Download presentation
Presentation is loading. Please wait.

1
Implementing Precise Interrupts in Pipelined Processors James E. Smith Andrew R.Pleszkun Presented By: Ravikumar Source: http:// www.cse.msu.edu/~kangfeng/precise_interrupt.ppt

2
What will be covered? Interrupts in pipelined processors The methods to implement precise interrupt in pipelined processors The performance evaluation of those methods Extension Architecture solution

3
Interrupt Interrupt: Stop and resume. Precise interrupt: Imprecise interrupt:

4
Types of interrupts I/O device request Invoking an operating system service from a user program Tracing instruction execution Breakpoint (programmer-requested interrupt) Integer arithmetic overflow FP arithmetic anomaly Page fault Misaligned memory access Memory protection violation Using an undefined or unimplemented instruction Hardware malfunctions Power failure
 Integer arithmetic overflow FP arithmetic anomaly Page fault Misaligned memory access Memory protection violation Using an undefined or unimplemented instruction Hardware malfunctions Power failure")
5
Example code StatementCommentsExecution Time 0 R2 0 Init. Loop index 1 R0 0 Init. Loop count 2 R5 1 Loop inc. value 3 R7 100 Maximum loop count 4Loop: R1 (R2 + A) Load A(I)11 clock cycles 5 R3 (R2 + B) Load B(I)11 clock cycles 6 R4 R1 + fR3 Floating add6 clock cycles 7 R0 R0 + R5 Inc. loop count2 clock cycles 8 (R0 + C) R4 Store C(I) 9 R2 R2 + R5 Inc. loop index2 clock cycles 10P = Loop:R0 != R7Cond. Branch not equal
 Load A(I)11 clock cycles 5 R3 (R2 + B) Load B(I)11 clock cycles 6 R4 R1 + fR3 Floating add6 clock cycles 7 R0 R0 + R5 Inc. loop count2 clock cycles 8 (R0 + C) R4 Store C(I) 9 R2 R2 + R5 Inc. loop index2 clock cycles 10P = Loop:R0 != R7Cond. Branch not equal.")
6
