Download presentation
Presentation is loading. Please wait.

1
Profiling and Tuning OpenACC Code

2
Profiling Tools (PGI) Use time option to learn where time is being spent -ta=nvidia,time NVIDIA Visual Profiler 3 rd -party profiling tools that are CUDA-aware (But those are outside the scope of this talk)
 Use time option to learn where time is being spent -ta=nvidia,time NVIDIA Visual Profiler 3 rd -party profiling tools that are CUDA-aware (But those are outside the scope of this talk)")
3
PGI Accelerator profiling Compiler automatically instruments the code, outputs profile data -ta=nvidia,time Accelerator Kernel Timing data /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 66: region entered 1000 times time(us): total=5515318 init=110 region=5515208 kernels=5320683 data=0 w/o init: total=5515208 max=13486 min=5269 avg=5515 70: kernel launched 1000 times grid: [16x512] block: [32x8] time(us): total=5320683 max=5426 min=5200 avg=5320 /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 53: region entered 1000 times time(us): total=6493657 init=171 region=6493486 kernels=5108494 data=0...
![PGI Accelerator profiling Compiler automatically instruments the code, outputs profile data -ta=nvidia,time Accelerator Kernel Timing data /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 66: region entered 1000 times time(us): total= init=110 region= kernels= data=0 w/o init: total= max=13486 min=5269 avg= : kernel launched 1000 times grid: [16x512] block: [32x8] time(us): total= max=5426 min=5200 avg=5320 /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 53: region entered 1000 times time(us): total= init=171 region= kernels= data=0...](http://images.slideplayer.com/25/8032906/slides/slide_3.jpg "PGI Accelerator profiling Compiler automatically instruments the code, outputs profile data -ta=nvidia,time Accelerator Kernel Timing data /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 66: region entered 1000 times time(us): total= init=110 region= kernels= data=0 w/o init: total= max=13486 min=5269 avg= : kernel launched 1000 times grid: [16x512] block: [32x8] time(us): total= max=5426 min=5200 avg=5320 /usr/users/7/jwoolley/openacc-workshop/solutions/003-laplace2D-loop/laplace2d.c main 53: region entered 1000 times time(us): total= init=171 region= kernels= data=0...")
4
PGI Accelerator profiling Compiler automatically instruments the code, outputs profile data Provides insight into API-level efficiency How many bytes of data were copied in and out? How many times was each kernel launched, and how long did they take? What kernel grid and block dimensions were used? …but provides relatively little insight (at present) into how efficient the kernels themselves were
 into how efficient the kernels themselves were.")
5
Profiling Tools Need a profiling tool that is more aware of the inner workings of the GPU to provide deeper insights E.g.: NVIDIA Visual Profiler

6
NVIDIA Visual Profiler

7
Note: Today we are using the CUDA 4.0 Visual Profiler CUDA 4.1 and later include a revamped profiler called nvvp Try it on your own codes after the workshop

8
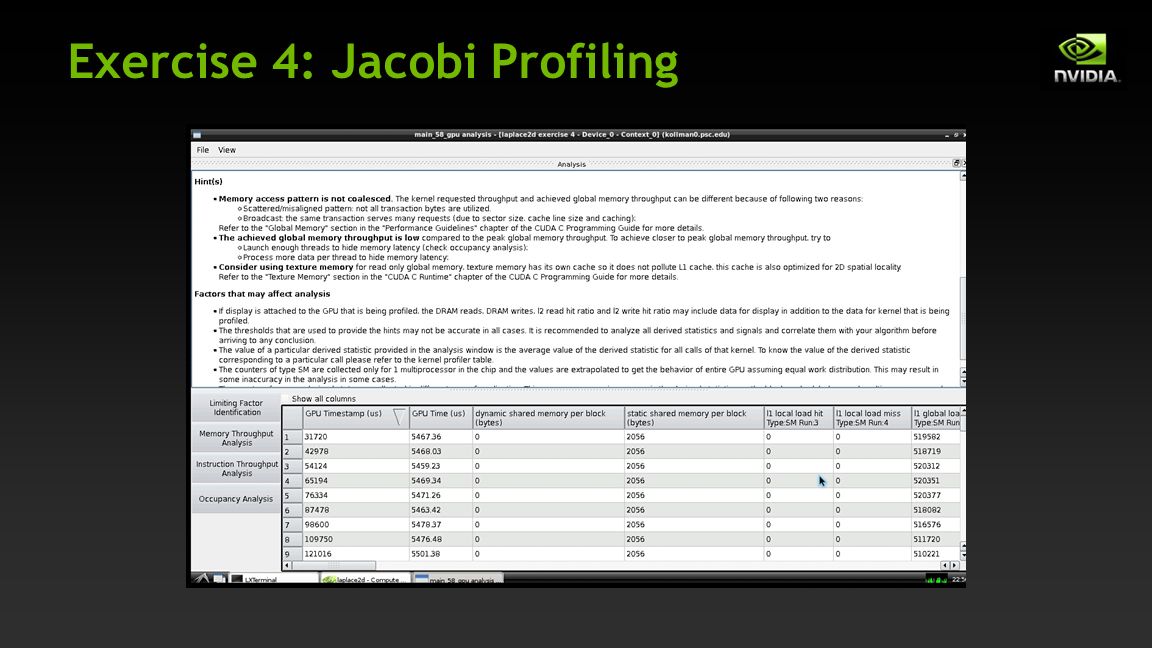
Exercise 4: Jacobi Profiling Task: use NVIDIA Visual Profiler data to identify additional optimization opportunities in Jacobi example Start from given laplace2d.c or laplace2d.f90 (your choice) In the 004-laplace2d-profiling directory Use computeprof to examine the provided laplace2d.cvp project Identify areas for possible improvement Modify code where it helps (hint: look at bandwidth utilization) Q: What speedup can you get by improving the kernels? Does it help the CPU code as well? By how much?

