Download presentation
Presentation is loading. Please wait.

1
Predictively Modeling Social Text William W. Cohen Machine Learning Dept. and Language Technologies Institute School of Computer Science Carnegie Mellon University Joint work with: Amr Ahmed, Andrew Arnold, Ramnath Balasubramanyan, Frank Lin, Matt Hurst (MSFT), Ramesh Nallapati, Noah Smith, Eric Xing, Tae Yano
, Ramesh Nallapati, Noah Smith, Eric Xing, Tae Yano.")
2
Document modeling with Latent Dirichlet Allocation (LDA) z w M N For each document d = 1, ,M Generate d ~ Dir(¢ | ) For each position n = 1, , N d generate z n ~ Mult( ¢ | d ) generate w n ~ Mult( ¢ | z n )
 z w M N For each document d = 1, ,M Generate d ~ Dir(¢ | ) For each position n = 1, , N d generate z n ~ Mult( ¢ | d ) generate w n ~ Mult( ¢ | z n )")
3
Hyperlink modeling using LinkLDA [Erosheva, Fienberg, Lafferty, PNAS, 2004] z w M N For each document d = 1, ,M Generate d ~ Dir(¢ | ) For each position n = 1, , N d generate z n ~ Mult( ¢ | d ) generate w n ~ Mult( ¢ | z n ) For each citation j = 1, , L d generate z j ~ Mult(. | d ) generate c j ~ Mult(. | z j ) z c L Learning using variational EM
![Hyperlink modeling using LinkLDA [Erosheva, Fienberg, Lafferty, PNAS, 2004] z w M N For each document d = 1, ,M Generate d ~ Dir(¢ | ) For each position n = 1, , N d generate z n ~ Mult( ¢ | d ) generate w n ~ Mult( ¢ | z n ) For each citation j = 1, , L d generate z j ~ Mult(.](http://images.slideplayer.com/25/8102615/slides/slide_3.jpg "| d ) generate c j ~ Mult(. | z j ) z c L Learning using variational EM.")
4
Author-Topic Model for Scientific Literature [Rozen-Zvi, Griffiths, Steyvers, Smyth UAI, 2004] z w M N For each author a = 1, ,A Generate a ~ Dir(¢ | ) For each topic k = 1, ,K Generate k ~ Dir( ¢ | ) For each document d = 1, ,M For each position n = 1, , N d Generate author x ~ Unif(¢ | a d ) generate z n ~ Mult( ¢ | a ) generate w n ~ Mult( ¢ | z n ) x a A P K
![Author-Topic Model for Scientific Literature [Rozen-Zvi, Griffiths, Steyvers, Smyth UAI, 2004] z w M N For each author a = 1, ,A Generate a ~ Dir(¢ | ) For each topic k = 1, ,K Generate k ~ Dir( ¢ | ) For each document d = 1, ,M For each position n = 1, , N d Generate author x ~ Unif(¢ | a d ) generate z n ~ Mult( ¢ | a ) generate w n ~ Mult( ¢ | z n ) x a A P K](http://images.slideplayer.com/25/8102615/slides/slide_4.jpg "Author-Topic Model for Scientific Literature [Rozen-Zvi, Griffiths, Steyvers, Smyth UAI, 2004] z w M N For each author a = 1, ,A Generate a ~ Dir(¢ | ) For each topic k = 1, ,K Generate k ~ Dir( ¢ | ) For each document d = 1, ,M For each position n = 1, , N d Generate author x ~ Unif(¢ | a d ) generate z n ~ Mult( ¢ | a ) generate w n ~ Mult( ¢ | z n ) x a A P K")
5
Labeled LDA: [ Ramage, Hall, Nallapati, Manning, EMNLP 2009]
![Labeled LDA: [ Ramage, Hall, Nallapati, Manning, EMNLP 2009]](http://images.slideplayer.com/25/8102615/slides/slide_5.jpg "Labeled LDA: [ Ramage, Hall, Nallapati, Manning, EMNLP 2009]")
6
Labeled LDA Del.icio.us tags as labels for documents

7
Labeled LDA

8
Author-Topic-Recipient model for email data [McCallum, Corrada-Emmanuel,Wang, ICJAI’05]
![Author-Topic-Recipient model for data [McCallum, Corrada-Emmanuel,Wang, ICJAI’05]](http://images.slideplayer.com/25/8102615/slides/slide_8.jpg "Author-Topic-Recipient model for data [McCallum, Corrada-Emmanuel,Wang, ICJAI’05]")
9
“SNA” = Jensen-Shannon divergence for recipients of messages

