Download presentation
Presentation is loading. Please wait.

1
Statistical Data Mining - 1 Edward J. Wegman A Short Course for Interface ‘01

2
Outline of Lecture zComplexity zData Mining: What is it? zData Preparation

3
Complexity Descriptor Data Set Size in Bytes Storage Mode Tiny 10 2 Piece of Paper Small 10 4 A Few Pieces of Paper Medium 10 6 A Floppy Disk Large 10 8 Hard Disk Huge 10 10 Multiple Hard Disks e.g. RAID Storage Massive 10 12 Robotic Magnetic Tape Storage Silos The Huber Taxonomy of Data Set Sizes

4
Complexity O(r),O(n 1/2 ) Plot a scatterplot O(n)Calculate means, variances, kernel density estimates O(n log(n))Calculate fast Fourier transforms O(nc)Calculate singular value decomposition of an rc matrix; solve a multiple linear regression O(n 2 )Solve most clustering algorithms. Algorithmic Complexity

5
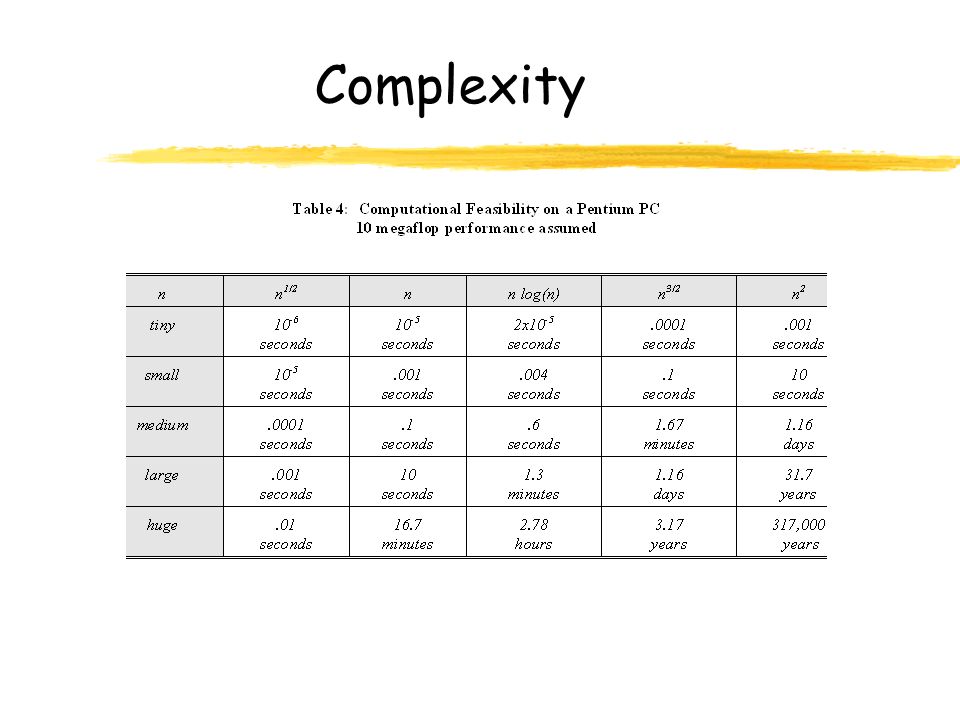
