Download presentation
Presentation is loading. Please wait.

1
Machine Reading at Web Scale Oren Etzioni www.cs.washington.edu/homes/etzioni

2
Tech and societal Context Moore’s Law

3
Text Explosion

4
Information Overload

5
5 Paradigm Shift: from retrieval to reading How is the iPad? Found 8,900 reviews; 85% positive. World Wide Web Information Food Chain Key points are… KnowItAll

6
6 Information Fusion What kills bacteria? What west coast, nano-technology companies are hiring? Compare Obama’s “buzz” versus Hillary’s? What is a quiet, inexpensive, 4-star hotel in Vancouver?

7
7 Crossing the Structure Chasm

8
8 Fundamental Hypotheses 1. massive, high-quality KB are invaluable 2.KBs can be learned automatically 3. KBs learned via Machine Reading 4.Reading can leverage the Web corpus 8

9
99 What is Machine Reading? Self-supervised understanding of text Information extraction + inference

10
10 Outline I.Motivation (impact: knowledge workers & AI) II.What is Machine Reading? III.Open Information Extraction (IE) IV.Learning Common-sense Knowledge Argument types via an LDA model V.Future work & Conclusions 10
 IV.Learning Common-sense Knowledge Argument types via an LDA model V.Future work & Conclusions 10.")
11
11 II. A Generic Machine Reader Given: –Corpus of text –Model of language –Hand-labeled training examples? –Ontology? –Human teacher? Output: KB 11

12
12 Anatomy of a Machine Reader Initialize KB Repeat: 1.Extractor(text, KB) Tuples (Arg1 predicate Arg2) (Edison invented the light bulb) 2.Integrator(Tuples) KB 12
 Tuples (Arg1 predicate Arg2) (Edison invented the light bulb) 2.Integrator(Tuples) KB 12")
13
13 Extraction Design Decisions What are the atoms? –sentences What syntactic processing? –NP chunking What semantic processing? –Tuple structure Source of training examples? –Existing resources 13

14
14 IE as Supervised Learning (E.g., Riloff ‘96, Soderland ’99) Find & label examples of each relation Manual labor linear in |relations| Learn relation-specific extractor + S. Smith formerly chairman of XYZ Corporation … ManagementSuccession Person-In Person-Out Organization Position formerly of Labeled Examples RelationExtractor = S. Smith formerly chairman of XYZ Corporation…

15
15 Semi-Supervised Learning Few hand-labeled examples Limit on the number of relations Relations are pre-specified Limits Macro Reading Alternative: self-supervised learning –Learner discovers relations on the fly (Sekine ’06) –Learner automatically labels examples per relation!
 –Learner automatically labels examples per relation!")
16
16 III. Open IE = Self-supervised IE (Banko, et. al, IJCAI ’07, ACL ‘08) Traditional IEOpen IE Input: Corpus + Hand- labeled Data Corpus + Existing resources Relations: Specified in Advance Discovered Automatically Complexity: Output: O(D * R) R relations Lexicalized, relation-specific O(D) D documents Relation- independent
 Traditional IEOpen IE Input: Corpus + Hand- labeled Data Corpus + Existing resources Relations: Specified in Advance Discovered Automatically Complexity: Output: O(D * R) R relations Lexicalized, relation-specific O(D) D documents Relation- independent.")
17
17 Integration Design How to represent beliefs & dependencies? –Count tuples (Downey & Etzioni AIJ ‘10) –Infer synonyms (Yates & Etzioni JAIR ’09) How to generate new beliefs? –Learn from extraction set 17
 –Infer synonyms (Yates & Etzioni JAIR ’09) How to generate new beliefs. –Learn from extraction set 17.")
18
TextRunner Demo Extraction run at Google on 500,000,000 high-quality Web pages.

