Download presentation
Presentation is loading. Please wait.

1
Sentence Compression Based on ILP Decoding Method Hongling Wang, Yonglei Zhang, Guodong Zhou NLP Lab, Soochow University

2
Introduction Related Work Sentence Compression based on ILP Experiments Conclusion Outline

3
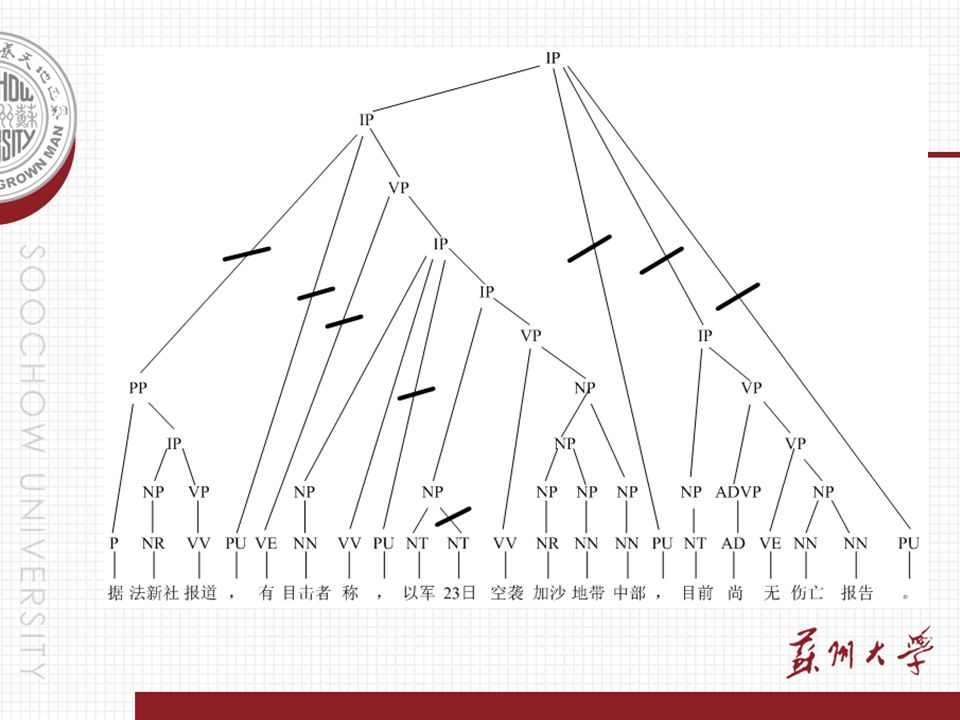
Introduction(1) Definition of Sentence Compression –It aims to shorten a sentence x=l 1,l 2,……,l n into a substring y=c 1,c 2,……c m, where c i ∈ { l 1,l 2,……,l n }. Example: –Original Sentence: 据法新社报道,有目击者称,以 军 23 日空袭加沙地带中部,目前尚无伤亡报告。 –Target Sentence: 目击者称以军空袭加沙地带中部

4
Introduction(2) Sentence compression has been widely used in: –Summarization –Automatic title generation –Searching engine –Topic detection –…
 Sentence compression has been widely used in: –Summarization –Automatic title generation –Searching engine –Topic detection –…")
5
Related Work(1) Mainstream solution – corpus-driven supervised leaning –Generative model To select the optimal target sentence by estimating the joint probability P(x, y) of original sentence x having the target sentence y. –Discriminative model

6
Related Work(2) Generative model –Knight & Marcu (2002) firstly apply the noisy- channel model for sentence compression. –Shortcomings: the source model is trained on uncompressed sentences – inaccurate data the channel model requires aligned parse trees for both compressed and uncompressed sentences in the training set -- alignment difficult and the channel probability estimates unreliable