10
Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Copycat model of citation influence c is a cited document s is a coin toss to mix γ and plaigarism innovation
![Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Copycat model of citation influence c is a cited document s is a coin toss to mix γ and plaigarism innovation](http://images.slideplayer.com/25/8102615/slides/slide_10.jpg "Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Copycat model of citation influence c is a cited document s is a coin toss to mix γ and plaigarism innovation")
11
s is a coin toss to mix γ and

12
Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Citation influence graph for LDA paper
![Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Citation influence graph for LDA paper](http://images.slideplayer.com/25/8102615/slides/slide_12.jpg "Modeling Citation Influences [Dietz, Bickel, Scheffer, ICML 2007] Citation influence graph for LDA paper")
13
Modeling Citation Influences

14
User study: self- reported citation influence on Likert scale LDA-post is Prob(cited doc|paper) LDA-js is Jensen-Shannon dist in topic space
 LDA-js is Jensen-Shannon dist in topic space")
15
Models of hypertext for blogs, scientific literature [ICWSM 2008, KDD 2008] Ramesh Nallapati me Amr Ahmed Eric Xing
![Models of hypertext for blogs, scientific literature [ICWSM 2008, KDD 2008] Ramesh Nallapati me Amr Ahmed Eric Xing](http://images.slideplayer.com/25/8102615/slides/slide_15.jpg "Models of hypertext for blogs, scientific literature [ICWSM 2008, KDD 2008] Ramesh Nallapati me Amr Ahmed Eric Xing")
16
LinkLDA model for citing documents Variant of PLSA model for cited documents Topics are shared between citing, cited Links depend on topics in two documents Link-PLSA-LDA

17
Stochastic Block models: assume 1) nodes w/in a block z and 2) edges between blocks z p,z q are exchangeable zpzp zqzq a pq N2N2 zpzp N p Gibbs sampling: Randomly initialize z p for each node p. For t = 1… For each node p Compute z p given other z’s Sample z p See: Snijders & Nowicki, 1997, Estimation and Prediction for Stochastic Blockmodels for Groups with Latent Graph Structure

18
Mixed Membership Stochastic Block models pp qq zp.zp. z.qz.q a pq N2N2 pp N p Airoldi et al, JMLR 2008

19
Pairwise Link-LDA z w N z w N z z c

20
Pairwise Link-LDA supports new inferences… …but doesn’t perform better on link prediction

23
Want to predict linkage based on similarity of topic distributions. Using Z’s rather than θ’s: In Gibbs sampling the z’s are more accessible than the θ’s. Only observed links are modeled but higher link probabilities are penalized Component-wise product of expectation over topics is used as feature for a logistic regression function

24
Experiments Three hypertext corpora: WebKB, PNAS, Cora Each about 50-100k words, 1-3k documents, 1.5-5k links

27
Experiments Three hypertext corpora: WebKB, PNAS, Cora Each about 50-100k words, 1-3k documents, 1.5-5k links Measure perplexity in predicting links from words, words from links

