Download presentation
Presentation is loading. Please wait.

1
Spatial Data Analysis of Areas: Regression

2
Introduction Basic Idea Dependent variable (Y) determined by independent variables X1,X2 (e.g., Y = mX + b). Uses of regression: Description Control Prediction

3
Simple Linear Regression Y i = 0 + 1 X i + i Y i value of dependent variable on trial i 0, 1 (unknown parameters) X i value of independent variable on trial i i i th error term (unexplained variation), where E [ i ]=0, 2 ( i )= 2 error terms are N(0, 2 ) basic model
![Simple Linear Regression Y i = 0 + 1 X i + i Y i value of dependent variable on trial i 0, 1 (unknown parameters) X i value of independent variable on trial i i i th error term (unexplained variation), where E [ i ]=0, 2 ( i )= 2 error terms are N(0, 2 ) basic model](http://images.slideplayer.com/25/8012756/slides/slide_3.jpg "Simple Linear Regression Y i = 0 + 1 X i + i Y i value of dependent variable on trial i 0, 1 (unknown parameters) X i value of independent variable on trial i i i th error term (unexplained variation), where E [ i ]=0, 2 ( i )= 2 error terms are N(0, 2 ) basic model")
4
Y i is the i th observation of the dependent variable are parameters are observations of the ind variables are independent and normal Multiple Regression Basic Model estimated model i th residual

5
Sometimes we need to transform the data Predicted versus Observed Plots: (a) model with variables not transformed): R 2 = 0.61; (b) Model 7: R 2 = 0.85. Scatter plots: (a) Y versus PORC3_NR (percentage of large farms in number ); (b) log10 Y versus log 10 (PORC3_NR).
 Y versus PORC3_NR (percentage of large farms in number ); (b) log10 Y versus log 10 (PORC3_NR)..")
6
Precision of estimates and fit Analysis of variation Sum of squares of Y = Sum of squares of estimate + Sum of squares of residuals Dividing both sides by TSS (sum of squares of Y): 1 = ESS/TSS + RSS/TSS where ESS/TSS = r 2 (coefficient of determination) r 2 gives the proportion of total variation “explained” by the sample regression equation. The closer is r 2 to 1.00, the better the fit.

7
Analysis of Residuals It is a good idea to plot the residuals against the independent variables to see if they show a trend. Possible behaviors: Correlation (e.g., the higher the independent variable, the higher the residual) Nonlinearity Heteroskedacity (i.e., the variance of the residual increases or decreases with the independent variable). Regression assumes that residuals are constant variance and normally distributed.
 Nonlinearity Heteroskedacity (i.e., the variance of the residual increases or decreases with the independent variable). Regression assumes that residuals are constant variance and normally distributed..")
8
Good Residual Plot -6 -4 -2 0 2 4 6 0204060 X Y

9
Nonlinearity -0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2 0.25 0204060 X residual

10
Heteroskedacity -0.5 0 0.5 1 0204060 residual X

11
Regression with Spatial Data: Understanding Deforestation in Amazonia

12
The forest...

14
The rains...

15
The rivers...

16
Deforestation...

17
Fire...

19
Amazon Deforestation 2003 Fonte: INPE PRODES Digital, 2004. Deforestation 2002/2003 Deforestation until 2002

20
What Drives Tropical Deforestation? Underlying Factors driving proximate causes Causative interlinkages at proximate/underlying levels Internal drivers *If less than 5%of cases, not depicted here. source:Geist &Lambin 5% 10% 50% % of the cases

21
1 9 7 3

22
1 9 9 1 Courtesy: INPE/OBT

23
1 9 9 9 Courtesy: INPE/OBT

24
Deforestation in Amazonia PRODES (Total 1997) = 532.086 km2 PRODES (Total 2001) = 607.957 km2
 = km2 PRODES (Total 2001) = km2")
25
Modelling Tropical Deforestation Fine: 25 km x 25 km grid Coarse: 100 km x 100 km grid Análise de tendências Modelos econômicos

26
Amazônia in 2015? fonte: Aguiar et al., 2004

27
Factors Affecting Deforestation

28
Coarse resolution: candidate models

29
Coarse resolution: Hot-spots map Terra do Meio, Pará State South of Amazonas State Hot-spots map for Model 7: (lighter cells have regression residual < -0.4)
")
30
Modelling Deforestation in Amazonia High coefficients of multiple determination were obtained on all models built (R 2 from 0.80 to 0.86). The main factors identified were: Population density; Connection to national markets; Climatic conditions; Indicators related to land distribution between large and small farmers. The main current agricultural frontier areas, in Pará and Amazonas States, where intense deforestation processes are taking place now were correctly identified as hot-spots of change.