19
19

20
20

21
21 TextRunner Precision (Banko PhD ’09)
")
22
22 How is Open IE Possible? There is a compact set of “relationship expressions” in English “Expressions” are relation-independent (Banko & Etzioni ACL ’08) (Russell & Norvig, 3 rd Ed.)
 (Russell & Norvig, 3 rd Ed.).")
23
23 CategoryPatternFrequency Verb E 1 Verb E 2 X established Y 37.8% Noun+Pre p E 1 NP Prep E 2 the X settlement with Y 22.8% Verb+Prep E 1 Verb Prep E 2 X moved to Y 16.0% Infinitive E 1 to Verb E 2 X to acquire Y 9.4% Modifier E 1 Verb E 2 NP X is Y winner 5.2% Coordinate n E 1 (and|,|-|:) E 2 NP X - Y deal 1.8% Coordinate v E 1 (and|,) E 2 Verb X, Y merge 1.0 Appositive E 1 NP (:|,)? E 2 X hometown : Y 0.8 Relation-Independent Patterns

24
24 Observations 95% of sample 8 (simplified) patterns! Applicability conditions complex “E1 Verb E2” 1.Kentucky Fried Chicken 2.Microsoft announced Tuesday that… Effective, but far from perfect!

25
25 Sample of Relations inhibits tumor growth in has a PhD injoined forces with is a person who studies voted in favor ofwon an Oscar for has a maximum speed of died from complications of mastered the art of gained fame as granted political asylum to is the patron saint of was the first person to identified the cause of wrote the book on

26
26 Number of Relations Yago 92 DBpedia 3.2 940 PropBank 3,600 VerbNet 5,000 WikiPedia InfoBoxes, f > 10 ~5,000 TextRunner 100,000+ (estimate) New TextRunner Extractor 1,500,000 (phrases)
 New TextRunner Extractor 1,500,000 (phrases)")
27
27 TextRunner Scalability “Any sentence” property ~100 sentences per second Linear in size of its corpus Rich, “open” vocabulary –100,000+ relations

28
28 Critique of TextRunner “Textual representation” –Q/A, synonymy, compositional inference Limited semantic model Lower per-sentence precision/recall –But we “make it up on volume!” TextRunner suffers from ADD What next?

29
29 Chase Wikipedia's long tail? Learn common-sense knowledge not in Wikipedia!

30
30 IV. Learn Common Sense Knowledge What are the relationships in text? Horn Clauses: Prevents(F,D) :- Contains(F,N) ^ Prevents(N,D) Infer Meta-properties of relations: –Time-dependent? Functional? –Transitive? Symmetric? –Mutually exclusive? –Argument types (“selectional preferences”)
 :- Contains(F,N) ^ Prevents(N,D) Infer Meta-properties of relations: –Time-dependent. Functional. –Transitive. Symmetric. –Mutually exclusive. –Argument types ( selectional preferences ).")
31
31 Argument Typing Example: P was born in X –P is a person –X is location or date Numerous Applications: Prune incorrect extractions Update probability of inferred assertions Aid syntactic processing: “The couple will meet in Miami, which is located in Florida.”

32
32 Text Argument Types? Previous work (Resnick, Pantel, etc.) Utilize generative topic models Topics Terms document relation + args = “document”
 Utilize generative topic models Topics Terms document relation + args = document .")
33
33 born_in(Einstein,Ulm) headquartered_in(Microsoft,Redmond) founded_in(Microsoft,1973) born_in(Bill Gates,Seattle) founded_in(Google,1998) headquartered_in(Google,Mountain View) born_in(Sergey Brin,Moscow) founded_in(Microsoft, Albuquerque) born_in(Einstein,March) born_in(Sergey Brin,1973) TextRunner ExtractionsRelations as Documents
 headquartered_in(Microsoft,Redmond) founded_in(Microsoft,1973) born_in(Bill Gates,Seattle) founded_in(Google,1998) headquartered_in(Google,Mountain View) born_in(Sergey Brin,Moscow) founded_in(Microsoft, Albuquerque) born_in(Einstein,March) born_in(Sergey Brin,1973) TextRunner ExtractionsRelations as Documents")
34
34 Argument “docs” Type Models