28
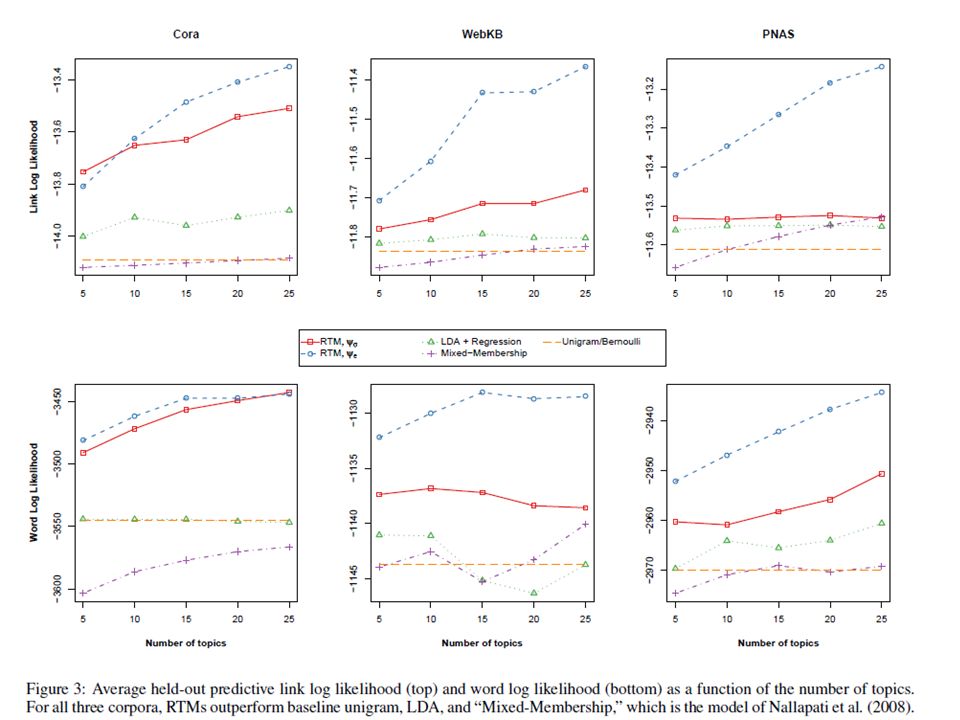
Link prediction

29
Word prediction

30
Link predictionWord prediction

32
Predicting Response to Political Blog Posts with Topic Models [NAACL ’09] Tae Yano Noah Smith
![Predicting Response to Political Blog Posts with Topic Models [NAACL ’09] Tae Yano Noah Smith](http://images.slideplayer.com/25/8102615/slides/slide_32.jpg "Predicting Response to Political Blog Posts with Topic Models [NAACL ’09] Tae Yano Noah Smith")
33
33 Political blogs and and comments Comment style is casual, creative, less carefully edited Posts are often coupled with comment sections

34
Political blogs and comments Most of the text associated with large “A-list” community blogs is comments –5-20x as many words in comments as in text for the 5 sites considered in Yano et al. A large part of socially-created commentary in the blogosphere is comments. –Not blog blog hyperlinks Comments do not just echo the post

35
Modeling political blogs Our political blog model: CommentLDA D = # of documents; N = # of words in post; M = # of words in comments z, z` = topic w = word (in post) w`= word (in comments) u = user
 w`= word (in comments) u = user")
36
Modeling political blogs Our proposed political blog model: CommentLDA LHS is vanilla LDA D = # of documents; N = # of words in post; M = # of words in comments

37
Modeling political blogs Our proposed political blog model: CommentLDA RHS to capture the generation of reaction separately from the post body Two separate sets of word distributions D = # of documents; N = # of words in post; M = # of words in comments Two chambers share the same topic-mixture

38
Modeling political blogs Our proposed political blog model: CommentLDA User IDs of the commenters as a part of comment text generate the words in the comment section D = # of documents; N = # of words in post; M = # of words in comments

39
Modeling political blogs Another model we tried: CommentLDA This is a model agnostic to the words in the comment section! D = # of documents; N = # of words in post; M = # of words in comments Took out the words from the comment section! The model is structurally equivalent to the LinkLDA from (Erosheva et al., 2004)
.")
40
40 Topic discovery - Matthew Yglesias (MY) site
 site")
41
41 Topic discovery - Matthew Yglesias (MY) site
 site")
42
42 Topic discovery - Matthew Yglesias (MY) site
 site")
43
Ramnath Balasubramanyan, William W. Cohen ICML WS 2010, SDM 2011 Language Technologies Institute and Machine Learning Department, School of Computer Science, Carnegie Mellon University, Joint Modeling of Entity-Entity Links and Entity-Annotated Text

