunks. Each chunk has a 32-bit Id followed by a 32-bit chunk length followed by the chunk data. 0x00 chunk id RIFF 0x00 chunk id RIFF 0x04 chunk size (32-bits) 0x04 chunk size (32-bits) 0x08 wave chunk id WAVE 0x08 wave chunk id WAVE 0x0C format chunk id fmt 0x0C format chunk id fmt 0x10 format chunk size (32-bits) 0x10 format chunk size (32-bits) 0x14 format tag (currently pcm) 0x14 format tag (currently pcm) 0x16 number of channels 1=mono, 2=stereo 0x16 number of channels 1=mono, 2=stereo 0x18 sample rate in hz 0x18 sample rate in hz 0x1C average bytes per second 0x1C average bytes per second 0x20 number of bytes per sample 0x20 number of bytes per sample 1 = 8-bit mono 1 = 8-bit mono 2 = 8-bit stereo or 2 = 8-bit stereo or 16-bit mono 16-bit mono 4 = 16-bit stereo 4 = 16-bit stereo 0x22 number of bits in a sample 0x22 number of bits in a sample 0x24 data chunk id data 0x24 data chunk id data 0x28 length of data chunk (32-bits) 0x28 length of data chunk (32-bits) 0x2C Sample data 0x2C Sample data.")
20
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Digital Audio Today Analog elements in the audio chain are replaced with digital elements. 16-bit wordlength, 32/44.1/48 kHz sampling rates. Mostly linear signal processing. Wide range of digital formats and storage media. Rapid development of 1-bit conversation technology => better SNR, phase and linearity. Rapid increase of signal processing power => possibility to implement new, complex features.

21
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann CD vs LP Information is stored digitally. The length of its data pits represents a series of 1s and 0s. Both audio channels are stored along the same pit track. Data is read using laser beam. Information density about 100 times greater than in LP. CD player can correct disc errors.

22
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Benefits of CD Robust No degradation from repeated playings because data is read by the laser beam. Error correction Transport`s performance does not affect the quality of audio reproduction. Digital circuitry more immune to aging and temperature problems Data conversion is independent of variations in disc rotational speed, hence wow and flutter are neglible. SNR over 90 dB. Subcode for display, control and user information

23
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Digital CD Format SamplingSampling 44.1 kHz => 10 % margin with respect to the Nyquist frequency (audible frequencies below 20 kHz) 16-bit linear => theoretical SNR about 98 dB (for sinusoidal signal with maximum allowed amplitude) audio bit rate 1.41 Mbit/s (44.1 kHz * 16 bits * 2 channels) Cross Interleaved Reed-Solomon Code (CIRC) for error correction SpecificationsSpecifications Playing time max. 74.7 min Disc diameter 120 mm Disc thickness 1.2 mm One sided medium, rotates clockwise Signal is recorded from inside to outside Pit is about 0.5 µm wide Pit edge is 1 and all other areas whether inside or outside a pit, are 0s
 16-bit linear => theoretical SNR about 98 dB (for sinusoidal signal with maximum allowed amplitude) audio bit rate 1.41 Mbit/s (44.1 kHz * 16 bits * 2 channels) Cross Interleaved Reed-Solomon Code (CIRC) for error correction SpecificationsSpecifications Playing time max min Disc diameter 120 mm Disc thickness 1.2 mm One sided medium, rotates clockwise Signal is recorded from inside to outside Pit is about 0.5 µm wide Pit edge is 1 and all other areas whether inside or outside a pit, are 0s.")
24
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Compression of Sound