Interrupt in sequential model processors pc=5,R1,R2,R0,R5,R7 pc=6,R3,R1,R2,R0,R5,R7 pc=7,R4,R3,R1,R2,R0,R5,R7Interrupt occurs XX 1. Keep pc=7,R4, R3,R1,R2,R0,R5,R7, 2. Program suspended Interrupt program running Interrupt program stop 1. restore pc=7,R4, R3,R1,R2,R0,R5,R7, 2. Program resume pc=8,R4,R3,R1,R2,R0,R5, R7, 4R1 (R2+A) 5R3 (R2+B) 6R4 R1+fR3 110R2 44 … 150R0 100 7R0 R0+R5 In sequential model processors, the interrupt is precise. It guarantees suspended program can be resumed.
 5R3 (R2+B) 6R4 R1+fR3 110R2 44 … 150R0 100 7R0 R0+R5 In sequential model processors, the interrupt is precise. It guarantees suspended program can be resumed..")
7
Interrupt in pipelined processors pc=5,R1,R2,R0,R5,R7 pc=6,R3,R1,R2,R0,R5,R7 Interrupt occurs XX 1. Keep pc=8,R3, R1, R2,R0,R5,R7 2. Program suspended Interrupt program running Interrupt program stop 1. restore pc=8,R3,R1, R2,R0,R5,R7 2. Program resume pc=8,R3,R1,R2,R0,R5,R7, 4R1 (R2+A) 5R3 (R2+B) 110R2 44 … 150R0 100 6R4 R1+fR3 7R0 R0+R5 8 (R0+C) R4 R4 isn’t available In pipelined processors the interrupt could be imprecise, It does not guarantee suspended program can be resumed. 9 R2 R2 + R5
 5R3 (R2+B) 110R2 44 … 150R0 100 6R4 R1+fR3 7R0 R0+R5 8 (R0+C) R4 R4 isn’t available In pipelined processors the interrupt could be imprecise, It does not guarantee suspended program can be resumed. 9 R2 R2 + R5.")
8
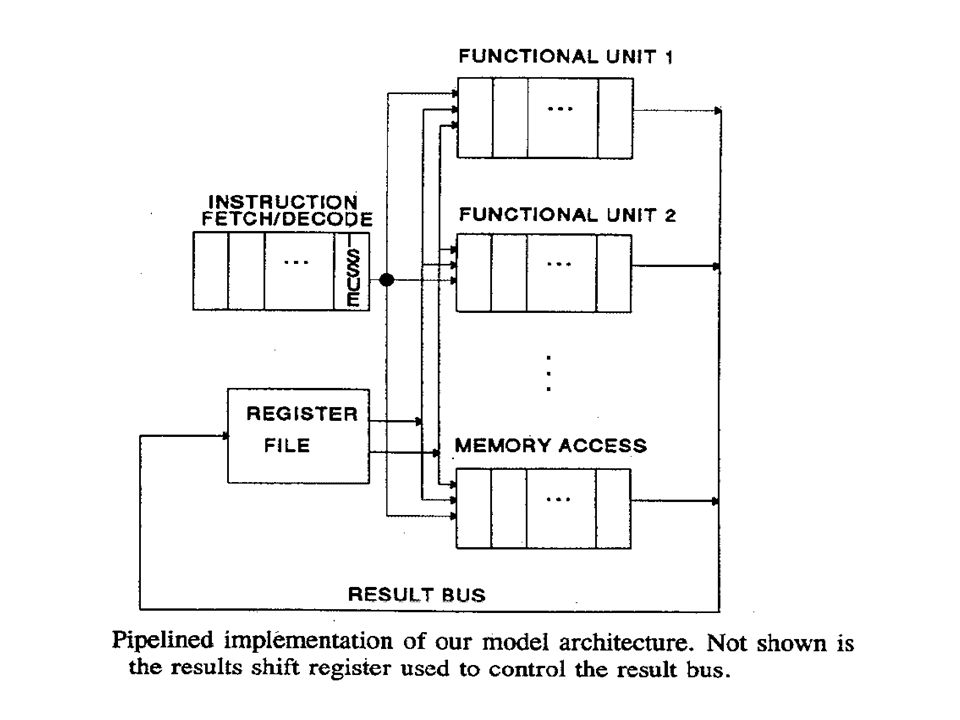
Preliminaries Model Architecture Register-register architecture Load: R i = (R j +disp.) Store: (R i +disp.) = R j Function: R i = R j op R k / R i = op R k Condition: P = disp: Ri op R k Process state General purpose registers Main memory Program counter (PC)
 Store: (R i +disp.) = R j Function: R i = R j op R k / R i = op R k Condition: P = disp: Ri op R k Process state General purpose registers Main memory Program counter (PC)")
10
Interrupts Prior to Instruction Issue Before an instruction is issued, the interrupt occurs. The instruction issuing is halted. And wait a while until all previously issued instructions complete.