44
Motivation: Toward Re-usable “Topic Models” LDA inspired many similar “topic models” –“Topic models” = generative models of selected properties of data (e.g., LDA: word co-occurance in a corpus, sLDA: word co-occurance and document labels,..., RelLDA, Pairwise LinkLDA: words and links in hypertext, …) LDA-like models are surprisingly hard to build –Conceptually modular, but nontrivial to implement –High-level toolkits like HBC, BLOG, … have had limited success –An alternative: general-purpose families of models than can be reconfigured and re-tasked for different purposes Somewhere between a modeling language (like HBC) and a task-specific LDA-like topic model
 LDA-like models are surprisingly hard to build –Conceptually modular, but nontrivial to implement –High-level toolkits like HBC, BLOG, … have had limited success –An alternative: general-purpose families of models than can be reconfigured and re-tasked for different purposes Somewhere between a modeling language (like HBC) and a task-specific LDA-like topic model")
45
Motivation: Toward Re-usable “Topic” Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications (Eroshova et al, 2004) z word M N z cite L
 z word M N z cite L")
46
Motivation: Toward Re-usable “Topic” Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs (Yano et al, NAACL 2009) z word M N z userId L
 z word M N z userId L")
47
Motivation: Toward Re-usable “Topic” Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs Re-used to model selectional restrictions for information extraction (Ritter et al, ACL 2010) z subj M N z obj L
 z subj M N z obj L")
48
Motivation: Toward Re-usable “Topic” Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs Re-used to model selectional restrictions for IE Extended and re-used to model multiple types of annotations (e.g., authors, algorithms) and numeric annotations (e.g., timestamps, as in TOT) z subj M N z obj L [Our current work]
![Motivation: Toward Re-usable Topic Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs Re-used to model selectional restrictions for IE Extended and re-used to model multiple types of annotations (e.g., authors, algorithms) and numeric annotations (e.g., timestamps, as in TOT) z subj M N z obj L [Our current work]](http://images.slideplayer.com/25/8102615/slides/slide_48.jpg "Motivation: Toward Re-usable Topic Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs Re-used to model selectional restrictions for IE Extended and re-used to model multiple types of annotations (e.g., authors, algorithms) and numeric annotations (e.g., timestamps, as in TOT) z subj M N z obj L [Our current work]")
49
Motivation: Toward Re-usable “Topic” Models Examples of re-use of LDA-like topic models: –LinkLDA model Proposed to model text and citations in publications Re-used to model commenting behavior on blogs Re-used to model selectional restrictions for information extraction What kinds of models are easy to re-use?

50
Motivation: Toward Re-usable “Topic” Models What kinds of models are easy to reuse? What makes re-use possible? What syntactic shape does information often take? –(Annotated) text: i.e., collections of documents, each containing a bag of words, and (one or more) bags of typed entities Simplest case: one type entity-annotated text Complex case: many entity types, time-stamps, … –Relations: i.e., k-tuples of typed entities Simplest case: k=2 entity-entity links Complex case: relational DB –Combinations of relations and annotated text are also common –Research goal: jointly model information in annotated text + set of relations This talk: –one binary relation and one corpus of text annotated with one entity type –joint model of both
 text: i.e., collections of documents, each containing a bag of words, and (one or more) bags of typed entities Simplest case: one type entity-annotated text Complex case: many entity types, time-stamps, … –Relations: i.e., k-tuples of typed entities Simplest case: k=2 entity-entity links Complex case: relational DB –Combinations of relations and annotated text are also common –Research goal: jointly model information in annotated text + set of relations This talk: –one binary relation and one corpus of text annotated with one entity type –joint model of both.")
51
Test problem: Protein-protein interactions in yeast Using known interactions between 844 proteins, curated by Munich Info Center for Protein Sequences (MIPS). Studied by Airoldi et al in 2008 JMLR paper (on mixed membership stochastic block models) Index of protein 1 Index of protein 2 p1, p2 do interact (sorted after clustering)
 Index of protein 1 Index of protein 2 p1, p2 do interact (sorted after clustering).")
52
Test problem: Protein-protein interactions in yeast Using known interactions between 844 proteins from MIPS. … and 16k paper abstracts from SGD, annotated with the proteins that the papers refer to (all papers about these 844 proteins). Vac1p coordinates Rab and phosphatidylinositol 3-kinase signaling in Vps45p-dependent vesicle docking/fusion at the endosome. The vacuolar protein sorting (VPS) pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase)...... EP7, VPS45, VPS34, PEP12, VPS21,… Protein annotations English text
. Vac1p coordinates Rab and phosphatidylinositol 3-kinase signaling in Vps45p-dependent vesicle docking/fusion at the endosome. The vacuolar protein sorting (VPS) pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase) EP7, VPS45, VPS34, PEP12, VPS21,… Protein annotations English text.")
53
Aside: Is there information about protein interactions in the text? MIPS interactions Thresholded text co-occurrence counts