31
Spatial regression models

32
Spatial regression Specifying the Structure of Spatial dependence which locations/observations interact Testing for the Presence of Spatial Dependence what type of dependence, what is the alternative Estimating Models with Spatial Dependence spatial lag, spatial error, higher order Spatial Prediction interpolation, missing values source: Luc Anselin

33
Nonspatial regression Objective Predict the behaviour of a response variable, given a set of known factors (explanatory variables). Multivariate nonspatial models y k = 0 + 1 x 1k +… + i x ik + i y k = estimate of response variable for object k i = regression coefficient for factor i x i = explanatory variable i for region k k = random error Adjustment quality R 2 =1– (y i –y i ) i =1 n (y i –y i ) i =1 n 2 2
 i =1 n (y i –y i ) i =1 n 2 2.")
34
Nonspatial regression: hypotheses Y = X + (model) Explanatory variables are linearly independent Y - vector of samples of response variable (n x 1) X – matrix of explanatory variables (n x k) - coefficient vector (k x 1) - error vector (n x 1) E( i ) = 0 ( expected value) i ~ N( 0, i 2 ) (normal distribution)
 Explanatory variables are linearly independent Y - vector of samples of response variable (n x 1) X – matrix of explanatory variables (n x k) - coefficient vector (k x 1) - error vector (n x 1) E( i ) = 0 ( expected value) i ~ N( 0, i 2 ) (normal distribution)")
35
Generalized linear models g(Y) = X + U Response is some function of the explanatory variables g(.) is a link function Ex: logarithm function U = error vector (U) = 0 (expected value) (UU T ) = C (covariance matrix) if C= 2 I, the error is homoskedastic
 = X + U Response is some function of the explanatory variables g(.) is a link function Ex: logarithm function U = error vector (U) = 0 (expected value) (UU T ) = C (covariance matrix) if C= 2 I, the error is homoskedastic")
36
Spatial regression Spatial effects What happens if the original data is spatially autocorrelated? The results will be influenced, showing statistical associated where there is none How can we evaluate the spatial effects? Measure the spatial autocorrelation (Moran’s I) of the regression residuals
 of the regression residuals.")
37
Regression using spatial data Try a linear model first Adjust the model and calculate residuals Are the residuals spatially autocorrelated? No, we’re OK Yes, nonspatial model will be biased and we should propose a spatial model

38
Spatial dependence Estimating the Form/Extent of Spatial Interaction substantive spatial dependence spatial lag models Correcting for the Effect of Spatial Spill-overs spatial dependence as a nuisance spatial error models source: Luc Anselin

39
Spatial dependence Substantive Spatial Dependence lag dependence include Wy as explanatory variable in regression y = ρWy + Xβ + ε Dependence as a Nuisance error dependence non-spherical error variance E[εε’] = Ω where Ω incorporates dependence structure
![Spatial dependence Substantive Spatial Dependence lag dependence include Wy as explanatory variable in regression y = ρWy + Xβ + ε Dependence as a Nuisance error dependence non-spherical error variance E[εε’] = Ω where Ω incorporates dependence structure](http://images.slideplayer.com/25/8012756/slides/slide_39.jpg "Spatial dependence Substantive Spatial Dependence lag dependence include Wy as explanatory variable in regression y = ρWy + Xβ + ε Dependence as a Nuisance error dependence non-spherical error variance E[εε’] = Ω where Ω incorporates dependence structure")
40
Interpretation of spatial lag True Contagion related to economic-behavioral process only meaningful if areal units appropriate (ecological fallacy) interesting economic interpretation (substantive) Apparent Contagion scale problem, spatial filtering source: Luc Anselin
 interesting economic interpretation (substantive) Apparent Contagion scale problem, spatial filtering source: Luc Anselin")
41
Interpretation of Spatial Error Spill-Over in “Ignored” Variables poor match process with unit of observation or level of aggregation apparent contagion: regional structural change economic interpretation less interesting nuisance parameter Common in Empirical Practice source: Luc Anselin

42
Cost of ignoring spatial dependence Ignoring Spatial Lag omitted variable problem OLS estimates biased and inconsistent Ignoring Spatial Error efficiency problem OLS still unbiased, but inefficient OLS standard errors and t-tests biased source: Luc Anselin

43
Spatial regression models Incorporate spatial dependency Spatial lag model Two explanatory terms One is the variable at the neighborhood Second is the other variables

44
Spatial regimes Extension of the non-spatial regression model Considers “clusters” of areas Groups each “cluster” in a different explanatory variable y i = 0 + 1 x 1 +… + i x i + i Gets different parameters for each “cluster”

45
A study of the spatially varying relationship between homicide rates and socio-economic data of São Paulo using GWR Frederico Roman Ramos CEDEST/Brasil

