Download presentation
Presentation is loading. Please wait.

1
Unit 6 Data Storage Design

2
Key Concepts 1. Database overview 2. SQL review 3. Designing fields 4. Denormalization 5. File organization 6. Object-relational database features

3
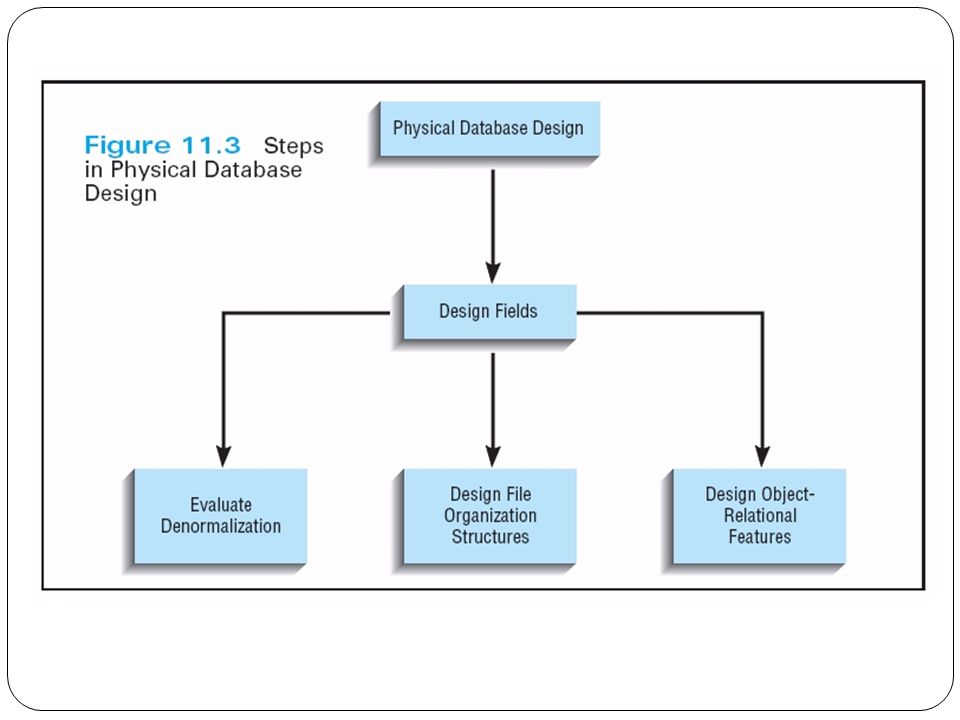
What Is Physical Database Design? The part of a database design that deals with efficiency considerations for access of data Key issues include: Processing speed Storage space Data manipulation and data access patterns

4
Sometimes, the analyst and the designer are the same person, Deliverables

6
What Is SQL? Structured Query Language Often pronounced “sequel” The standard language for creating and using relational databases ANSI Standards SQL-92 – most commonly available SQL-99 – included object-relational features

7
Common SQL Commands CREATE used to create databases and database objects. examples: CREATE TABLE CREATE DATABASE SELECT used to retrieve data using specified formats and selection criteria INSERT used to add new rows to a table UPDATE used to modify data in existing table rows DELETE used to remove rows from tables

8
Example CREATE TABLE Statement Here, a table called DEPT is created, with one numeric and two text fields. The numeric field is the primary key.

9
Example INSERT Statement This statement inserts a new row into the DEPT table DEPTNO’s value is 50 DNAME’s value is “DESIGN” LOC’s value is “MIAMI”

10
SELECT The SELECT, and FROM clauses are required. All others are optional. WHERE is used very commonly.

11
SELECT Statement: Example 1 Result: all fields of all rows in the DEPT table Select * from DEPT;

12
SELECT Statement: Example 2 Result: all fields for employee “Smith” Select * from EMP where ENAME = 'SMITH';

13
SELECT Statement: Example 3 Result: employee number, name and job for only salesmen from the EMP table, sorted by name Select EMPNO, ENAME From EMP where JOB = 'SALESMAN' order by ENAME;