35
35 Args can have multiple Types

36
36 LDA Generative “Story” z a R N T For each type, pick a random distribution over words Topic 1: Location P(New York|T1)=0.02 P(Moscow|T1)=0.001 … Topic 2: Date P(June|T2)=0.0005 P(1988|T2)=0.0002 … For each relation, randomly pick a distribution over types born_in X P(Location| born_in )=0.5 P(Date| born_in )=0.3 … For each extraction, first pick a type Then pick an argument based on type born_in Location born_in New York born_in Date born_in 1988 Prior over Word Distributions Prior over Type Distributions
=0.02 P(Moscow|T1)=0.001 … Topic 2: Date P(June|T2)= P(1988|T2)= … For each relation, randomly pick a distribution over types born_in X P(Location| born_in )=0.5 P(Date| born_in )=0.3 … For each extraction, first pick a type Then pick an argument based on type born_in Location born_in New York born_in Date born_in 1988 Prior over Word Distributions Prior over Type Distributions")
37
37 Dependencies between arguments Problem: LDA treats each argument independently Many type pairs co-occur –(Person, Location) –(Politician, Political Issue) Solution: LinkLDA (Erosheva et al. ‘04) –Both args generated by a common –reduces sparsity and improves generalization
 –Both args generated by a common –reduces sparsity and improves generalization.")
38
38 z1 a1 R N z2 a2 TT LinkLDA [Erosheva et. al. 2004] z a R N T
![38 z1 a1 R N z2 a2 TT LinkLDA [Erosheva et. al. 2004] z a R N T ](http://images.slideplayer.com/34/8269780/slides/slide_38.jpg "38 z1 a1 R N z2 a2 TT LinkLDA [Erosheva et. al. 2004] z a R N T ")