25
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Motivation for Sound Compression need to minimize transmission costs or provide cost efficient storage demand to transmit over channels of limited capacity such as mobile radio channels need to share capacity for different services (voice, audio, data, graphics, images) in integrated service network
 in integrated service network.")
26
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Compression u-LAW sihttp://shuttle.nasa.gov/askmcc/answers/lence detection ADPCM (adaptive, delta PCM, 24/32/40 kbps) LPC-10E (Linear Predictive Coding 2.4kb/s) CELP 4.8Kb/s - builds on LPC GSM (European Cell Phones, RPE-LPC) 1650 bytes/sec (at 8000 samples/sec) RealAudio (builds on CELP, GSM, proprietary) MPEG Audio Layers (builds on ADPCM) Layer-2: From 32 kbps to 384 kbps - target bit rate of 128 kbps Layer-3: From 32 kbps to 320 kbps - target bit rate of 64 kbps Complex compression, using perceptual models
 LPC-10E (Linear Predictive Coding 2.4kb/s) CELP 4.8Kb/s - builds on LPC GSM (European Cell Phones, RPE-LPC) 1650 bytes/sec (at 8000 samples/sec) RealAudio (builds on CELP, GSM, proprietary) MPEG Audio Layers (builds on ADPCM) Layer-2: From 32 kbps to 384 kbps - target bit rate of 128 kbps Layer-3: From 32 kbps to 320 kbps - target bit rate of 64 kbps Complex compression, using perceptual models.")
27
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Compression u-LAW sihttp://shuttle.nasa.gov/askmcc/answers/lence detection ADPCM (adaptive, delta PCM, 24/32/40 kbps) LPC-10E (Linear Predictive Coding 2.4kb/s) CELP 4.8Kb/s - builds on LPC GSM (European Cell Phones, RPE-LPC) 1650 bytes/sec (at 8000 samples/sec) RealAudio (builds on CELP, GSM, proprietary) MPEG Audio Layers (builds on ADPCM) Layer-2: From 32 kbps to 384 kbps - target bit rate of 128 kbps Layer-3: From 32 kbps to 320 kbps - target bit rate of 64 kbps Complex compression, using perceptual models
 LPC-10E (Linear Predictive Coding 2.4kb/s) CELP 4.8Kb/s - builds on LPC GSM (European Cell Phones, RPE-LPC) 1650 bytes/sec (at 8000 samples/sec) RealAudio (builds on CELP, GSM, proprietary) MPEG Audio Layers (builds on ADPCM) Layer-2: From 32 kbps to 384 kbps - target bit rate of 128 kbps Layer-3: From 32 kbps to 320 kbps - target bit rate of 64 kbps Complex compression, using perceptual models.")
28
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound Editing GoldWave (www.goldwave.com)-GoldWave (www.goldwave.com)-www.goldwave.com requires a sound card. requires a sound card. digital audio sound player, recorder and editor digital audio sound player, recorder and editor can load, play and edit many different file formats can load, play and edit many different file formats.wav,.au,.voc,.snd.wav,.au,.voc,.snd displays separate graphics for the left and right channels displays separate graphics for the left and right channels very easy to use very easy to use good sound quality good sound quality Others: WHAM, Cool Edit, SOX, WINPLANY, Digital Audio Playback Facility, MOD4Win, etc. Others: WHAM, Cool Edit, SOX, WINPLANY, Digital Audio Playback Facility, MOD4Win, etc.

29
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Compression Approaches Delta codingDelta coding Encode differences only Encode differences only Predictive codingPredictive coding Predict the next sample Predict the next sample Linear Predictive Coding (LPC) - mostly for speechLinear Predictive Coding (LPC) - mostly for speech Describe fundamental frequencies + ‘error’ Describe fundamental frequencies + ‘error’ CELP, cell-phone standards CELP, cell-phone standards Variable Rate EncodingVariable Rate Encoding Don’t encode silences Don’t encode silences Subband codingSubband coding Split into frequency bands each encoded separately + efficiently Split into frequency bands each encoded separately + efficiently Psycho-acoustical codingPsycho-acoustical coding drop bits where you can’t hear it drop bits where you can’t hear it
 - mostly for speechLinear Predictive Coding (LPC) - mostly for speech Describe fundamental frequencies + ‘error’ Describe fundamental frequencies + ‘error’ CELP, cell-phone standards CELP, cell-phone standards Variable Rate EncodingVariable Rate Encoding Don’t encode silences Don’t encode silences Subband codingSubband coding Split into frequency bands each encoded separately + efficiently Split into frequency bands each encoded separately + efficiently Psycho-acoustical codingPsycho-acoustical coding drop bits where you can’t hear it drop bits where you can’t hear it.")
30
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Tips for Audio on the Web There is no generic audio standard on the Web Listening to 16-bit sounds on an 8-bit system results in strange effects Users will be annoyed if they spend a lot of time downloading a sound and they can’t play it Distribute only 8-bit sounds on your Web page Or, provide different sound files in both 8- and 16-bits Record in the highest sampling rate and size you can, and then process down to 8-bit Keep file size small downsampling to 8-bit use a lower sampling rate use mono sounds Describe what format those sounds are in WAVE, AIFF, or other format Providing the file size in the description is a politeness to help estimate download times If you need high sound quality and have large audio files: Use a smaller sound clip in m-law format as a preview or for those who can’t to listen to the higher-quality sample. Check out http://www.realaudio.com/help/content/audiohints.html.