14
What Is a Join Query? A query in which the WHERE clause includes a match of primary key and foreign key values between tables that share a relationship

15
SELECT Statement: Example 4 Result: all employees’ number and name (from the EMP table, and their associated department names, obtained by joining the tables based on DEPT_NO. Only employees housed in department located in Chicago will be included Select EMPNO, ENAME, DNAME from EMP, DEPT where EMP.DEPT_NO = DEPT.DEPT_NO and DEPT.LOC = 'CHICAGO';

16
SELECT Statement: Example 4 (cont.) Join queries almost always involve matching the primary key of the dominant table with the foreign key of the dependent table.
 Join queries almost always involve matching the primary key of the dominant table with the foreign key of the dependent table.")
17
What Is an Aggregation Query? A query results in summary information about a group of records, such as sums, counts, or averages These involve aggregate functions in the SELECT clause (SUM, AVG, COUNT) Aggregations can be filtered using the HAVING clause and/or grouped using the GROUP BY clause
 Aggregations can be filtered using the HAVING clause and/or grouped using the GROUP BY clause.")
18
SELECT Statement: Example 5 The job name and average salary for each job of employees in the EMP table. Only jobs with average salaries exceeding $3000 will be included Select JOB, Avg(SALARY) from EMP Group by JOB Having Avg(SALARY) >= 3000;
 from EMP Group by JOB Having Avg(SALARY) >= 3000;.")
19
SELECT Statement: Example 5 (cont.) Note that clerks and salesmen are not included, because the average salaries for these jobs are below $3000.
 Note that clerks and salesmen are not included, because the average salaries for these jobs are below $3000.")
20
Example Data Manipulation Modifies the existing employee’s (7698) salary Removes employee 7844 from the EMP table Update EMP set SAL = 3000 where EMPNO = 7698; Delete from EMP where EMPNO = 7844
 salary Removes employee 7844 from the EMP table Update EMP set SAL = 3000 where EMPNO = 7698; Delete from EMP where EMPNO = 7844")
21
Designing Fields Field – the smallest unit of named application data recognized by system software such as a DBMS Fields map roughly onto attributes in conceptual data models When designing fields, consider: identity data types sizes constraints

22
Data type – A coding scheme recognized by system software for representing organizational data

23
SQL Server Data Types Storage typeData types date and time valuessmalldatetime, datetime integralbit, tinyint, smallint, int, bigint non-whole numbersdecimal, numeric, money, smallmoney, float, real characters and stringschar, varchar, text Unicode characters and strings nchar, nvarchar, ntext Binary stringsbinary, varbinary, image Othercursor, sql_variant, table, timestamp, uniqueidentifier, xml

24
Considerations for Choosing Data Types Balance these four objectives: 1. Minimize storage space 2. Represent all possible values of the field 3. Improve data integrity for the field 4. Support all data manipulations desired for the field

25
Mapping a composite attribute onto multiple fields with various data types

26
Creating and Using Composite Attribute Types

27
Data Integrity Controls Default Values used if no explicit value is entered Format Controls restricts data entry values in specific character positions Range Controls forces values to be among an acceptable set of values Referential Integrity forces foreign keys to align with primary keys Null Value Controls determines whether fields can be empty of value