39
39 z1 a1 R N z2 a2 TT LinkLDA [Erosheva et. al. 2004] Pick a topic for arg2 For each extraction, pick type for a1, a2 Person born_in Location Pick a topic for arg2 Then pick arguments based on types Sergey Brin born_in Moscow For each relation, randomly pick a distribution over types X born_in Y P(Topic1| born_in )=0.5 P(Topic2| born_in )=0.3 … Pick a topic for arg2 Two separate sets of type distributions
=0.5 P(Topic2| born_in )=0.3 … Pick a topic for arg2 Two separate sets of type distributions.")
40
40 Type Modeling in LDA-SP Infer distributions and parameters from the data (unsupervised) Sparse priors relatively few types per relation Collapsed Gibbs Sampling –Easy to implement, linear in corpus size!
 Sparse priors relatively few types per relation Collapsed Gibbs Sampling –Easy to implement, linear in corpus size!")
41
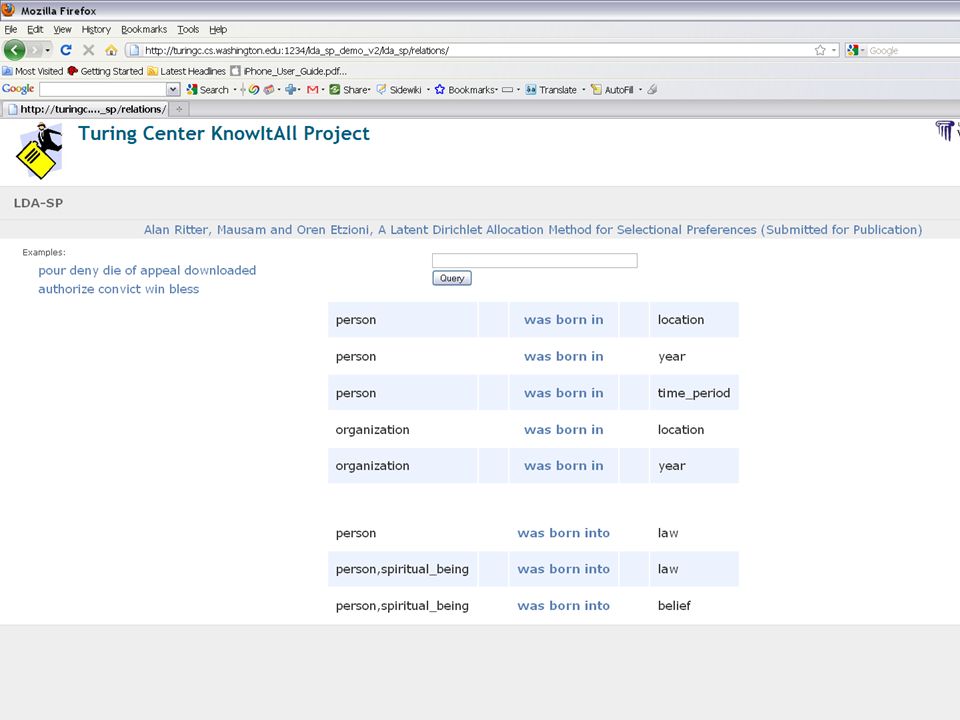
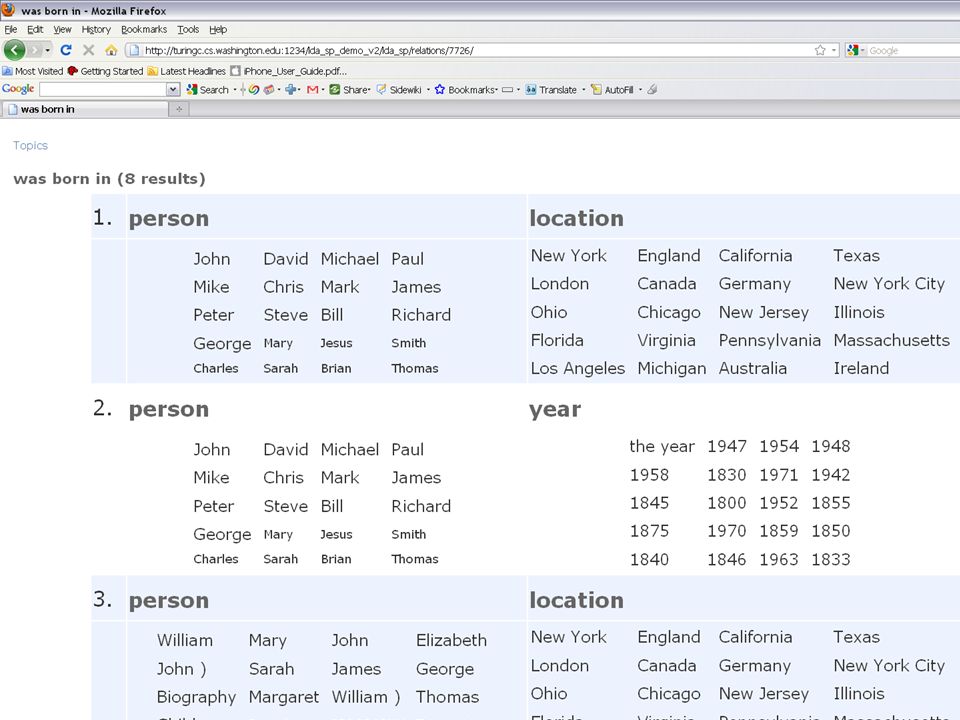
41 Repository of Types Associated 600 LinkLDA types to Wordnet –2 hours of manual labor. Compiled arg. types for 10,000 relations precision 0.88 Demo: www.cs.washington.edu/research/ldasp www.cs.washington.edu/research/ldasp

44
44 V. Future Work Machine Reading Machine Reading meets structured data Develop coherent and complete theories! Apply to Web Search

45
45 Conclusions Machine Reading of the Web is a rich platform for NLP and AI (VLSAI) Related work at: UW, CMU, Stanford, ISI, UIUC, NYU, BBN, SRI, IBM, Cycorp, etc. Our focus is on relation-rich, Web-scale extraction common sense knowledge

Similar presentations