7
Related Work(3) Discriminative model –McDonald(2006) used max-margin relaxed algorithm (MIRA) to study the feature weight, then rank the subtrees, and finally select the tree with the highest score as the optimal target sentence. –Cohn & Lapata (2007, 2008, and 2009) formulated the compression problem as tree-to-tree rewriting using a synchronous grammar. Each grammar rule is assigned a weight which is learned discriminatively within a large margin model. –Zhang et al. (2013) compressed sentences based on Structured SVM model which treats the compression problem as a structured learning problem
 formulated the compression problem as tree-to-tree rewriting using a synchronous grammar. Each grammar rule is assigned a weight which is learned discriminatively within a large margin model. –Zhang et al. (2013) compressed sentences based on Structured SVM model which treats the compression problem as a structured learning problem.")
8
Our Method The sentence compression problem is treated as a structured learning problem followed Zhang et al.(2013) –Learning a subtree from the original sentence parse tree as its compressed sentence –Formulating the problem of finding the optimal subtree to an ILP decoding problem
 –Learning a subtree from the original sentence parse tree as its compressed sentence –Formulating the problem of finding the optimal subtree to an ILP decoding problem")
10
The Framework of SC

11
Sentence Compression based on ILP Linear objective function x is the original sentence syntactic tree, y is the target subtree is the feature function of bi-gram and trimming features from x to y, w is the vector of feature weight

12
Linear constrains n i for each non-terminal node – where n i is the parent node of n j w i for each terminal node – w i = n j, where n j is the POS node of word w i f i for the i th feature –if f i =1 , the i th feature appears; or, the feature doesn’t appear – According to the restrictions of feature value, the corresponding linear constrains are added –f i =1-w i

13
Features – Word/POS Features –the remaining word’s bigram POS PosBigram ( 目击者 称 ) = NN&VV –whether the dropped word is a stop word IsStop ( 据 ) = 1 –whether the dropped word is the headword of the original sentence –the number of remaining words.
 = NN&VV –whether the dropped word is a stop word IsStop ( 据 ) = 1 –whether the dropped word is the headword of the original sentence –the number of remaining words.")
14
Features – Syntax features the parent-children relationship of the cutting edge –del-Edge (PP) = IP-PP the number of the cutting edge the dependant relation between the dropped word and its dependence word –dep_type( 有 )=DEP the relation chain of the dropped word’s POS with its dependence word’s POS –dep_link ( , ) = PU-VMOD-VV whether the dependence tree’s root is deleted –del_ROOT ( 无 ) = 1 whether each dropped word is a leaf of the dependence tree –del_Leaf ( 法新社 ) = 1
 = IP-PP the number of the cutting edge the dependant relation between the dropped word and its dependence word –dep_type( 有 )=DEP the relation chain of the dropped word’s POS with its dependence word’s POS –dep_link ( , ) = PU-VMOD-VV whether the dependence tree’s root is deleted –del_ROOT ( 无 ) = 1 whether each dropped word is a leaf of the dependence tree –del_Leaf ( 法新社 ) = 1")
15
Loss Function Function 1 –the loss ratio of bigram of the remaining word in original sentence Function 2: word loss-based function –the sum of the number of the words deleted by mistake and the number of the words remained by mistake between the predict sentence and the gold target sentence

16
Evaluation manual evaluation –Importance –Grammaticality automatic evaluation –compression ratio (CR) (0.7~10) – BLEU score
 (0.7~10) – BLEU score")
17
Experimental settings Parallel corpus extracted from news documents Stanford Parser Alignment tool developed by our own Structured SVM

18
Experimental results Compared to the McDonald’s decoding method, the system based ILP decoding method achieves a comparable performance using simpler and less features

19
Conclusions the problem of sentence compression is formulated as a problem of finding an optimal sub-tree using ILP decoding method. Compared to the work using McDonald’s decoding method, the system which only uses simpler and fewer features achieves a comparable performance on same conditions.

Similar presentations




 Ryan McDonald, Fernando.>")














. Introduction to LSA Learning Model Uses Singular Value Decomposition (SVD) to simulate human learning of word and passage.>")