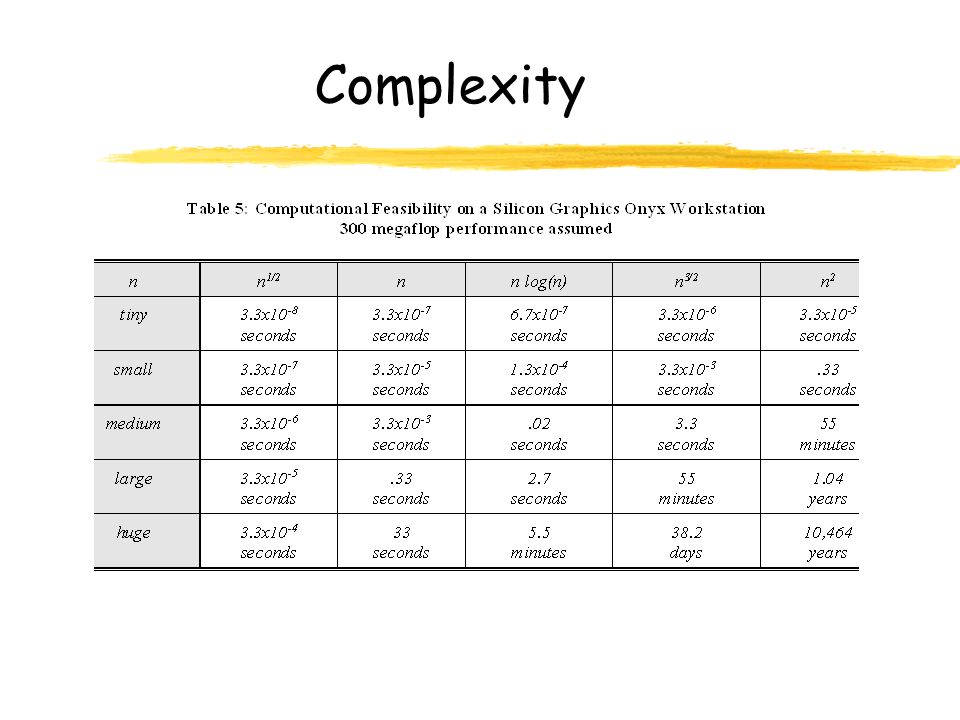
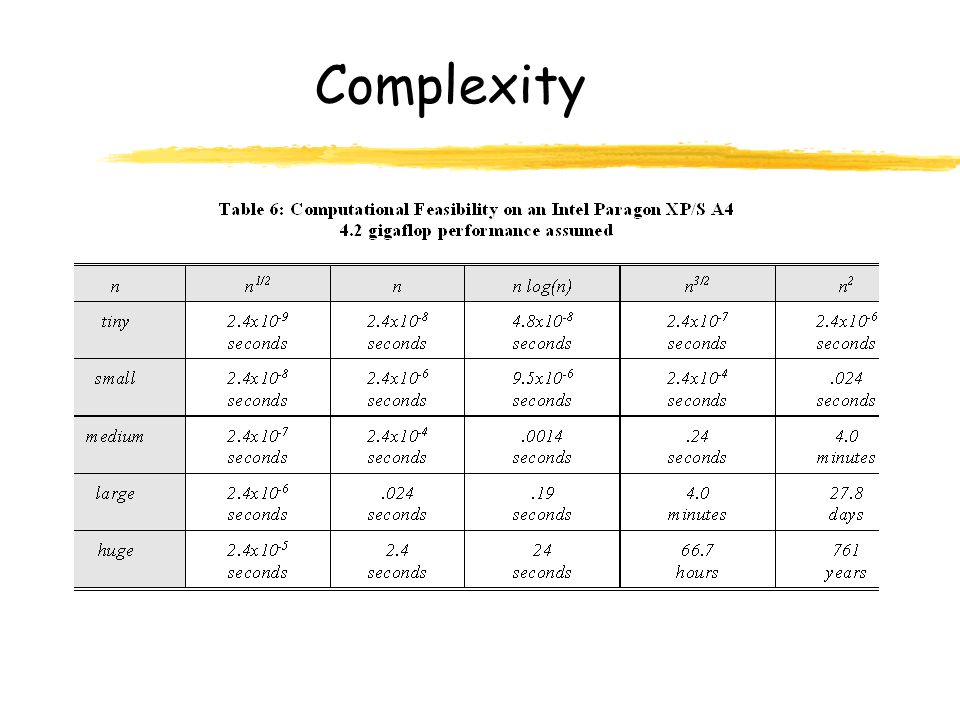
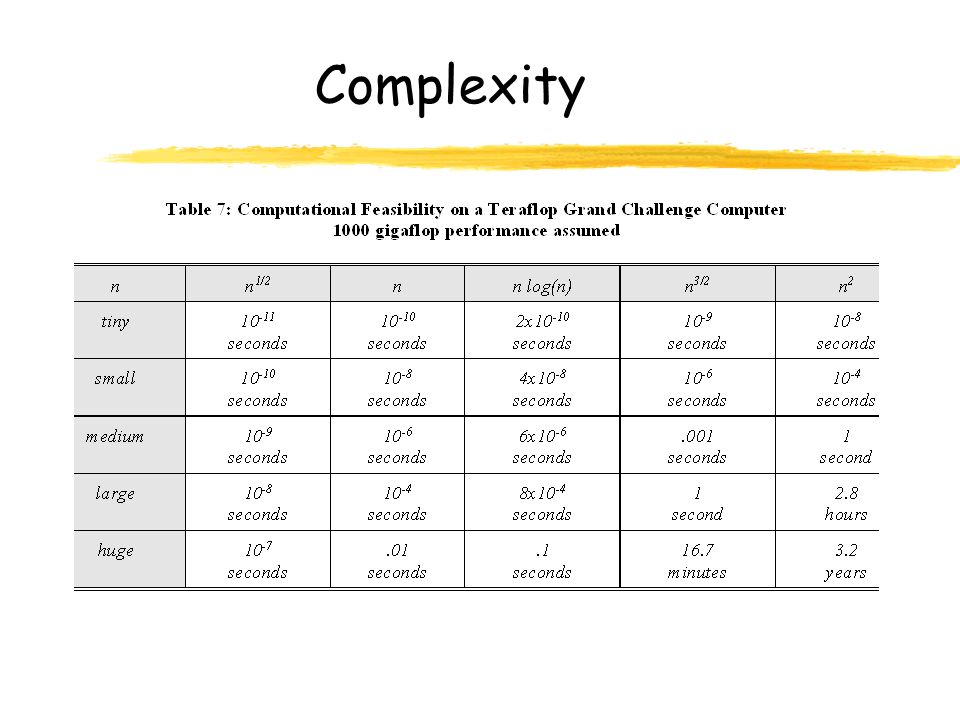
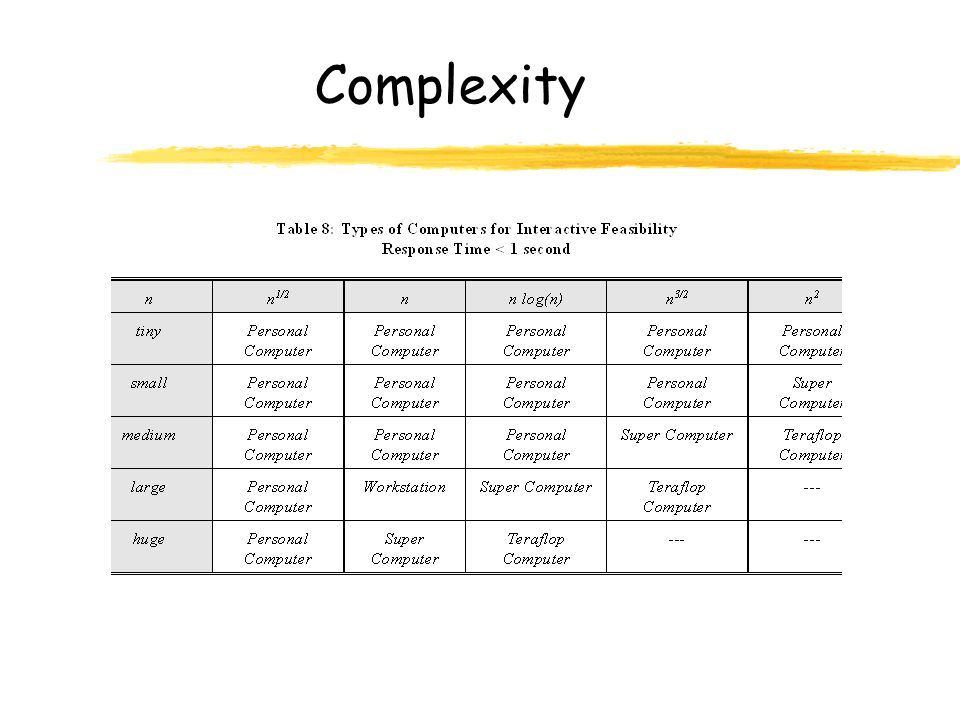
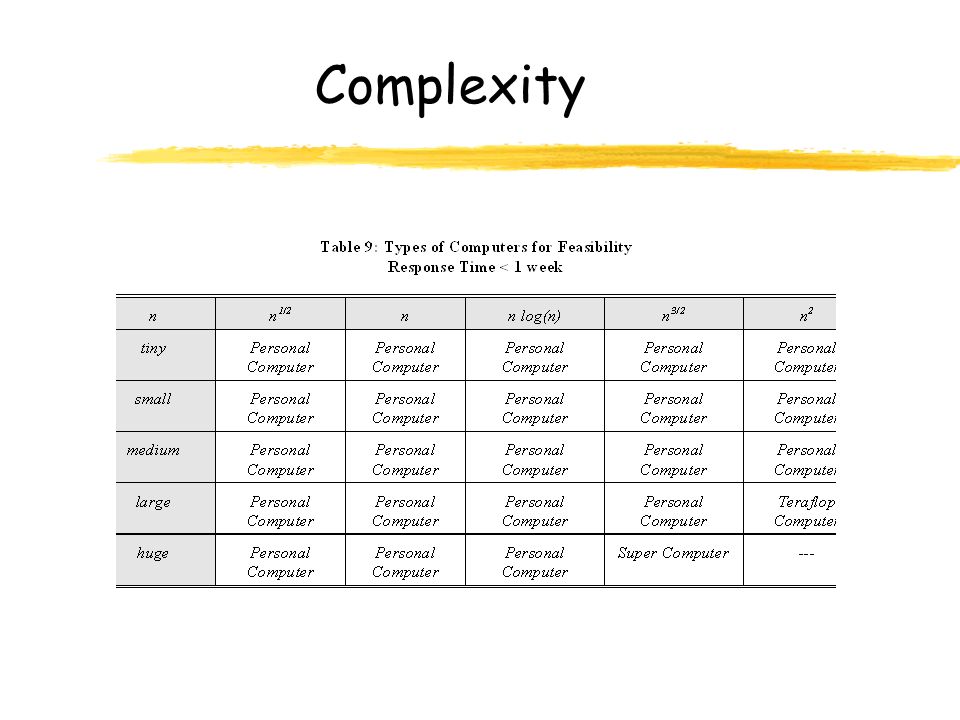
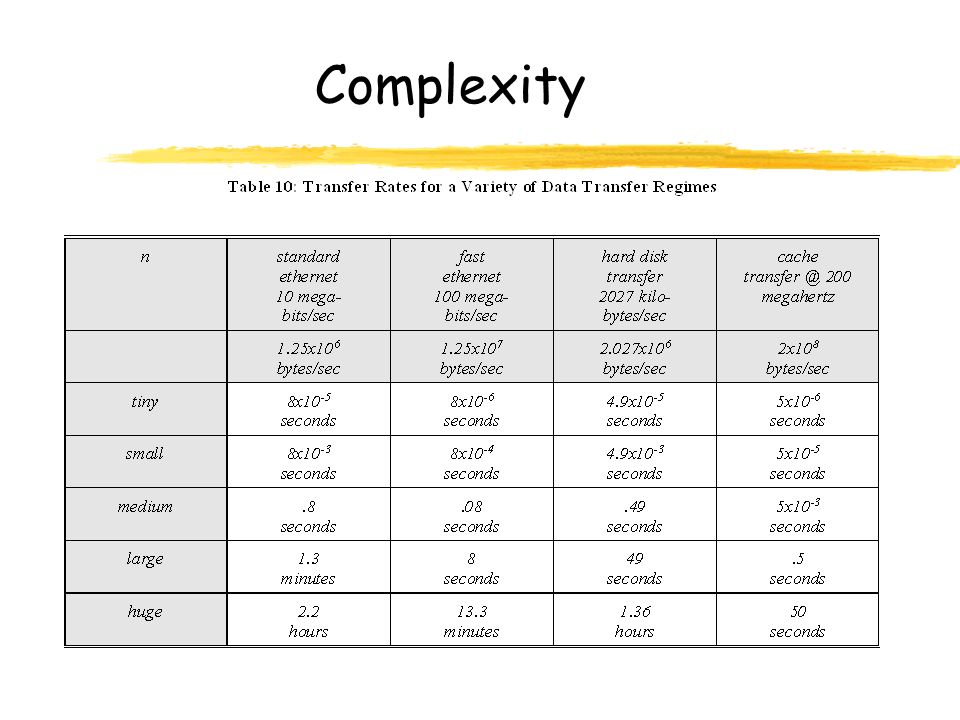
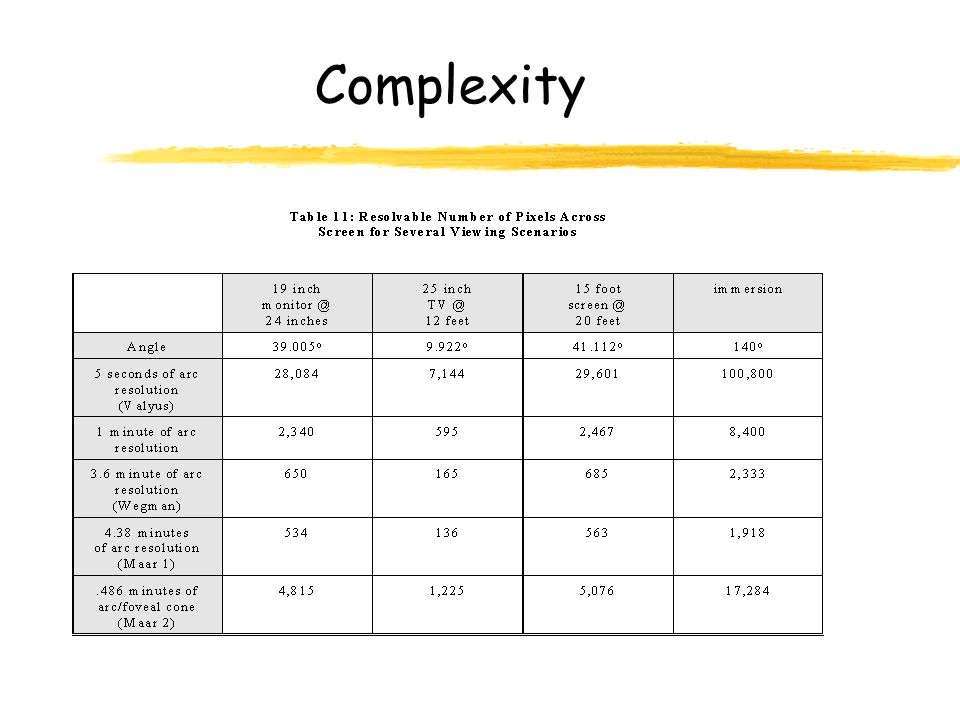
Complexity