9
Exercise 4: Jacobi Profiling

13
NVIDIA Visual Profiler: PSC Workshop Tips for use of computeprof in PSC’s shared environment: If you need to profile your own code, submit a PBS job that lets you run computeprof via remote-X on the compute node Your profiling session on the compute node will be limited to 5 minutes Set the timeout for each profile pass in the profiler to 5 seconds (default is 30 seconds) SAVE YOUR SESSION as soon as the profile has been gathered and exit the profiler to release the compute node Use an instance of computeprof running on the login node to study the saved session offline while someone else uses the compute node For this exercise, please try to use ONLY the pre-saved profile if possible
 SAVE YOUR SESSION as soon as the profile has been gathered and exit the profiler to release the compute node Use an instance of computeprof running on the login node to study the saved session offline while someone else uses the compute node For this exercise, please try to use ONLY the pre-saved profile if possible")
14
Exercise 4 Solution: OpenACC C #pragma acc data copy(A), copyin(Anew) while ( error > tol && iter < iter_max ) { error=0.0; #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); } #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for( int i = 1; i < m-1; i++ ) { A[j][i] = 0.25 * (Anew[j][i+1] + Anew[j][i-1] + Anew[j-1][i] + Anew[j+1][i]); error = max(error, fabs(A[j][i] - Anew[j][i]); } iter+=2; } Need to switch back to copying Anew in to accelerator so that halo cells will be correct Replace memcpy kernel with a second instance of the stencil kernel Can calculate the max reduction on ‘error’ once per pair, so removed it from this loop Only need half as many times through the loop now
![Exercise 4 Solution: OpenACC C #pragma acc data copy(A), copyin(Anew) while ( error > tol && iter < iter_max ) { error=0.0; #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); } #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for( int i = 1; i < m-1; i++ ) { A[j][i] = 0.25 * (Anew[j][i+1] + Anew[j][i-1] + Anew[j-1][i] + Anew[j+1][i]); error = max(error, fabs(A[j][i] - Anew[j][i]); } iter+=2; } Need to switch back to copying Anew in to accelerator so that halo cells will be correct Replace memcpy kernel with a second instance of the stencil kernel Can calculate the max reduction on ‘error’ once per pair, so removed it from this loop Only need half as many times through the loop now](http://images.slideplayer.com/25/8032906/slides/slide_14.jpg "Exercise 4 Solution: OpenACC C #pragma acc data copy(A), copyin(Anew) while ( error > tol && iter < iter_max ) { error=0.0; #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); } #pragma acc kernels loop for( int j = 1; j < n-1; j++) { #pragma acc kernels gang(16) vector(32) for( int i = 1; i < m-1; i++ ) { A[j][i] = 0.25 * (Anew[j][i+1] + Anew[j][i-1] + Anew[j-1][i] + Anew[j+1][i]); error = max(error, fabs(A[j][i] - Anew[j][i]); } iter+=2; } Need to switch back to copying Anew in to accelerator so that halo cells will be correct Replace memcpy kernel with a second instance of the stencil kernel Can calculate the max reduction on ‘error’ once per pair, so removed it from this loop Only need half as many times through the loop now")
15
Exercise 4: Performance vs. original CPU: Intel Xeon X5680 6 Cores @ 3.33GHz GPU: NVIDIA Tesla M2070

16
Thank you

Similar presentations



 real :: x(:), y(:), a integer :: n, i $!acc kernels do i=1,n y(i) = a*x(i)+y(i) enddo.>")



,2) and Yunquan Zhang 1),3) 1) Laboratory of Parallel Software.>")








 cluster.>")