46
Extensão of traditional regression model where the parameters are estimaded locally (u i,v i ) are the geographical coordinates of point i. The betas vary in space (each location has a different coeficient) We estimate an ordinary regression for each point where the neighbours have more weight Geographically Weighted Regression
 We estimate an ordinary regression for each point where the neighbours have more weight Geographically Weighted Regression.")
47
Introducing São Paulo 30 Km 70 Km Some numbers : Metropolitan region: Population: 17,878,703 (ibge,200) 39 municipalities Municipality of São Paulo : Population: 10,434,252 HDI_M: 0.841 (pnud, 2000) 96 districts IEX: 74 out of 96 districts were classified as socially excluded (cedest,2002) 4,637 homicide victims in 2001
 39 municipalities Municipality of São Paulo : Population: 10,434,252 HDI_M: (pnud, 2000) 96 districts IEX: 74 out of 96 districts were classified as socially excluded (cedest,2002) 4,637 homicide victims in 2001")
48
Data 4,637 homicide victims residence geoadressed 2001 456 Census Sample Tracts 2000

49
Density surface of victim-based homicides Kernel Density Function Bandwidth = 3 Km Critical areas

50
Victim-based homicide rate ( Tx_homic ) Tx_homic = count homicide events (2001) *100.000 population (census, 2000)
 Tx_homic = count homicide events (2001) * population (census, 2000)")
51
LISA Victim-based homicide rate

52
Percentage of illiterate house-head ( Xanlf ) Definition House-head is the person responsible for the house. Generally, but not necessarily, who has the highest income of the house

53
LISA Percentage of illiterate house-head

54
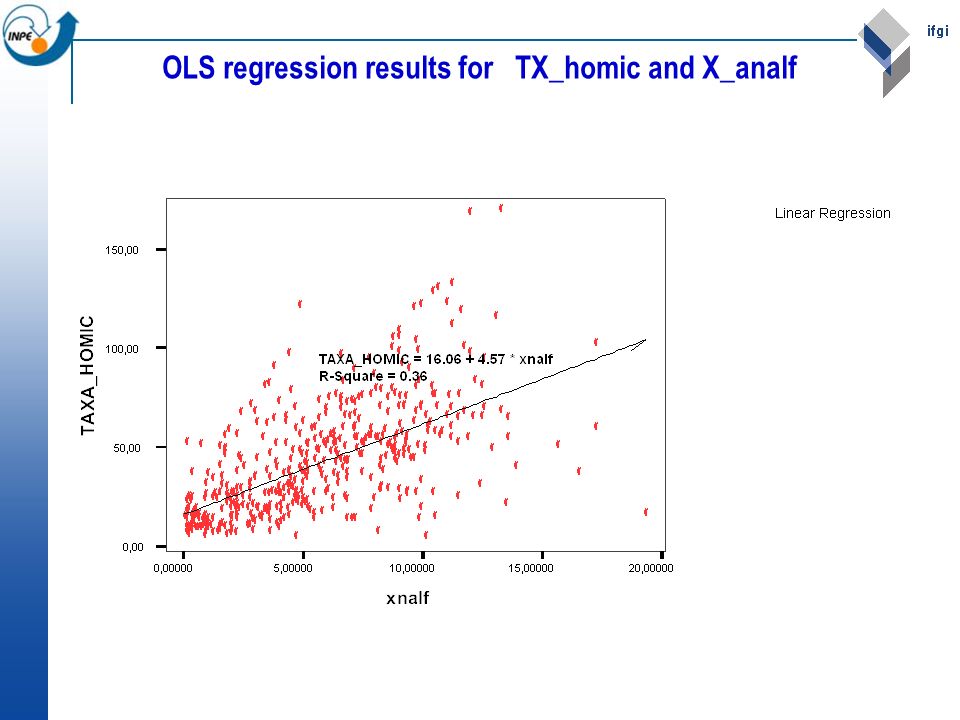
OLS regression results for TX_homic and X_analf

56
Moran=0,2624 LISA for standardized residuals of the OLS regression for TX_homic and X_analf

57
********************************************************** * GWR ESTIMATION * ********************************************************** Fitting Geographically Weighted Regression Model... Number of observations............ 456 Number of independent variables... 2 (Intercept is variable 1) Bandwidth (in data units)......... 0.0246524516 Number of locations to fit model.. 456 Diagnostic information... Residual sum of squares........ 111179.875 Effective number of parameters.. 83.1309998 Sigma.......................... 17.2677182 Akaike Information Criterion... 4007.32139 Coefficient of Determination... 0.699720224 GWR regression results for TX_homic and Xanlf
 Bandwidth (in data units) Number of locations to fit model Diagnostic information... Residual sum of squares Effective number of parameters Sigma Akaike Information Criterion Coefficient of Determination GWR regression results for TX_homic and Xanlf.")
58
Moran= -0,0303 GWR regression results for TX_homic and Xanlf residuals

59
GWR regression results for TX_homic and Xanlf Local Beta1Local t-value

60
CONCLUSIONS -There are significant differences in the relationship between violence rates and social territorial data over the intra-urban area of São Paulo -This results reinforces our hypotheses that we should avoid using general concepts -The GWR technique is a useful instrument in social territorial analysis

Similar presentations