11
Precise Interrupts Methods in pipelined processors In-Order Instruction Completion Reorder Buffer Reorder Buffer with Bypass paths History Buffer Future File

12
In-Order Instruction Completion Instructions modify the process state only when all previously issued instructions are known to be free of exception conditions.

13
In-Order Instruction Completion - result shift register

14
In-Order Instruction Completion - result shift register (cont ’ )
")
15
In-Order Instruction Completion - process state modification Registers Main memory Program Counter

16
out-of-order instruction completion methods Limitation of in-order completion: Fast instructions may sometimes get held up even if there is no dependency. Further block other instructions. 6. R4 R1 + fR3Floating add6 clock periods 7. R0 R0 + R5Inc. loop count2 clock periods Methods to allow out-of-order completion. Basic reorder buffer, Reorder buffer with bypass paths. History buffer, future file.

17
Basic reorder buffer method: Organization. Reorder buffer: Separate the process of completing instructions from instruction commit out-of-order completion. In-order commit. Reorder buffer is used to rearrange instructions before they commit.

18
Basic reorder buffer method: Structure. Result shift register TAG field will guide result and exception conditions to reorder buffer. Reorder buffer Tail: when an instruction issues, create one entry. Head: when it contains valid result, check and remove. Example: Two instructions ’ relative positions in the two buffers.

19
Basic reorder buffer: Keep precise process state Keep register value precise: No exception at the head: results are written to register file. Exception at the head: issue is stopped to process interrupt and no further writes to register file. Keep memory precise: Hold stores in the issue register until all previous instructions are known to be free of exceptions. Stores are issued. An dummy entry is put to reorder buffer. Keep program counter precise: Program counter is stored in one field of reorder buffer as instructions are issued.

20
Reorder buffer with bypass paths Limitation of basic reorder buffer. Operands are held in reorder buffer. Instructions dependent on operands can not be issued. Reorder buffer with bypass paths is proposed. Bypass paths are provided from reorder buffer to register file output latches.

21
Reorder buffer with bypass paths: precise process state. Keep precise register: Operands are not actually written to register file but to register file output latches. Register will not be modified until the instruction reaches the head of reorder buffer. Keep precise memory and PC Same as before

22
Methods to reduce bypass circuit. Limitation of reorder buffer with bypass paths : The number of bypass comparators and the amount of circuitry for multiple bypass check. History buffer, future file are proposed. Basic idea: place computed results in a working register file, but retain enough state information so a precise state can be restored.

23
History buffer: organization History buffer: Instruction issues: The current value of the destination register is stored to history buffer entry. Instruction completes: Results on the result bus are written directly into register file.

24
History buffer: Keep precise process state Keep register precise Tag field is used to guide exception to history buffer. Old values are kept when instruction issue. No exception: head is removed. Keep memory and PC precise Same as before Example: Old value in entry 4, 5.

25
Future file Similar to the history buffer method. Keep register precise:two register files. Architecture file: Future file: Keep memory and PC precise. Same as before.

26
Performance evaluation: Environment: CRAY-1S simulation system. The first 14 Lawrence Livermore loops are used as simulation workload. Five methods are classified as three groups: In-order completion. Simple reorder buffer Reorder buffer with bypass, history buffer, future file. Two evaluation cases based on different methods to handle store.

27
Performance evaluation(1) Measure condition: store blocked until the results pipeline is empty. In-order completion is independent on the number of entries. In-order completion is better if buffer is small. If the number of entries increases beyond 3,the other two are better.

28
Performance evaluation(2) Measure condition: Stores are issued and held in the memory pipeline. Second method to handle store offers a clear improvement over first method. Performance degradation for eight-entry reorder buffer with bypass paths is only 3 percent.

29
Indication from the methods. If the entries in the reorder buffer exceed a certain value, the performance will not be improved. In both of the two tables, the number is eight. Tradeoff between performance degradation and cost of implementing a method.

30
Outline Extensions Architectural Solutions Summary

31
Extensions Additional state information Virtual memory Cache memory

32
Other State Values State register Condition codes:

33
Virtual Memory Load/store instructions pass through the address translation section in order reserve time slots in the result pipeline and/or reorder buffer If addressing fault, the instruction and all subsequent load/store are cancelled

34
Virtual Memory: Using ROB Send the page fault to reorder buffer. Guide load/store to the correct reorder buffer using tag. Entry removed while reaching the head. Exception causes all further entries discarded.

35
Cache Memory Store-Through cache Write-Back cache

36
Architectural Solutions Freeze and dump Save program counters Save a sequence of instructions

37
Summary In-order instruction completion Reorder buffer Bypass paths, History buffer and Future file Extensions Architecture solutions

38
References: http://www.ece.umd.edu/cources/enee446.F2000/p3.pdf http://www.cs.uiowa.edu/~ghosh/9-19-02.pdf http://lmi17.cnam.fr./~anceau/Documents/moud.pdf http://www.netlib.org/benchmark/top500/reports/

Similar presentations




 Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers)>")
>")


 ECE1773 – Spring 2002 ILP, cont. Maintaining Sequential Appearance –Precise Interrupts –RUU approach to OoO Scheduling.>")



>")




>")