28
Referential integrity is important for ensuring that data relationships are accurate and consistent

29
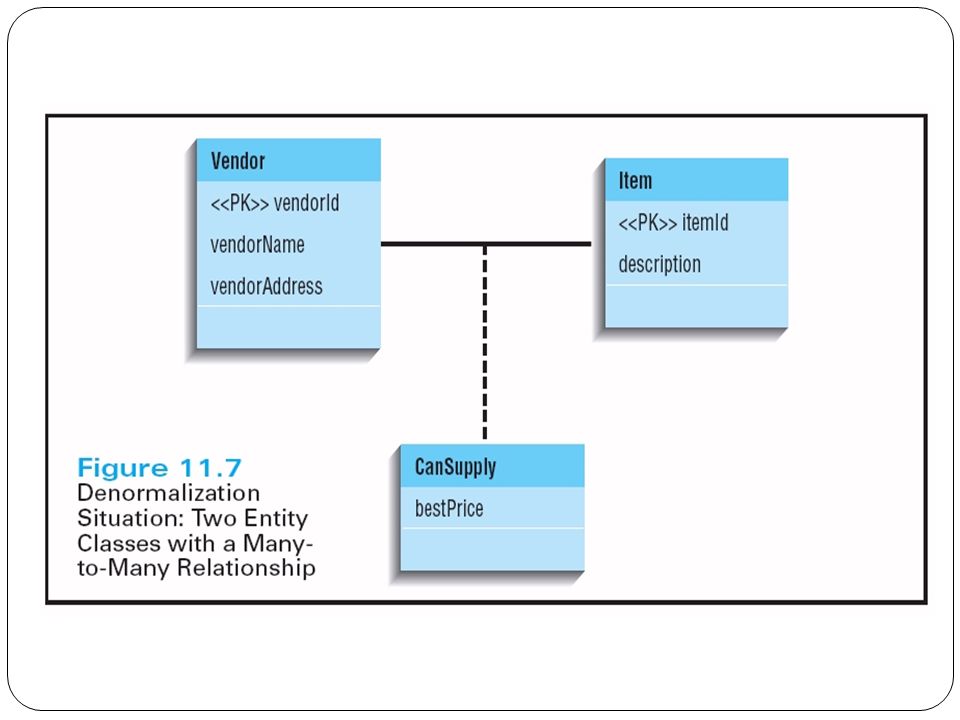
What Is Denormalization? The process of combining normalized relations into physical tables based on affinity of use of rows and fields, and on retrieval and update frequencies on the tables Results in better speed of access, but reduces data integrity and increases data redundancy

30
This will result in null values in several rows’ application data.

32
This will result in duplications of item descriptions in several rows of the CanSupplyDR table.

33
Duplicate regionManager data

34
What Is a File Organization? A technique for physically arranging the row objects of a file Main purpose of file organization is to optimize speed of data access and modification

35
11-35

36
Secondary Storage Concepts Block a unit of data retrieval from secondary storage Extent a set of contiguous blocks Scan a complete read of a file block by block Blocking factor the number of row objects that fit in one block

37
Determining Table Scan Time Block read time is determined by seek, rotation and transfer. Average_table_scan_time = (#rows/blocking_factor) * block_ read_time
 * block_ read_time.")
38
What Is a Heap? A file with no organization Requires full table scan for data retrieval Only use this for small, cacheable tables

39
What Is Hashing? A technique that uses an algorithm to convert a key value to a row address Useful for random access, but not for sequential access

40
What Is an Indexed File Organization? A storage structure involving indexes, which are key values and pointers to row addresses Indexed file organizations are structured to enable fast random and sequential access Index files are fast for queries, but require additional overhead for inserts, deletes, and updates

41
Random Access Processing Using B+ Tree Indexes Indexes are usually implemented as B+ trees These are balanced trees, which preserve a sequential ascending order of items as they are added.

42
Issues to Consider When Selecting a File Organization File size Frequency of data retrievals Frequency of updates Factors related to primary and foreign keys Factors related to non-key attributes

43
Which Fields should be Indexed?

44
Design of Object Relational Features Object-relatonal databases support: Generalization and inheritance Aggregation Multivalued attributes Object identifiers Relationships by reference (pointers)
")
45
Generalization in Oracle 9i/10g

46
Aggregation in Oracle 9i/10g

47
Multivalued Attributes in Oracle 9i/10g

48
Object Identifiers in Oracle 9i/10g

49
SQL Server Object-Relational Features SQL Server 2005SQL Server 2008 Common Language Runtime (CLR) integration Spatial and geographic data types.NET Language Integrated Query (LINQ) Object-Relational Designer
 integration Spatial and geographic data types.NET Language Integrated Query (LINQ) Object-Relational Designer")
Similar presentations





>")





>")
 Domain : A domain is a pool of values appearing in.>")


 Instructor Ms. Arwa.>")