14
Scenarios Typical high resolution workstations, 1280x1024 = 1.31x10 6 pixels Realistic using Wegman, immersion, 4:5 aspect ratio, 2333x1866 = 4.35x10 6 pixels Very optimistic using 1 minute arc, immersion, 4:5 aspect ratio, 8400x6720 = 5.65x10 7 pixels Wildly optimistic using Maar(2), immersion, 4:5 aspect ratio, 17,284x13,828 = 2.39x10 8 pixels
, immersion, 4:5 aspect ratio, 17,284x13,828 = 2.39x10 8 pixels")
15
Massive Data Sets One Terabyte Dataset vs One Million Megabyte Data Sets Both difficult to analyze, but for different reasons.

16
Massive Data Sets: Commonly Used Language zData Mining = DM zKnowledge Discovery in Databases = KDD zMassive Data Sets = MD zData Analysis = DA

17
Massive Data Sets

18
Data Mining of Massive Datasets Data Mining is Exploratory Data Analysis with Little or No Human Interaction using Computationally Feasible Techniques, i.e., the Attempt to find Interesting Structure unknown a priori

19
Statistical Data Mining Techniques - Classification - Clustering - Neural Networks & Genetic Algorithms - CART - Nonparametric Regression - Time Series: Trend & Spectral Estimation - Density Estimation, Bumps and Ridges

20
Massive Data Sets zMajor Issues yComplexity yNon-homogeneity zExamples yHuber’s Air Traffic Control yHighway Maintenance yUltrasonic NDE

21
Massive Data Sets zAir Traffic Control y6 to 12 Radar stations, several hundred aircraft, 64-byte record per radar per aircraft per antenna turn ymegabyte of data per minute