31
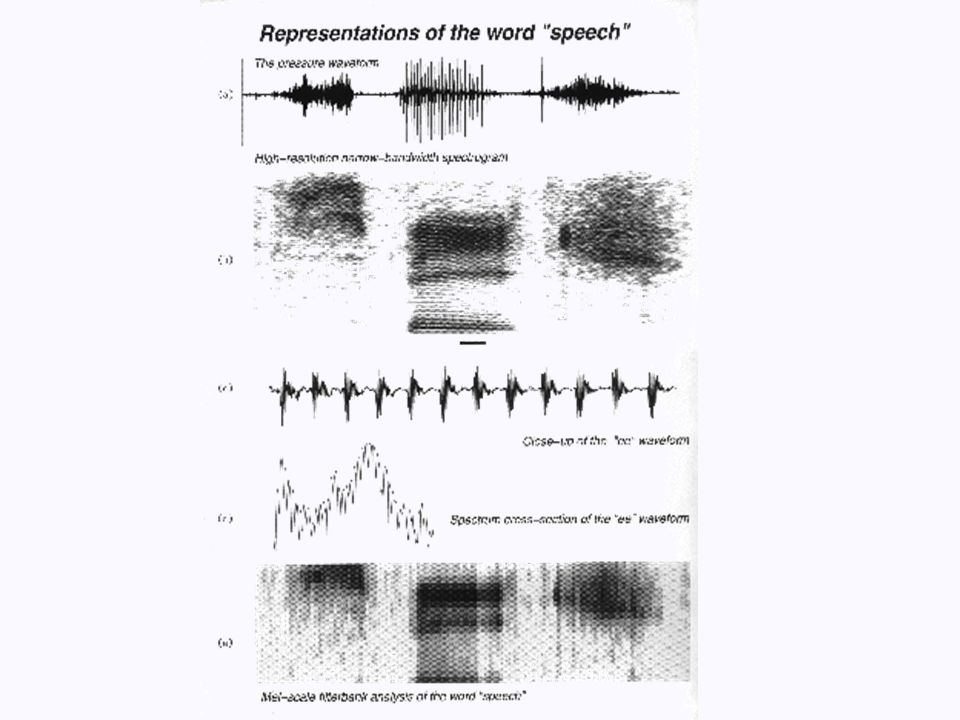
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Speech Recognition in Brief

33
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Acoustic Modeling Describes the sounds that make up speech Lexicon Describes which sequences of speech sounds make up valid words Language Model Describes the likelihood of various sequences of words being spoken Speech Recognition Speech Recognition Knowledge Sources

34
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Speech Recognition O is an acoustical ‘observation’ W is a ‘word’ we are trying to recognize Maximize w = argmax (P(w) | O) P(w|O) is unknown so by Bayes’ rule: P(O|w) P(w) P(w|O) = ------------------------ p(O) p(O)
 | O) P(w|O) is unknown so by Bayes’ rule: P(O|w) P(w) P(w|O) = p(O) p(O).")
35
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Hidden Markov Model

36
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Searching the Speech Signal Trellis

37
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Language Models

38
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Lexicon - links words to phones in acoustic model Aaron EH R AX N Aaron(2) AE R AX N abandon AX B AE N D AX N abandoned AX B AE N D AX N DD abandoning AX B AE N D AX N IX NG abandonment AX B AE N D AX N M AX N TD abated AX B EY DX IX DD abatement AX B EY TD M AX N TD abbey AE B IY Abbott AE B AX TD Abboud AA B UW DD abby AE B IY abducted AE BD D AH KD T IX DD Abdul AE BD D UW L
 AE R AX N abandon AX B AE N D AX N abandoned AX B AE N D AX N DD abandoning AX B AE N D AX N IX NG abandonment AX B AE N D AX N M AX N TD abated AX B EY DX IX DD abatement AX B EY TD M AX N TD abbey AE B IY Abbott AE B AX TD Abboud AA B UW DD abby AE B IY abducted AE BD D AH KD T IX DD Abdul AE BD D UW L.")
39
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Continual Progress in Speech Recognition Increasingly Difficult Tasks, Steadily Declining Error Rates CONVERSATIONAL SPEECH Non-English English BROADCAST NEWS 20,000 Word Varied microphones Standard microphone Noisy environment Unlimited Vocabulary 5000 word All results are Speaker -Independent READ SPEECH 1000 Word vocabulary 100 50 10 1 Word Error Rate (%) 1988 198919901991 1992 1993 19941995199619971998 NSA/Wayne/Doddington
 NSA/Wayne/Doddington.")
40
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann References http://www.nlc-bnc.ca/pubs/netnotes/notes24.htm http://www.nlc-bnc.ca/pubs/netnotes/notes24.htm http://www.spies.com/sox (conversion tool) http://www.spies.com/sox (conversion tool) http://freebsd.cdrom.com/.5/cica/sounds/gldwav21.zip http://freebsd.cdrom.com/.5/cica/sounds/gldwav21.zip Sub-Band Coding: http://www.otolith.com/pub/u/howitt/sbc.tutorial.html Sub-Band Coding: http://www.otolith.com/pub/u/howitt/sbc.tutorial.html Sub-Band Coding Sub-Band Coding Speech Recognition http://svr-www.eng.cam.ac.uk/comp.speech/Section2/speechlinks.html Speech Recognition http://svr-www.eng.cam.ac.uk/comp.speech/Section2/speechlinks.html
 (conversion tool) Sub-Band Coding: Sub-Band Coding: Sub-Band Coding Sub-Band Coding Speech Recognition Speech Recognition")
41
Carnegie Mellon © Copyright 2000 Michael G. Christel and Alexander G. Hauptmann Sound That’s all for today

Similar presentations








 describe the purpose of using audio in multimedia.>")
>")





>")
, education, telemedicine, videoconference, videophone Storage capacity Large capacity.>")