54
Question: How to model this? Vac1p coordinates Rab and phosphatidylinositol 3-kinase signaling in Vps45p-dependent vesicle docking/fusion at the endosome. The vacuolar protein sorting (VPS) pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase)...... EP7, VPS45, VPS34, PEP12, VPS21 Protein annotations English text Generic, configurable version of LinkLDA
 pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase) EP7, VPS45, VPS34, PEP12, VPS21 Protein annotations English text Generic, configurable version of LinkLDA.")
55
Question: How to model this? Vac1p coordinates Rab and phosphatidylinositol 3-kinase signaling in Vps45p-dependent vesicle docking/fusion at the endosome. The vacuolar protein sorting (VPS) pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase)...... EP7, VPS45, VPS34, PEP12, VPS21 Protein annotations English text Instantiation z word M N z prot L
 pathway of Saccharomyces cerevisiae mediates transport of vacuolar protein precursors from the late Golgi to the lysosome-like vacuole. Sorting of some vacuolar proteins occurs via a prevacuolar endosomal compartment and mutations in a subset of VPS genes (the class D VPS genes) interfere with the Golgi-to-endosome transport step. Several of the encoded proteins, including Pep12p/Vps6p (an endosomal target (t) SNARE) and Vps45p (a Sec1p homologue), bind each other directly [1]. Another of these proteins, Vac1p/Pep7p/Vps19p, associates with Pep12p and binds phosphatidylinositol 3- phosphate (PI(3)P), the product of the Vps34 phosphatidylinositol 3-kinase (PI 3-kinase) EP7, VPS45, VPS34, PEP12, VPS21 Protein annotations English text Instantiation z word M N z prot L.")
56
Question: How to model this? Index of protein 1 Index of protein 2 p1, p2 do interact MMSBM of Airoldi et al 1.Draw K 2 Bernoulli distributions 2.Draw a θ i for each protein 3. For each entry i,j, in matrix a)Draw z i* from θ i b)Draw z *j from θ j c)Draw m ij from a Bernoulli associated with the pair of z’s.
Draw z i* from θ i b)Draw z *j from θ j c)Draw m ij from a Bernoulli associated with the pair of z’s..")
57
Question: How to model this? Index of protein 1 Index of protein 2 p1, p2 do interact Sparse block model of Parkinnen et al, 2007 These define the “blocks” we prefer… 1.Draw K 2 multinomial distributions β 2.For each row in the link relation: a)Draw (z L*, z *R ) from b)Draw a protein i from left multinomial associated with pair c)Draw a protein j from right multinomial associated with pair d) Add i,j to the link relation
Draw (z L*, z *R ) from b)Draw a protein i from left multinomial associated with pair c)Draw a protein j from right multinomial associated with pair d) Add i,j to the link relation.")
58
Gibbs sampler for sparse block model Sampling the class pair for a link probability of class pair in the link corpus probability of the two entities in their respective classes

59
BlockLDA: jointly modeling blocks and text Entity distributions shared between “blocks” and “topics”

60
Recovering the interaction matrix MIPS interactionsSparse Block modelBlock-LDA

61
Varying The Amount of Training Data

64
1/3 of links + all text for training; 2/3 of links for testing 1/3 of text + all links for training; 2/3 of docs for testing

65
Another Performance Test Goal: predict “functional categories” of proteins –15 categories at top-level (e.g., metabolism, cellular communication, cell fate, …) –Proteins have 2.1 categories on average –Method for predicting categories: Run with 15 topics Using held-out labeled data, associate topics with closest category If category has n true members, pick top n proteins by probability of membership in associated topic. –Metric: F1, Precision, Recall

66
Performance

67
Enron Email Corpus 96,103 emails in “sent folders” –Entities in header are “annotations” 200,404 links (sender-recipient)
")
70
Other Related Work Link PLSA LDA: Nallapati et al., 2008 - Models linked documents Nubbi: Chang et al., 2009, - Discovers relations between entities in text Topic Link LDA: Liu et al, 2009 - Discovers communities of authors from text corpora

71
Other related work

72
Conclusions Hypothesis: –relations + annotated text are a common syntactic representation of data, so joint models for this data should be useful –BlockLDA is an effective model for this sort of data Result: for yeast protein-protein interaction data –improvements in block modeling when entity- annotated text about the entities involved is added –improvements in entity perplexity given text when relational data about the entities involved is added

Similar presentations


















 Presented by Anson Liang.>")



 –sponsored by NIST and DARPA (1992-?) Comparing approaches.>")
>")
 Michal Rosen-Zvi (UCI) Thomas Griffiths (Stanford)>")