22
Massive Data Sets zHighway Maintenance yRecords of maintenance records and measurements of road quality for several decades yRecords of uneven quality yRecords missing

23
Massive Data Sets zNDE using Ultrasound yInspection of cast iron projectiles yTime series of length 256, 360 degrees, 550 levels = 50,688,000 observations per projectile ySeveral thousand projectiles per day

24
Massive Data Sets: A Distinction Human Analysis of the Structure of Data and Pitfalls vs Human Analysis of the Data Itself zLimits of HVS and computational complexity limit the latter zFormer is the basis for design of the analysis engine

25
Massive Data Sets zData Types yExperimental yObservational yOpportunistic z Data Types yNumerical yCategorical yImage

26
Data Preparation

27
0 10 20 30 40 50 60 Objectives Determination Data PreparationData MiningAnalysis & Assimilation Effort (%)
")
28
Data Preparation zData Cleaning and Quality zTypes of Data zCategorical versus Continuous Data zProblem of Missing Data yImputation yMissing Data Plots zProblem of Outliers zDimension Reduction, Quantization, Sampling

29
Data Preparation zQuality yData may not have any statistically significant patterns or relationships yResults may be inconsistent with other data sets yData often of uneven quality, e.g. made up by respondent yOpportunistically collected data may have biases or errors yDiscovered patterns may be too specific or too general to be useful

30
Data Preparation zNoise - Incorrect Values yFaulty data collection instruments, e.g. sensors yTransmission errors, e.g. intermittent errors from satellite or Internet transmissions yData entry problems yTechnology limitations yNaming conventions misused

31
Data Preparation zNoise - Incorrect Classification yHuman judgment yTime varying yUncertainty/Probabilistic nature of data

32
Data Preparation zRedundant/Stale data yVariables have different names in different databases yRaw variable in one database is a derived variable in another yIrrelevant variables destroy speed (dimension reduction needed) yChanges in variable over time not reflected in database
 yChanges in variable over time not reflected in database")
33
Data Preparation zData cleaning zSelecting and appropriate data set and/or sampling strategy zTransformations

34
Data Preparation zData Cleaning yDuplicate removal (tool based) yMissing value imputation (manual, statistical) yIdentify and remove data inconsistencies yIdentify and refresh stale data yCreate unique record (case) ID
 yMissing value imputation (manual, statistical) yIdentify and remove data inconsistencies yIdentify and refresh stale data yCreate unique record (case) ID")
35
Data Preparation zCategorical versus Continuous Data yMost statistical theory, many graphics tools developed for continuous data yMuch of the data if not most data in databases is categorical yComputer science view often takes continuous data into categorical, e.g. salaries categorized as low, medium, high, because more suited to Boolean operations

36
Data Preparation zProblem of Missing Values yMissing values in massive data sets may or may not be a problem xMissing data may be irrelevant to desired result, e.g. cases with missing demographic data may not help if I am trying to create selection mechanism for good customers based on demographics xMassive data sets if acquired by instrumentation may have few missing values anyway xImputation has model assumptions ySuggest making a Missing Value Plot

37
Data Preparation zMissing Value Plot yA plot of variables by cases yMissing values colored red ySpecial case of “color histogram” with binary data y“Color histogram” also known as “data image” yThis example is 67 dimensions by 1000 cases yThis example is also fake

38
Data Preparation zProblem of Outliers yOutliers easy to detect in low dimensions yA high dimensional outlier may not show up in low dimensional projections yMVE or MCD algorithms are exponentially computationally complex yFisher Info Matrix and Convex Hull Peeling more feasible but still too complex for Massive datasets

39
Data Preparation zDatabase Sampling yExhaustive search may not be practically feasible because of their size yThe KDD systems must be able to assist in the selection of appropriate parts if the databases to be examined yFor sampling to work, the data must satisfy certain conditions (not ordered, no systematic biases) ySampling can be very expensive operation especially when the sample is taken from data stored in a DBMS. Sampling 5% of the database can be more expensive that a sequential full scan of the data.

40
Data Compression zOften data preparation involves data compression ySampling yQuantization xSubject of my talk later in the conference. See that talk for more details on this subject.

Similar presentations








>")

 Margaret Dunham Dr. M.H.Dunham, Data Mining,>")








